




聚合分析的本质与价值
聚合分析(Aggregation) 是 Elasticsearch 的实时统计分析引擎,通过对分布式数据执行多维计算,返回归纳性统计结果而非原始文档,计算聚合指标(如计数、平均值、百分位数)或数据分组统计(如分桶、直方图)
传统实现痛点,若在客户端手动实现聚合(如先查询原始数据再代码处理),面临三大瓶颈:
- 网络带宽浪费:需传输海量原始文档
- 计算资源开销:消耗应用服务器 CPU/内存
- 开发效率低下:每个需求需单独编码实现
与传统搜索的核心差异:
| 搜索场景 | 聚合场景 | 本质差异 |
|---|---|---|
| 查询上海地区所有订单 | 统计最近一周每日订单成交量 | 返回聚合结果 vs 文档列表 |
| 检索未付款订单 | 计算最近一月日均订单金额 | 衍生指标 vs 原始数据 |
| 关键词匹配商品 | 获取半年内销量 Top 5 商品 | 跨文档统计 vs 单文档检索 |
典型场景对比:
- 搜索功能(返回文档列表)
- 示例:
查询地址为上海的所有订单 - 输出:订单详情列表
- 示例:
- 聚合分析(返回统计结果)
- 示例1:
统计最近一周每天的订单成交量→ 输出每日订单数(非订单列表) - 示例2:
计算最近一个月每天的平均订单金额→ 输出每日均值(非订单详情) - 示例3:
获取最近半年销量前五的商品→ 输出商品ID与销量(非订单列表)
- 示例1:
技术痛点与传统方案局限:
聚合分析通过计算下推将运算移至数据节点,性能提升可达10-100倍
核心价值:
- 实时性:毫秒级响应(对比 Hadoop T+1 延迟)
- 功能完备:支持分桶/指标/管道三维分析模型
- 避免资源浪费:减少网络传输与客户端计算负载
聚合分析技术体系
| 类型 | 规则 | 示例场景 |
|---|---|---|
terms | 按词项分组(如岗位类型) | 岗位分布统计 |
range | 数值范围分组(如工资区间) | 薪资区间分布 |
date_range | 日期范围分组 | 员工出生年代分布 |
histogram | 固定间隔数值直方图 | 每5000元工资区间统计 |
date_histogram | 固定时间间隔直方图 | 每年入职人数统计 |
1 ) API 基础结构
GET /index/_search {
"size": 0, // 禁止返回原始文档
"aggs": { // 聚合入口
"analysis_name": { // 自定义结果标识
"terms": { // 聚合类型
"field": "job.keyword", // 目标字段
"size": 5 // 参数配置
},
"aggs": { // 子聚合嵌套
"avg_salary": { "avg": { "field": "salary" } }
}
}
}
}
或
GET /index/_search
{
"size": 0, // 不返回原始文档
"aggs": { // 聚合入口(aggregations 缩写)
"analysis_name": { // 自定义分析命名(影响返回结构)
"analysis_type": { // 聚合类型(terms/range/histogram...)
