




核心原理与技术特性分析
Kafka作为分布式流处理平台,其设计理念与消息中间件存在本质差异,其消息中间件能力通过发布/订阅模型和Topic支持实现。相较于RabbitMQ等传统消息队列:
- 核心优势:
- 超高吞吐量:支持百万级TPS(如单集群可达200万条/秒)
- 历史数据回溯:基于offset的日志检索机制,允许重复消费历史消息
- 核心局限:
- 消息有序性局限:仅保障单个partition内有序,跨partition不保证FIFO
核心差异体现在下面几个方面:
1 ) 吞吐量优势
Kafka的顺序磁盘I/O读写机制允许每秒处理数十万条消息,远超传统消息队列(如RabbitMQ)
2 ) 消息有序性局限
仅保障单个Partition内的消息顺序,跨Partition时不保证全局有序性(例如订单号A在Partition1,订单号B在Partition2时,消费顺序可能乱序)。
3 ) 历史数据消费能力
基于Offset日志索引机制,消息持久化存储至磁盘,支持重复消费历史数据,而传统消息队列消费后即删除数据。
4 ) 分布式分区架构
通过Topic-Partition机制实现水平扩展,每个Partition都是有序不可变的消息序列
这种设计带来两个关键特性:
- 单个Partition内保证严格的消息顺序性
- 不同Partition间可并行处理(通过Consumer Group机制)
5 ) 持久化日志存储
所有消息以追加写入(append-only)方式持久化到磁盘,并通过分段(segment)存储策略管理数据:
# Kafka日志目录结构示例
topic-order-events-0/
├── 00000000000000000000.index
├── 00000000000000000000.log
├── 00000000000000000000.timeindex
└── 00000000000000000005.snapshot
这种设计使Kafka具备消息回溯能力,消费者可通过调整offset重新消费历史数据
6 ) 技术细节凝练
- 零拷贝(Zero-Copy)技术:通过
sendfile系统调用,数据直接从磁盘缓存(PageCache)传输到网卡缓冲区,跳过用户空间复制,降低CPU开销。 - 批量压缩:Producer端对消息批次(Batch)进行Snappy/GZIP压缩,减少网络传输量。解压操作在Consumer端执行,权衡计算开销与带宽节省。
典型应用场景
| 场景类型 | 技术实现要点 | 规避的缺陷 |
|---|---|---|
| 日志收集 | 分布式服务日志异步写入Topic,由Flink/Spark Streaming实时消费分析 | 避免同步写入的性能瓶颈 |
| 流处理系统 | 前端数据(如用户问卷)→ Kafka → Flink实时处理 → 数据平台 | 解耦数据生产与计算逻辑 |
| 消息系统 | 订单服务推送消息至Topic,业务线并行过滤消费(需容忍局部无序) | 替代强有序场景的RabbitMQ |
| 用户行为跟踪 | 用户浏览事件持久化至Kafka,通过Flink构建实时画像和推荐系统 | 支持TB级行为数据存储 |
| 运营监控 | 双11大屏监控:实时统计指标(如QPS、错误率)并触发流量调度 | 毫秒级延迟保障决策实时性 |
场景选择原则:优先采用Kafka当需求满足:① 高吞吐要求 ② 历史数据复用 ③ 容忍局部无序。强有序场景需选用其他方案
添加场景选择决策树:
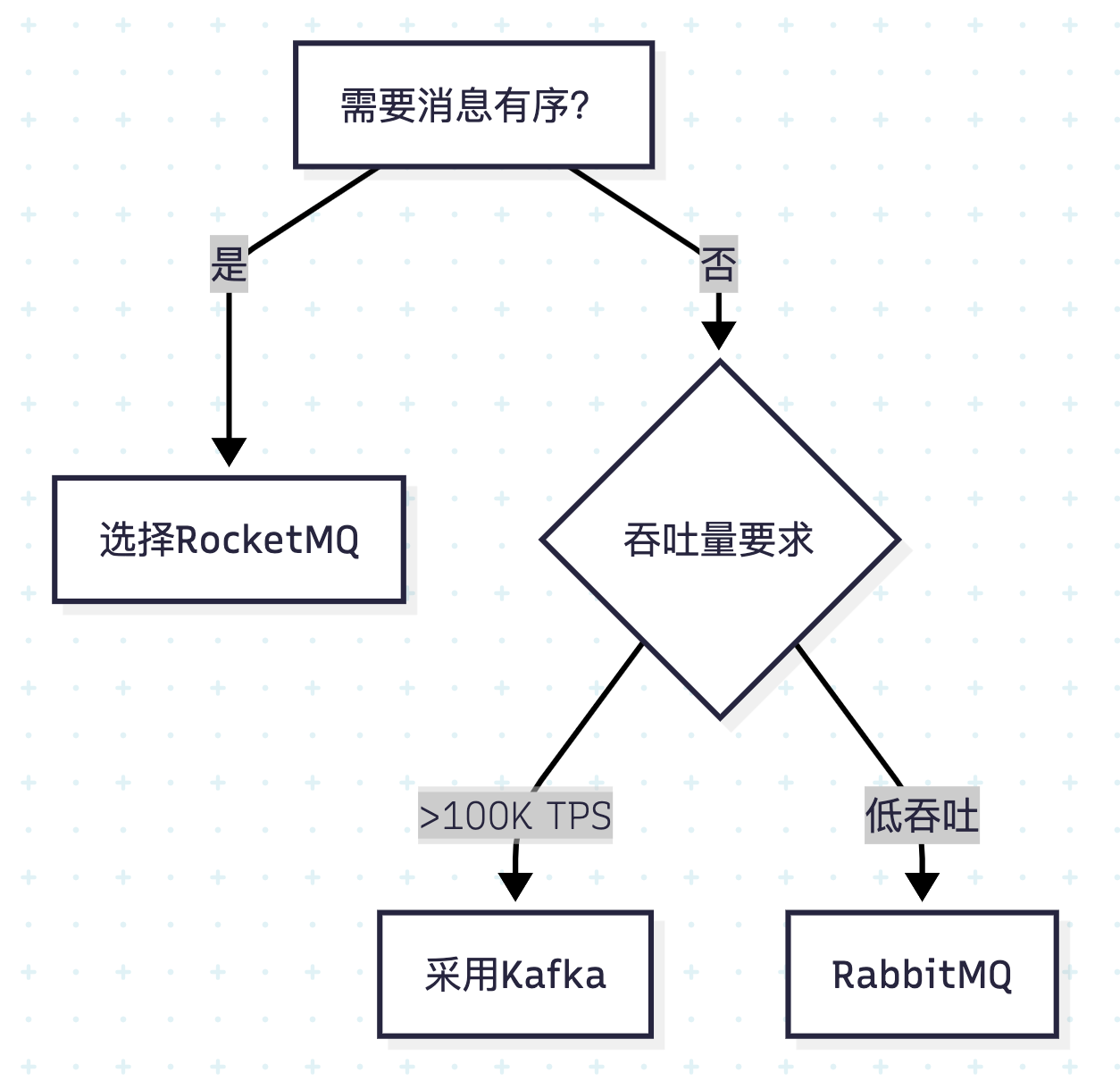
Kafka与其他消息中间件的关键差异
| 特性 | Kafka | 传统MQ(如RabbitMQ) |
|---|---|---|
| 设计定位 | 分布式流处理平台 | 消息队列系统 |
| 吞吐量 | > 100K msg/s | 通常< 50K msg/s |
| 消息有序性 | 仅Partition内有序 | 全局FIFO保证 |
| 数据保留 | 基于日志保留策略(可配置) | 消费后立即删除 |
| 适用场景 | 大数据流处理、日志聚合 | 事务一致性要求高的业务 |
典型应用场景示例:
- 实时日志收集:业务系统日志异步写入Kafka,由Flink/Spark Streaming消费并导入ELK栈。
- 用户行为跟踪:电商平台记录用户浏览事件,通过Kafka推送至推荐系统生成用户画像。
- 运营监控:双十一大促期间,实时统计订单量/错误率,指挥中心动态调整流量分配。
- 异步订单处理:订单服务发布消息至Kafka,库存/支付服务并行消费(需容忍短暂乱序)。
Kafka高吞吐量的五大技术基石
1 ) 顺序磁盘I/O
- 数据追加写入日志文件(append-only log),避免磁盘寻道延迟。
- 通过稀疏索引(Offset Index) 快速定位消息位置,时间复杂度O(1)。
# Kafka日志文件结构示例 topic-partition/ ├── 00000000000000000000.log # 数据文件 └── 00000000000000000000.index # 偏移量索引
2 ) Partition并行机制
- Topic分割为多个Partition,允许Producer/Consumer并行读写。
- 示例:10个Partition的Topic可同时由10个Consumer线程处理。
3 ) 批量生产与消费
- Producer积累消息至批次(默认16KB),减少网络请求次数。
- Consumer通过
poll()批量拉取数据(默认500条/请求)。
4 ) 数据压缩优化
- 压缩算法对比:
