



 介绍三种实现二叉树之字形层序遍历的方法:利用队列结合翻转操作、通过ArrayList的重载add函数实现不同方向的插入、采用双端队列进行高效出队与入队。
介绍三种实现二叉树之字形层序遍历的方法:利用队列结合翻转操作、通过ArrayList的重载add函数实现不同方向的插入、采用双端队列进行高效出队与入队。
描述
给定一个二叉树,返回该二叉树的之字形层序遍历,(第一层从左向右,下一层从右向左,一直这样交替)
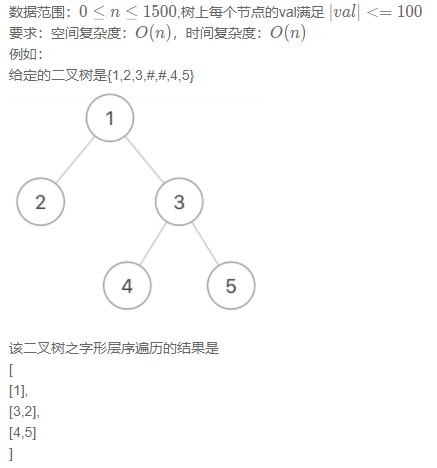
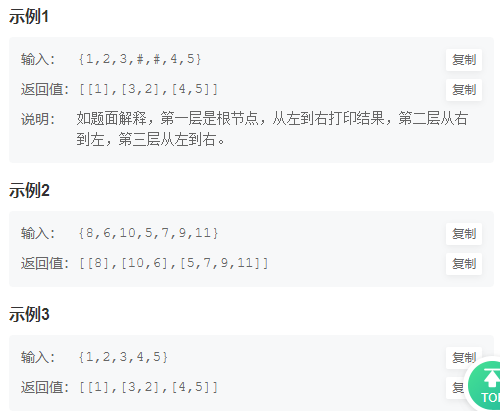
注意:树的初始化
public class TreeNode {
int val = 0;
TreeNode left = null;
TreeNode right = null;
public TreeNode(int val) {
this.val = val;
}
类似:链表的初始化
public class LinkNode {
int val;
LinkNode next = null;
public LinkNode(int val) {
this.val = val;
}
}
方法1:普通队列进行层次遍历,隔层使用一次工具类进行翻转
import java.util.*;
/*
public class TreeNode {
int val = 0;
TreeNode left = null;
TreeNode right = null;
public TreeNode(int val) {
this.val = val;
}
}
*/
public class Solution {
/**
使用队列实现层次遍历(先进先出)
层次遍历判断每一层元素个数不用递归,可以直接看queue的size
**/
public ArrayList<ArrayList<Integer>> Print(TreeNode pRoot) {
ArrayList<ArrayList<Integer>> res = new ArrayList<>();
if(pRoot == null) {
return res;
}
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(pRoot);
int index = 0;
while(!queue.isEmpty()) {
int size = queue.size();
ArrayList<Integer> arr = new ArrayList<>();
for(int i = 0; i < size; i++) {
TreeNode node = queue.poll();
arr.add(node.val);
if(node.left != null) {
queue.offer(node.left);
}
if(node.right != null) {
queue.offer(node.right);
}
}
if(index % 2 != 0) {
Collections.reverse(arr);
}
index++;
res.add(arr);
}
return res;
}
}
注意:队列的初始化是new LinkedList<>();
方法2:使用ArrayList的重载add函数,往前面插入和往后面插入
import java.util.*;
/*
public class TreeNode {
int val = 0;
TreeNode left = null;
TreeNode right = null;
public TreeNode(int val) {
this.val = val;
}
}
*/
public class Solution {
/**
使用队列实现层次遍历(先进先出)
层次遍历判断每一层元素个数不用递归,可以直接看queue的size
左右可以使用双端队列实现
**/
public ArrayList<ArrayList<Integer>> Print(TreeNode pRoot) {
ArrayList<ArrayList<Integer>> res = new ArrayList<>();
if(pRoot == null) {
return res;
}
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(pRoot);
int index = 0;
while(!queue.isEmpty()) {
int size = queue.size();
ArrayList<Integer> arr = new ArrayList<>();
for(int i = 0; i < size; i++) {
TreeNode node = queue.poll();
if(index % 2 == 0) {
arr.add(node.val);
} else {
arr.add(0, node.val);
}
if(node.left != null) {
queue.offer(node.left);
}
if(node.right != null) {
queue.offer(node.right);
}
}
index++;
res.add(arr);
}
return res;
}
}
方法3:使用双端队列,每次从不同的方向出队&入队
import java.util.*;
/*
public class TreeNode {
int val = 0;
TreeNode left = null;
TreeNode right = null;
public TreeNode(int val) {
this.val = val;
}
}
*/
public class Solution {
/**
使用双端队列实现
**/
public ArrayList<ArrayList<Integer> > Print(TreeNode pRoot) {
ArrayList<ArrayList<Integer> > res = new ArrayList<>();
if(pRoot == null) {
return res;
}
Deque<TreeNode> queue = new LinkedList<>();
queue.offer(pRoot);
int index = 0;
while(!queue.isEmpty()) {
int size = queue.size();
ArrayList<Integer> arr = new ArrayList<>();
TreeNode node;
for(int i = 0; i < size; i++) {
if(index % 2 == 0) {
node = queue.pollFirst();
arr.add(node.val);
if(node.left != null) {
queue.offerLast(node.left);
}
if(node.right != null) {
queue.offerLast(node.right);
}
} else {
node = queue.pollLast();
arr.add(node.val);
if(node.right != null) {
queue.offerFirst(node.right);
}
if(node.left != null) {
queue.offerFirst(node.left);
}
}
}
index++;
res.add(arr);
}
return res;
}
}

















 1847
1847

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