"field": "price", // 目标字段
"interval": 5000 // 类型相关参数
},
"aggs": { // 子聚合定义(嵌套分析)
"sub_analysis": {...}
}
}
}
}
关键参数:
extended_bounds:强制包含空桶(如薪资 0-4 万每 5000 分段)- 文本字段需启用限 keyword 类型避免分词干扰)
关键特性:
- 多级聚合:支持父子层级嵌套(如先按岗位分桶,再对桶内数据计算平均薪资)
- 结果结构:聚合结果以
aggregations.aggregation_name.buckets形式返回
- 示例:岗位分布统计
GET /employees/_search { "size": 0, "aggs": { "jobs_distribution": { // 聚合名称 "terms": { // 分桶类型:按词项分组 "field": "job.keyword", // 对job字段分桶(需keyword类型避免分词) "size": 5 // 返回前5个分组 } } } }
-
返回结果:
{ "aggregations": { "jobs_distribution": { "buckets": [ { "key": "ruby_engineer", "doc_count": 2 }, { "key": "web_engineer", "doc_count": 2 }, ... ] } } } -
关键点:使用
keyword类型字段避免分词干扰,确保分桶准确性
- Range分组(工资区间):
"aggs": {
"salary_ranges": {
"range": {
"field": "salary",
"ranges": [
{ "to": 10000, "key": "低级" }, // 自定义key
{ "from": 10000, "to": 20000 },
{ "from": 20000, "key": "高级" }
]
}
}
}
- Date Histogram(按年统计):
"aggs": {
"join_date_histo": {
"date_histogram": {
"field": "join_date",
"calendar_interval": "year", // 年间隔
"format": "yyyy" // 返回格式
}
}
}
- 直方图扩展边界(补全空桶):
"histogram": { "field": "salary", "interval": 5000, "extended_bounds": { "min": 0, "max": 40000 } // 强制生成0-4w区间 }
2 ) 聚合类型全景图
| 类型 | 功能 | 核心方法 | SQL类比 |
|---|---|---|---|
| Metric | 指标计算 | min, max, avg, sum | 聚合函数 |
| Bucket | 文档分桶 | terms, range, histogram | GROUP BY |
| Pipeline | 聚合结果再处理 | avg_bucket, derivative | 窗口函数 |
| Matrix | 多字段交叉分析 | matrix_stats | 相关矩阵 |
3 ) Metric 聚合技术栈
| 类型 | 功能 | 示例字段 | 示例场景 |
|---|---|---|---|
min | 最小值 | age | 最低商品价格 |
max | 最大值 | salary | 最高订单金额 |
avg | 平均值 | price | 日均销售额 |
sum | 求和 | amount | 季度总营收 |
cardinality | 基数(去重计数) | user_id | 独立访客数(UV) |
查询示例:
{
"aggs": {
"min_age": { "min": { "field": "age" } },
"max_age": { "max": { "field": "age" } },
"avg_salary": { "avg": { "field": "salary" } }
}
}
返回结果:
"aggregations": {
"min_age": { "value": 18 },
"max_age": { "value": 28 },
"avg_salary": { "value": 13500 }
}
3.1 单值分析(输出单个数值):
"aggs": {
"min_age": { "min": { "field": "age" } }, // 最小值
"unique_users": { // 基数统计
"cardinality": {
"field": "user_id",
"precision_threshold": 1000 // 精度控制
}
}
}
基础计算类型:
// 嵌套在 aggs 中的单值分析配置
"aggs": {
"min_age": { "min": { "field": "age" } }, // 最小值
"max_salary": { "max": { "field": "salary" } },// 最大值
"avg_price": { "avg": { "field": "price" } }, // 平均值
"total_sales": { "sum": { "field": "sales" } } // 总和
}
基数统计(Cardinality):
"unique_jobs": {
"cardinality": {
"field": "job.keyword", // 需精确字段
"precision_threshold": 1000 // 精度控制
}
}
3.2 多值分析(输出复合统计值):
| 类型 | 功能 |