- Snappy:低CPU开销,适中压缩比
- GZIP:高压缩比,CPU消耗较高
// Producer端配置压缩 (NestJS示例)
import { ClientKafka, MessagePattern } from '@nestjs/microservices';
const producer = new ClientKafka({
clientId: 'order-service',
brokers: ['kafka-server:9092'],
compression: CompressionTypes.GZIP, // 启用GZIP压缩
});
5 ) 零拷贝技术实现
-
工作流程:
-
通过
sendfile系统调用实现内核空间直接传输,避免用户态数据拷贝:传统IO路径:磁盘 -> 内核缓冲区 -> 用户缓冲区 -> Socket缓冲区 -> 网卡 Kafka零拷贝:磁盘 -> 内核缓冲区 -> 网卡
Kafka与传统消息队列核心差异
| 特性 | Kafka | 传统MQ(RabbitMQ等) |
|---|---|---|
| 消息有序性 | Partition内有序 | 全局有序 |
| 消息保留 | 可配置长期保留(日志策略) | 消费后立即删除 |
| 吞吐量 | 100K+/秒(单节点) | 10K-20K/秒(单节点) |
| 消费模式 | Pull-based | Push-based |
| 数据规模 | TB-PB级 | GB-TB级 |
典型应用场景与技术选型依据
1 ) 实时日志处理系统
架构示例:
应用集群 → Filebeat → Kafka → Logstash → Elasticsearch → Kibana
技术优势:
- 高吞吐特性:轻松处理每秒百万级日志条目
- 缓冲能力:解耦日志生产与消费速率差异
- 数据重放:支持按需重新处理历史日志
2 ) 事件溯源架构
// NestJS实现订单事件生产者
import { Controller, Post } from '@nestjs/common';
import { EventPattern, MessagePattern } from '@nestjs/microservices';
import { KafkaService } from './kafka.service';
@Controller('orders')
export class OrderController {
constructor(private readonly kafkaService: KafkaService) {}
@Post()
async createOrder() {
const event = {
id: uuidv4(),
type: 'ORDER_CREATED',
payload: { /* 订单数据 */ }
};
// 发送到orders主题
await this.kafkaService.send('orders', event);
}
}
3 ) 实时监控告警系统
数据处理流程:
监控指标采集 → Kafka → Flink实时计算 → 异常检测 → 告警通知
核心价值:
- 秒级延迟的指标分析
- 动态阈值检测
- 历史异常回溯分析
吞吐量优化核心机制
1 ) 顺序磁盘I/O
- 追加写入(append-only) 避免磁头寻道时间
- 预读(read-ahead)/写聚集(write-behind) 优化磁盘操作
2 )批量处理优化
生产者配置示例:
// NestJS生产者配置
const producerConfig: ProducerConfig = {
acks: 1,
compression: CompressionTypes.GZIP,
batchSize: 16384, // 16KB批次大小
lingerMs: 5, // 最大等待时间
};
3 )高效数据传输
零拷贝实现原理:
// Linux系统调用实现
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
工程示例:1
1 ) 方案1:基础生产者-消费者模型
// 1. 安装依赖:npm install @nestjs/microservices kafkajs
import { Module } from '@nestjs/common';
import { ClientsModule, Transport } from '@nestjs/microservices';
@Module({
imports: [
ClientsModule.register([
{
name: 'ORDER_SERVICE',
transport: Transport.KAFKA,
options: {
client: {
brokers: ['localhost:9092'],
},
consumer: {
groupId: 'order-consumer-group',
allowAutoTopicCreation: true,
},
},
},
]),
],
})
export class AppModule {}
// 生产者服务
import { Controller, Inject } from '@nestjs/common';
import { ClientKafka, EventPattern } from '@nestjs/microservices';
@Controller()
export class OrderController {
