




下面我将为你实现一个基于物品的协同过滤推荐算法,适用于Java电商平台。这个实现包括核心算法、相似度计算和推荐生成。
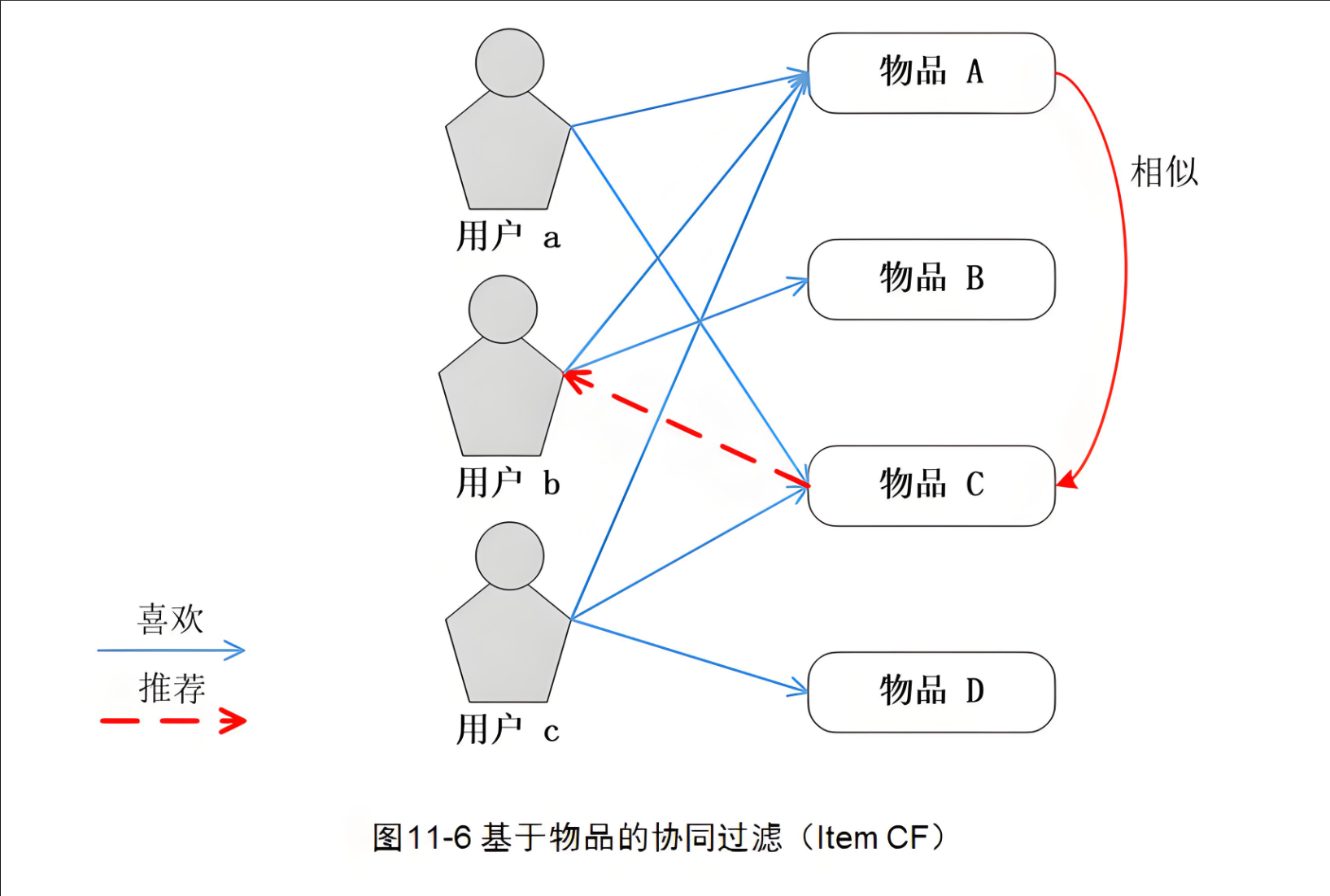
1. 数据模型
首先定义我们需要的数据模型:
public class Item {
private String itemId; // 商品ID
private String name; // 商品名称
// 其他商品属性...
// 构造方法、getter和setter
}
public class User {
private String userId; // 用户ID
private String username; // 用户名
// 其他用户属性...
// 构造方法、getter和setter
}
public class UserBehavior {
private String userId; // 用户ID
private String itemId; // 商品ID
private double preference; // 偏好分数(如评分、购买次数等)
private long timestamp; // 行为时间戳
// 构造方法、getter和setter
}2. 相似度计算
基于物品的协同过滤核心是计算物品之间的相似度:
public class ItemSimilarity {
/**
* 计算物品之间的余弦相似度
* @param itemPrefMap 物品-用户偏好矩阵: Map<itemId, Map<userId, preference>>
* @return 物品相似度矩阵: Map<itemId, Map<itemId, similarity>>
*/
public Map<String, Map<String, Double>> calculateCosineSimilarity(
Map<String, Map<String, Double>> itemPrefMap) {
Map<String, Map<String, Double>> similarityMatrix = new HashMap<>();
// 获取所有物品列表
List<String> itemIds = new ArrayList<>(itemPrefMap.keySet());
// 计算每对物品之间的相似度
for (int i = 0; i < itemIds.size(); i++) {
String itemId1 = itemIds.get(i);
Map<String, Double> userPrefs1 = itemPrefMap.get(itemId1);
// 初始化相似度矩阵
similarityMatrix.put(itemId1, new HashMap<>());
for (int j = i; j < itemIds.size(); j++) {
String itemId2 = itemIds.get(j);
if (itemId1.equals(itemId2)) {
// 相同物品相似度为1
similarityMatrix.get(itemId1).put(itemId2, 1.0);
continue;
}
Map<String, Double> userPrefs2 = itemPrefMap.get(itemId2);
// 计算两个物品的共同用户
Set<String> commonUsers = new HashSet< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1007
1007

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