|---|---|
stats | 一次性返回min/max/avg/sum/count |
extended_stats | 扩展统计(方差、标准差等) |
percentiles | 百分位数(如P95响应时间) |
percentile_ranks | 数值在分布中的排名(如工资排名) |
top_hits | 返回桶内按规则排序的原始文档 |
"response_time_analysis": {
"percentiles": { // 百分位分析
"field": "response_time_ms",
"percents": [95, 99, 99.9] // P95/P99/P99.9
},
"top_hits": { // 桶内文档获取
"size": 3,
"sort": [{ "timestamp": "desc" }]
}
}
或
{
"aggs": {
"salary_percentiles": {
"percentiles": {
"field": "salary",
"percents": [95, 99] // 计算 P95 和 P99
}
}
}
}
应用场景:验证SLA(如95%请求响应时间≤200ms)
统计概览(Stats):
"salary_stats": {
"stats": {
"field": "salary" // 返回 min/max/avg/sum/count
}
}
百分位分析(Percentiles):
"response_time_percentiles": {
"percentiles": {
"field": "response_time_ms",
"percents": [95, 99, 99.9] // 自定义百分位
}
}
// KPI 场景:95% 请求响应时间 < 200ms
Top Hits示例(分桶后获取详情):
"aggs": {
"job_buckets": {
"terms": { "field": "job.keyword" },
"aggs": {
"top_employees": { // 子聚合
"top_hits": {
"size": 3, // 返回每个岗位前3人
"sort": [{ "age": { "order": "desc" } }] // 按年龄降序
}
}
}
}
}
4 ) Bucket 聚合分桶策略
术语分桶(Terms):
"job_distribution": {
"terms": {
"field": "job.keyword", // 需keyword类型
"size": 10, // 返回桶数
"missing": "N/A" // 空值处理
}
}
时空分桶(Date/Histogram):
"sales_trend": {
"date_histogram": { // 时间直方图
"field": "order_date",
"calendar_interval": "day",
"format": "yyyy-MM-dd"
},
"aggs": {
"daily_stats": { // 嵌套指标
"stats": { "field": "amount" }
}
}
}
范围分桶(Range):
"salary_distribution": {
"range": {
"field": "salary",
"ranges": [
{ "key": "初级", "to": 10000 }, // 自定义 key
{ "from": 10000, "to": 20000 },
{ "key": "高级", "from": 20000 }
]
}
}
5 ) 时间与直方图分析
日期直方图(Date Histogram):
"birthday_distribution": {
"date_histogram": {
"field": "birth_date",
"calendar_interval": "year", // 支持 month/day
"format": "yyyy",
"min_doc_count": 0 // 显示空桶
}
}
数值直方图(Histogram):
"salary_histogram": {
"histogram": {
"field": "salary",
"interval": 5000,
"extended_bounds": { // 强制显示空桶
"min": 0,
"max": 40000
}
}
}
6 ) 组合聚合:工业级分析范式
三层嵌套分析模型:
"aggs": {
"departments": { // 一级分桶(部门)
"terms": { "field": "dept.keyword" },
"aggs": {
"salary_ranges": { // 二级分桶(薪资区间)
"range": {
"field": "salary",
"ranges": [{"to": 10000}, {"from": 10000}]
},
"aggs": {
"age_stats": { // 三级指标(年龄统计)
"stats": { "field": "age" }
}
}
}
}
}
}
可视化映射:Kibana “嵌套饼图”即基于此实现
组合使用Bucket与Metric聚合
Elasticsearch的聚合嵌套能力(Bucket内嵌Metric或其他Bucket)是其核心优势,支持复杂分析场景
典型嵌套模式:
1 )分桶 → 子分桶(如先按岗位分组,再按年龄分组)
"aggs": {
"jobs": {
"terms": { "field": "job.keyword" },
"aggs": {
"age_ranges": { // 子聚合
"range": {
"field": "age",
"ranges": [
{ "to": 20 },
{ "from": 20, "to": 30 },