constructor(@Inject('ORDER_SERVICE') private client: ClientKafka) {}
async createOrder() {
this.client.emit('order_created', { id: 1, amount: 100 });
}
}
// 消费者服务
@Controller()
export class PaymentController {
@EventPattern('order_created')
handle console.log('Processing payment:', data);
}
}
2 ) 方案2:分区策略与消息顺序保障
// 配置分区路由策略
const producer = new ClientKafka({
brokers: ['kafka-server:9092'],
createPartitioner: Partitioners.LegacyPartitioner, // 按key哈希分区
});
// 发送带Key的消息确保同一订单进入相同Partition
this.client.emit('order_events', {
key: 'order_123', // 相同Key路由到同一Partition
value: JSON.stringify({ status: 'paid' }),
});
// 消费者组内单Partition独占消费
consumer.subscribe({ topic: 'order_events', fromBeginning: true });
consumer.run({
eachMessage: async ({ partition, message }) => {
// 同一partition内消息有序
},
});
3 ) 方案3:高可用与容错配置
// Kafka集群配置 (3节点示例)
const producer = new ClientKafka({
brokers: [
'kafka-node1:9092',
'kafka-node2:9092',
'kafka-node3:9092'
],
retry: {
retries: 5, // 生产者重试次数
},
});
// 消费者事务处理
@EventPattern('payment_events')
async handlePayment(data: any) {
try {
await db.transaction(() => {
// 1. 扣减库存
// 2. 生成财务记录
});
this.client.emit('payment_success', data);
} catch (error) {
this.client.emit('payment_failed', data); // 死信队列处理
}
}
// 监控配置 (Prometheus + Grafana)
import { KafkaJSPrometheusExporter } from 'kafkajs-prometheus-exporter';
const exporter = new KafkaJSPrometheusExporter(producer);
exporter.startMetricsCollection();
工程示例:2
1 ) 方案1:基础生产者-消费者实现
// kafka.module.ts
import { Module } from '@nestjs/common';
import { ClientsModule, Transport } from '@nestjs/microservices';
@Module({
imports: [
ClientsModule.register([
{
name: 'ORDER_SERVICE',
transport: Transport.KAFKA,
options: {
client: {
brokers: ['kafka1:9092', 'kafka2:9092'],
},
consumer: {
groupId: 'order-consumer',
}
},
},
]),
],
providers: [OrderService],
exports: [OrderService]
})
export class KafkaModule {}
// order.service.ts
import { Injectable, Inject } from '@nestjs/common';
import { ClientKafka } from '@nestjs/microservices';
@Injectable()
export class OrderService {
constructor(
@Inject('ORDER_SERVICE') private readonly kafkaClient: ClientKafka
) {}
async publishOrderEvent(eventType: string, payload: any) {
this.kafkaClient.emit('order_events', {
key: payload.id,
value: JSON.stringify({ type: eventType, payload })
});
}
}
2 ) 方案2:分区键路由策略
// 生产者端分区路由
async publishPartitionedEvent() {
const order = { id: '123', userId: 'user_789' };
// 按用户ID路由到特定分区