{ "from": 30 }
]
}
}
}
}
}
- 可视化映射:Kibana 的「多层嵌套饼图」即基于此实现
2 ) 分桶 → 指标计算(如按岗位统计平均工资)
"aggs": {
"jobs": {
"terms": { "field": "job.keyword" },
"aggs": {
"avg_salary": { "avg": { "field": "salary" } } // 子聚合
}
}
}
-
输出结构示例:
{ "aggregations": { "jobs": { "buckets": [ { "key": "ruby_engineer", "doc_count": 2, "avg_salary": { "value": 15000 }, // 子聚合结果 "age_ranges": { // 子分桶结果 "buckets": [ { "to": 20, "doc_count": 1 }, ... ] } } ] } } } -
嵌套层级无限制:可在子聚合中继续嵌套(如岗位→年龄→工资统计),但需权衡性能
案例:工程实践与优化
1 ) 基础聚合服务层
@Injectable()
export class AggregationService {
constructor(private readonly es: ElasticsearchService) {}
async termAggregation(index: string, field: string) {
const { body } = await this.es.search({
index,
size: 0,
body: {
aggs: {
distribution: {
terms: {
field: `${field}.keyword`, // 动态字段
size: 10
}
}
}
}
});
return body.aggregations.distribution.buckets;
}
}
或
import { Injectable } from '@nestjs/common';
import { ElasticsearchService } from '@nestjs/elasticsearch';
@Injectable()
export class AggregationService {
constructor(private readonly esService: ElasticsearchService) {}
// 示例:按岗位分组统计平均工资
async getJobAvgSalary() {
const { body } = await this.esService.search({
index: 'employees',
size: 0,
body: {
aggs: {
jobs: {
terms: { field: 'job.keyword' },
aggs: { avg_salary: { avg: { field: 'salary' } } }
}
}
}
});
return body.aggregations.jobs.buckets.map(bucket => ({
job: bucket.key,
count: bucket.doc_count,
avgSalary: bucket.avg_salary.value
}));
}
}
配置要点:
- 安装依赖:
npm install @nestjs/elasticsearch @elastic/elasticsearch - 模块注册:
import { ElasticsearchModule } from '@nestjs/elasticsearch'; @Module({ imports: [ ElasticsearchModule.register({ nodes: ['http://localhost:9200'] }), ], providers: [AggregationService] })
2 ) 动态管道处理器
class PipelineAggregator {
async executePipeline(config: PipelineConfig) {
const body = { size: 0, aggs: {} };
let currentAgg = body.aggs;
// 动态构建聚合链
config.stages.forEach(stage => {
currentAgg[stage.name] = { [stage.type]: stage.params };
if (stage.next) {
currentAgg[stage.name].aggs = {};
currentAgg = currentAgg[stage.name].aggs;
}
});
const result = await this.es.search({ index: config.index, body });
return this.unwrapAggResults(result.aggregations);
}
}
3 )动态范围聚合(含参数化查询)
import { Query } from '@nestjs/common';
@Get('salary-distribution')
async getSalaryDistribution(@Query('interval') interval: number = 5000) {
const body = {
aggs: {
salary_ranges: {
histogram: {
field: 'salary',
interval,
extended_bounds: { min: 0, max: 40000 }
}
}
}
};
return this.esService.search({ index: 'orders', body });
}
4 )多级嵌套聚合(岗位 + 年龄层薪资统计)
@Get('job-age-stats')
async getJobAgeStats() {
const body = {
aggs: {
jobs: {
terms: { field: 'job.keyword', size: 5 },
aggs: {
age_groups: {
range: {
field: 'age',
ranges: [ { to: 25 }, { from: 25, to: 35 }, { from: 35 } ]
},
aggs: { salary_stats: { stats: { field: 'salary' } } }
}
}
}
}
};
return this.esService.search({ index: 'employees', body });
}
5 ) 聚合缓存与实时更新
@Injectable()
export class CachedAggregationService {
async getCachedAggregation(cacheKey: string, query: () => Promise<any>) {
const cached = await this.cacheManager.get(cacheKey);
if (cached) return cached;
const liveResult = await query();
await this.cacheManager.set(cacheKey, liveResult, { ttl: 300 });
// 基于ES变更通知刷新缓存
this.setupRealtimeRefresh(cacheKey, query);
return liveResult;
}
}
或
// src/elastic/cached-aggregation.service.ts
import { CACHE_MANAGER, Inject, Injectable } from '@nestjs/common';
import { ElasticsearchService } from '@nestjs/elasticsearch';
import { Cache } from 'cache-manager';
@Injectable()
export class CachedAggregationService {
constructor(
private readonly es: ElasticsearchService,
@Inject(CACHE_MANAGER) private cacheManager: Cache
) {}
async getCachedAggregation(cacheKey: string, query: () => Promise<any>, ttl = 300) {
const cached = await this.cacheManager.get(cacheKey);
if (cached) return cached;
const liveResult = await query();
await this.cacheManager.set(cacheKey, liveResult, { ttl });
// 实时更新监听(基于 ES 变更通知)
this.setupRealTimeRefresh(cacheKey, query);
return liveResult;
}
private setupRealTimeRefresh(cacheKey: string, query: () => Promise<any>) {
// 实现基于 ES 订阅的更新机制(略)
}
}
6 ) 封装聚合构建器(高复用性)
import { AggregationContainer } from '@elastic/elasticsearch/api/types';
class AggregationBuilder {
private aggs: Record<string, AggregationContainer> = {};
addTerms(name: string, field: string, size: number = 10) {
this.aggs[name] = { terms: { field, size } };
return this;
}
addMetric(parent: string, name: string, type: string, field: string) {
if (!this.aggs[parent]) throw new Error(`Parent ${parent} not found!`);
this.aggs[parent].aggs = this.aggs[parent].aggs || {};
this.aggs[parent].aggs![name] = { [type]: { field } };
return this;
}
build() { return { aggs: this.aggs }; }
}
// 使用示例
const builder = new AggregationBuilder()
.addTerms('jobs', 'job.keyword')
.addMetric('jobs', 'avg_salary', 'avg', 'salary');
const query = { index: 'employees', size: 0, body: builder.build() };
7 )异步管道处理(复杂聚合流)
import { Transform } from 'stream';