await this.kafkaClient.emit('user_events', {
key: order.userId,
value: order,
partition: hash(order.userId) % 3 // 3个分区
});
}
// 消费者端分区分配
@EventPattern('user_events')
async handleUserEvent(
@Payload() message: { key: string, value: any },
@Ctx() context: KafkaContext
) {
const partition = context.getPartition();
console.log(`Processing partition ${partition} for user ${message.key}`);
// 分区内顺序处理
}
3 ) 方案3:死信队列(DLQ)处理
// dlq.consumer.ts
@Consumer('order_events')
export class OrderConsumer {
constructor(
private readonly dlqService: DlqService
) {}
@EventPattern('order_events')
async handleOrderEvent(@Payload() message: any) {
try {
// 业务处理
} catch (error) {
// 发送到DLQ主题
await this.dlqService.sendToDLQ({
originalTopic: 'order_events',
originalMessage: message,
error: error.message
});
}
}
}
// dlq.module.ts 配置
const dlqConfig: ConsumerConfig = {
groupId: 'dlq-processor',
topics: ['dlq_topic'],
fromBeginning: true,
autoCommit: false
};
工程示例:3
1 ) 方案1:基础生产者-消费者模型
// 生产者模块 (producer.module.ts)
import { Module } from '@nestjs/common';
import { ClientsModule, Transport } from '@nestjs/microservices';
@Module({
imports: [
ClientsModule.register([
{
name: 'ORDER_SERVICE',
transport: Transport.KAFKA,
options: {
client: {
brokers: ['kafka:9092'],
},
producer: {
allowAutoTopicCreation: true,
}
},
},
]),
],
providers: [OrderService],
})
export class ProducerModule {}
// 消费者服务 (order.service.ts)
import { Inject, Injectable } from '@nestjs/common';
import { ClientKafka } from '@nestjs/microservices';
@Injectable()
export class OrderService {
constructor(@Inject('ORDER_SERVICE') private client: ClientKafka) {}
async createOrder(orderData: any) {
this.client.emit('orders', JSON.stringify(orderData)); // 异步发送
}
}
2 ) 方案2:事务消息保障
// 事务生产者配置
import { TransactionalProducer } from 'kafkajs-transactions';
const transactionalProducer = new TransactionalProducer(kafka.producer(), {
transactionalId: 'order-tx-producer',
maxInFlightRequests: 1,
});
await transactionalProducer.send({
topic: 'orders',
messages: [{ value: 'Order data' }],
transaction: true // 启用事务
});
// NestJS集成事务监听器
@EventPattern('order.created')
async) {
await this.entityManager.transaction(async (txManager) => {
await txManager.save(OrderEntity, data);
this.client.emit('inventory_update', data); // 事务内发送
});
}
3 ) 方案3:流处理集成
// 使用kafkajs-stream处理实时流
import { KafkaStreams } from 'kafkajs-streams';
const streams = new KafkaStreams({ kafka });
const stream = streams.getKStream('user_events');
stream
.filter(msg => msg.value.eventType === 'click')
.map(msg => ({ ...msg, value: JSON.parse(msg.value) }))
.to('user_clicks_processed');
// NestJS微服务流控制器
@Controller('stream')
export class StreamController {
@MessagePattern('user_clicks_processed')
async processClicks(@Payload() data) {
await this.analyticsService.updateRealTimeDashboard(data);
}
}
Kafka运维命令补充
# 创建Topic(3分区2副本)
kafka-topics --create --topic order_events \
--partitions 3 --replication-factor 2 \
--bootstrap-server kafka-server:9092
# 查看消费者组偏移量
kafka-consumer-groups --describe --group order-consumer-group \
--bootstrap-server kafka-server:9092
生产环境关键配置
1 ) Kafka服务端核心配置
server.properties
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
log.retention.hours=168
log.segment.bytes=1073741824
2 ) 消费者位移管理
// 手动提交offset示例
@Consumer('inventory_updates')
export class InventoryConsumer {
@EventPattern('inventory_updates')
async processMessage(
@Payload() message: any,
@Ctx() context: KafkaContext
) {
const partition = context.getPartition();
const offset = message.offset;
try {
// 业务处理
await context.getConsumer().commitOffsets([{
topic: 'inventory_updates',
partition,
offset: offset + 1
}]);
} catch (error) {
// 错误处理
}
}
}
性能优化实践
1 ) 数据压缩策略选择
// 生产者压缩配置
const producer = new Producer({
'compression.type': 'snappy', // GZIP/LZ4/Snappy
'batch.size': 32768
});
2 ) 消费者并行度优化
# 计算理想消费者实例数
分区总数 / max(1, 每个实例处理分区数)
3 ) JVM调优参数
# kafka-server-start.sh
export KAFKA_HEAP_OPTS="-Xmx6G -Xms6G"
export KAFKA_JVM_PERFORMANCE_OPTS="-server -XX:MetaspaceSize=96m -XX:+UseG1GC"
监控与运维体系
1 ) 关键监控指标
| 类别 | 指标 | 报警阈值 |
|---|---|---|
| Broker | UnderReplicatedPartitions | >0 |
| Topic | MessagesInPerSec | >分区数*写入上限 |
| 消费 | ConsumerLag | >10000 |
2 ) 常用运维命令
# 创建含3分区Topic
kafka-topics.sh --create --bootstrap-server localhost:9092 \
--topic order_events --partitions 3 --replication-factor 2
# 查看消费者组位移
kafka-consumer-groups.sh --bootstrap-server localhost:9092 \
--group order-processor --describe
# 生产压测(10万条消息)
kafka-producer-perf-test.sh --topic test \
--num-records 100000 --record-size 1000 \
--throughput -1 --producer-props bootstrap.servers=localhost:9092
架构设计启示:
Kafka的高吞吐能力源于其架构级的系统优化,包括顺序I/O、零拷贝传输、批量处理和分区并发机制。
在实际应用中需根据消息有序性要求、数据保留策略和吞吐量需求进行技术选型,对于需要严格顺序保证的场景可采用分区键路由策略,对于数据可靠性要求高的场景应配置ISR副本机制。
吞吐量优化机制深度解析
Kafka的高吞吐源于五项协同设计:
1 ) 日志顺序读写
- 物理存储优化:消息按partition顺序追加日志文件,规避磁盘随机I/O瓶颈