// 将ES返回的聚合流转换为前端友好格式
class AggregationTransformer extends Transform {
_transform(data: any, _encoding: any, callback: Function) {
const result = data.aggregations.jobs.buckets.map(b => ({
job: b.key,
stats: {
min: b.salary_stats.min,
max: b.salary_stats.max,
avg: b.salary_stats.avg
}
}));
this.push(JSON.stringify(result));
callback();
}
}
// 在Service中调用
async getJobSalaryStats() {
const response = await this.esService.search({
index: 'employees',
size: 0,
body: {
aggs: {
jobs: {
terms: { field: 'job.keyword' },
aggs: { salary_stats: { stats: { field: 'salary' } } }
}
}
}
}, { asStream: true });
return response.body.pipe(new AggregationTransformer());
}
8 ) 生产环境配置优化
索引映射优化:
PUT /employees {
"mappings": {
"properties": {
"job": {
"type": "text",
"fields": { "keyword": { "type": "keyword" } } // 分桶专用
},
"salary": { "type": "integer" },
"join_date": { "type": "date", "format": "yyyy-MM-dd" }
}
}
}
集群参数调优:
elasticsearch.yml
thread_pool.search.queue_size: 2000 # 增大搜索队列
indices.queries.cache.size: 15% # 查询缓存分配
indices.fielddata.cache.size: 40% # 聚合字段缓存
search.max_buckets: 100000 # 防OOM屏障
9 ) 性能调优黄金法则
-
预计算加速
PUT sales_summary/_doc/daily_202310 { "date": "2023-10-01", "total_orders": 28450, // 预聚合指标 "avg_order_value": 320.5 } -
混合存储架构
-
资源隔离策略
# 专用聚合节点配置 node.roles: [data, ingest] # 禁用master/voting node.attr.usage: aggregation # 路由专属索引
常见陷阱与解决方案
| 问题现象 | 根因分析 | 解决方案 |
|---|---|---|
| 分桶结果不精确 | 分布式分片误差 | 设置 shard_size=200% |
| Text字段分桶异常 | 分词干扰 | 使用 .keyword 子字段 |
| 内存溢出(CircuitBreak) | 字段数据过大 | 启用 eager_global_ordinals |
| 数值聚合返回null | 映射类型错误 | 重建索引 "type": "double" |
| 日期直方图空桶缺失 | 默认过滤空桶 | 添加 "min_doc_count": 0 |
关键监控指标:
indices.fielddata.memory_size_in_bytessearch_bucket_countthread_pool.search.rejected
异步管道处理(复杂聚合流)
import { Transform } from 'stream';
// 将ES返回的聚合流转换为前端友好格式
class AggregationTransformer extends Transform {
_transform(data: any, _encoding: any, callback: Function) {
const result = data.aggregations.jobs.buckets.map(b => ({
job: b.key,
stats: {
min: b.salary_stats.min,
max: b.salary_stats.max,
avg: b.salary_stats.avg
}
}));
this.push(JSON.stringify(result));
callback();
}
}
// 在Service中调用
async getJobSalaryStats() {
const response = await this.esService.search({
index: 'employees',
size: 0,
body: {
aggs: {
jobs: {
terms: { field: 'job.keyword' },
aggs: { salary_stats: { stats: { field: 'salary' } } }
}
}
}
}, { asStream: true });
return response.body.pipe(new AggregationTransformer());
}
ES周边配置处理
- 字段类型优化:
- 分桶字段需设为
keyword(避免分词),日期字段设为date。PUT /employees { "mappings": { "properties": { "job": { "type": "text", "fields": { "keyword": { "type": "keyword" } } }, "join_date": { "type": "date" } } } }
- 聚合性能调优:
- 使用
size限制分桶数量(默认10) - 对高频聚合字段启用
eager_global_ordinals(预加载字典)PUT /employees/_mapping { "properties": { "job.keyword": { "type": "keyword", "eager_global_ordinals": true } } }
- 安全与权限:
- 通过Kibana角色限制聚合索引权限
- 使用API Key替代用户名密码访问ES
ES 生产环境配置优化
1 ) yml 配置
# elasticsearch.yml 关键配置
thread_pool.search.queue_size: 1000 # 增大搜索队列
indices.queries.cache.size: 10% # 查询缓存分配
indices.fielddata.cache.size: 30% # 聚合字段缓存
聚合专用硬件策略
node.roles: [data_hot, data_warm] # 冷热数据分离
2 )NestJS 模块集成
// src/elastic/elastic.module.ts
import { Module } from '@nestjs/common';
import { ElasticsearchModule } from '@nestjs/elasticsearch';
@Module({
imports: [
ElasticsearchModule.register({
node: process.env.ES_NODE,
maxRetries: 5,
requestTimeout: 30000,
sniffOnStart: true
})
],
exports: [ElasticsearchModule]
})
export class ElasticModule {}
性能优化黄金法则
1 ) 预计算加速
// 创建预聚合索引
PUT sales_summary/_doc/2023-10
{
"date": "2023-10-01",
"total_sales": 28450,
"avg_order_value": 320.5
}
2 ) 分片路由策略
// 按日期分区
PUT orders
{
"settings": {
"number_of_shards": 12,
"routing": {
"required": true
}
}
}
3 ) 混合存储架构
常见陷阱与解决方案
| 问题现象 | 根本原因 | 解决方案 |
|---|---|---|
| 聚合结果不精确 | 分布式分片误差 | 设置 shard_size=200% |
| 数值字段聚合失败 | 映射类型错误 | 重建索引 "type": "double" |
| Text 字段分桶异常 | 分词导致 | 使用 .keyword 子字段 |
| 内存溢出(CircuitBreak) | 字段数据过大 | 启用 eager_global_ordinals |
- 监控指标:
indices.fielddata.memory_size_in_bytessearch_bucket_count
最佳实践总结
1 ) 数据建模先行
- 分桶字段必设
keyword类型 - 时序场景采用
date类型 + ISO8601 格式
2 ) 聚合设计原则
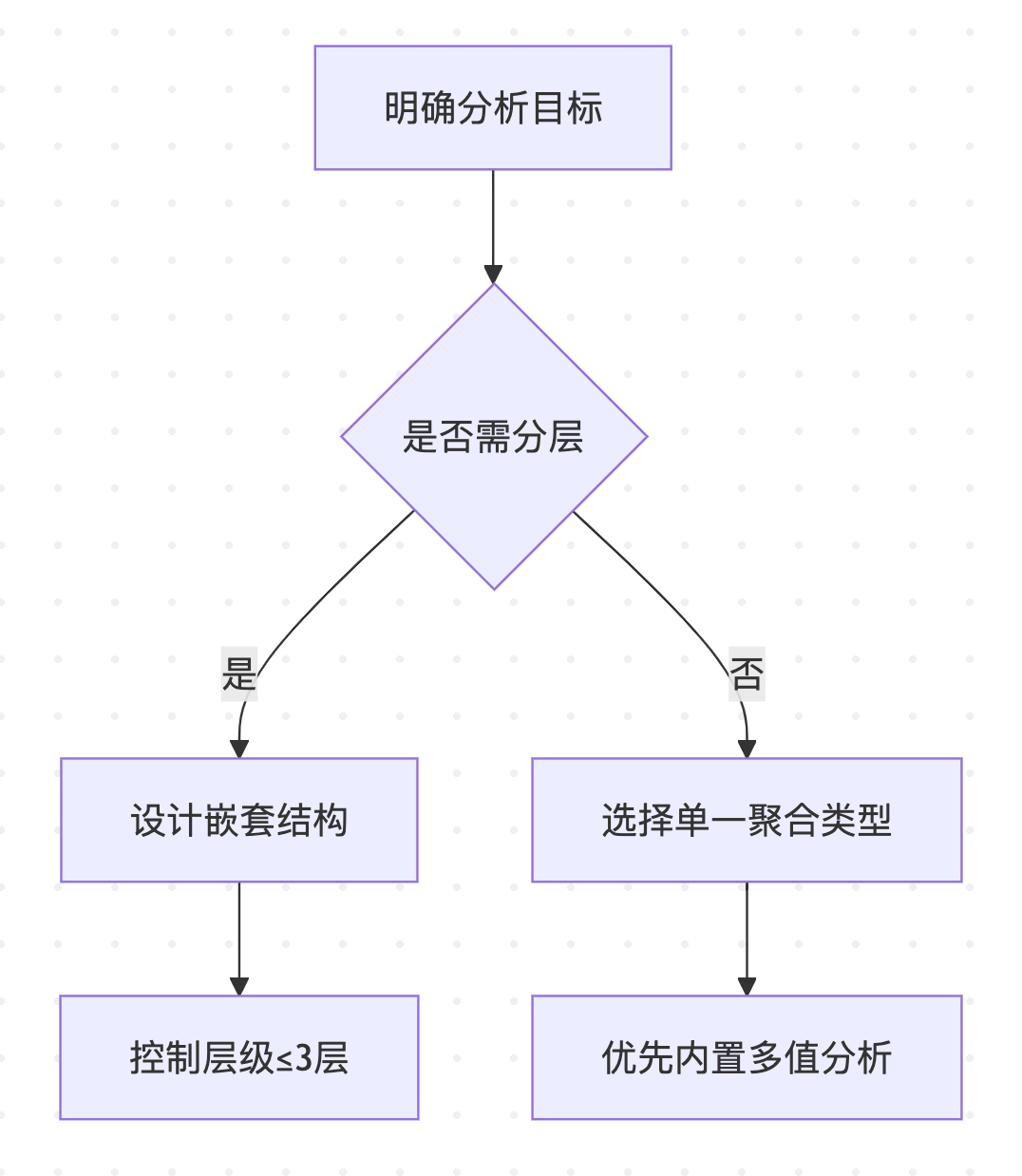
4 ) 工程实施规范
- 生产环境启用
search.max_buckets限流 - 高频聚合字段配置
eager_global_ordinals - 冷热数据分层存储降低硬件成本
5 ) 性能与精度平衡
| 场景 | 优化方向 | 配置示例 |
|---|---|---|
| 实时监控仪表盘 | 响应速度优先 | size=5, shard_size=100 |
| 离线上报分析 | 精度优先 | size=1000, shard_size=5000 |
终极价值:
- 通过组合分桶策略(Bucket)、指标计算(Metric)、管道处理(Pipeline)
- 实现从实时监控到预测分析的完整数据洞察闭环
6 ) Elasticsearch聚合分析是实时大数据统计的核心工具
三层能力需掌握:
- Metric聚合:快速计算数值指标(单值/多值)。
- Bucket聚合:灵活分组数据(词项/范围/直方图)。
- 嵌套组合:通过多层子聚合实现复杂分析(如分桶→指标→二次分桶)。
工程建议:
- 优先使用
keyword类型字段分桶,避免分词干扰。 - 嵌套层级不宜过深(影响性能与可读性)。
- 结合Kibana可视化验证聚合结果(如直方图、饼图)。
扩展阅读:现代分析架构演进
1 ) 流批一体架构
2 ) AI 增强分析
- 异常检测:
moving_percentile管道聚合 - 预测分析:集成 Prophet 模型
- 自然语言解释:LLM 生成分析报告
通过深度整合 Elasticsearch 聚合分析与现代数据处理栈,可构建从实时监控到预测分析的完整数据洞察体系。最新 ES 8.0 版本新增 Time Series Aggregation 进一步提升了时序分析性能,使单集群可支持每秒百万级聚合操作。


















 570
570

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