- 快速检索:通过稀疏索引(.index文件) 实现O(1)时间复杂度的offset定位
2 ) Partition并行机制
- 单个Topic拆分为多个partition,producer/consumer可并行读写
- 示例:10-partition Topic理论吞吐提升10倍
3 ) 批量传输策略
- Producer端:消息缓存至
RecordAccumulator,按时间/大小阈值批量发送
// NestJS Producer配置(kafkajs)
import { Producer, Kafka } from 'kafkajs';
const kafka = new Kafka({ brokers: ['localhost:9092'] });
const producer = kafka.producer({
batch: {
size: 16384, // 16KB批量大小阈值
lingerMs: 50 // 最大等待50ms
}
});
4 ) 数据压缩优化
- 支持gzip/snappy/lz4压缩算法,降低网络传输开销
- 批量压缩准则:仅当批量消息>1KB时启用,避免单条压缩负优化
5 ) 零拷贝(Zero-Copy)技术
- 内核层优化:通过
sendfile()系统调用,数据直接从PageCache传输到网卡 - 规避传统流程:磁盘→内核缓冲区→用户空间→Socket缓冲区的多次拷贝
性能数据:零拷贝使吞吐量提升300%,延迟降低70%(对比传统复制机制)
常见问题规避与最佳实践
1 ) 消息乱序场景:
- 问题:用户注册事件(A)和订单创建事件(B)可能因跨Partition乱序
- 方案:使用业务主键(如userId)作为消息Key,确保关联事件进入同一Partition
2 ) 数据丢失防护:
- Producer端启用
acks=all:要求所有副本确认写入 - Consumer端手动提交Offset:避免自动提交导致消息丢失
consumer.run({
autoCommit: false, // 关闭自动提交
eachMessage: async ({ topic, partition, message }) => {
processMessage(message);
await consumer.commitOffsets([{ topic, partition, offset: message.offset }]);
},
});
3 ) 资源隔离策略:
- 为不同业务线分配独立Cluster(如Log-Cluster vs Order-Cluster)
- 使用Quota限制生产/消费速率:
kafka-configs --alter --add-config 'producer_byte_rate=102400' \ --entity-type clients --entity-name app-service \ --bootstrap-server kafka-server:9092
Kafka周边配置要点
| 配置项 | NestJS实现方式 | 生产环境建议值 |
|---|---|---|
| Topic分区策略 | createPartitions() API动态扩展分区 | 分区数=消费者实例数×2 |
| 消息持久化 | log.retention.hours=168(7天保留) | 根据存储成本调整 |
| Consumer负载均衡 | @nestjs/microservices自动Rebalance | 启用autoCommit: false |
| 监控集成 | Prometheus + Grafana监控Lag | 设置Lag>1000告警 |
技术决策指导原则
1 ) 吞吐量优先场景:
- 采用批量压缩+零拷贝组合,消息大小>1KB时启用snappy压缩
- 分区数设置公式:
目标TPS / 单分区吞吐能力(基准测试确定)
2 ) 数据一致性保障:
- 关键业务使用事务消息+幂等producer(
enableIdempotence=true) - 替代方案:RocketMQ的顺序消息模型(需NestJS自定义适配)
3 ) 资源优化建议:
- Broker配置:
num.io.threads=CPU核心数×2 - JVM堆内存:不超过32GB(避免GC停顿)
架构启示:Kafka的日志存储设计是其区别于MQ的本质——不是"消息队列"而是分布式提交日志系统。这解释了其吞吐/回溯能力与有序性局限的根源。
总结与扩展知识
Kafka的核心价值在于高吞吐分布式流处理能力,而非传统消息队列的事务保障。在NestJS生态中,通过@nestjs/microservices集成Kafka,需重点关注:
- 消息语义选择:at-least-once(至少一次) vs exactly-once(精确一次)
- 水平扩展策略:基于Partition数的Consumer组扩容上限
- 生态工具链:
- Kafka Connect:与数据库/数据湖集成
- KSQL:流式SQL处理
- Schema Registry:Avro协议管理
初学者提示:
- Partition:Topic的物理分片,决定并行度上限
- Offset:消息在Partition内的唯一位置标识符
- Consumer Group:组内消费者协同分配Partition,实现负载均衡
通过本文技术方案,可构建支撑百万级TPS的实时数据管道,同时规避消息乱序与数据丢失风险。


















 1214
1214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











