









 本文深入探讨了Java集合框架中的HashMap、HashSet、HashTable、LinkedHashMap及其变体,详细阐述了它们的实现原理和差异。HashMap是数组与链表的结合体,线程不安全;HashSet基于HashMap实现,保证唯一性;HashTable线程安全但效率较低;LinkedHashMap保持插入或访问顺序;在多线程环境中,推荐使用ConcurrentHashMap以保证线程安全。
本文深入探讨了Java集合框架中的HashMap、HashSet、HashTable、LinkedHashMap及其变体,详细阐述了它们的实现原理和差异。HashMap是数组与链表的结合体,线程不安全;HashSet基于HashMap实现,保证唯一性;HashTable线程安全但效率较低;LinkedHashMap保持插入或访问顺序;在多线程环境中,推荐使用ConcurrentHashMap以保证线程安全。
Java集合实现原理
Java集合实现原理学习笔记
参考文档
http://wiki.jikexueyuan.com/project/java-collection/
http://www.runoob.com/java/java-collections.html
Java集合框架图
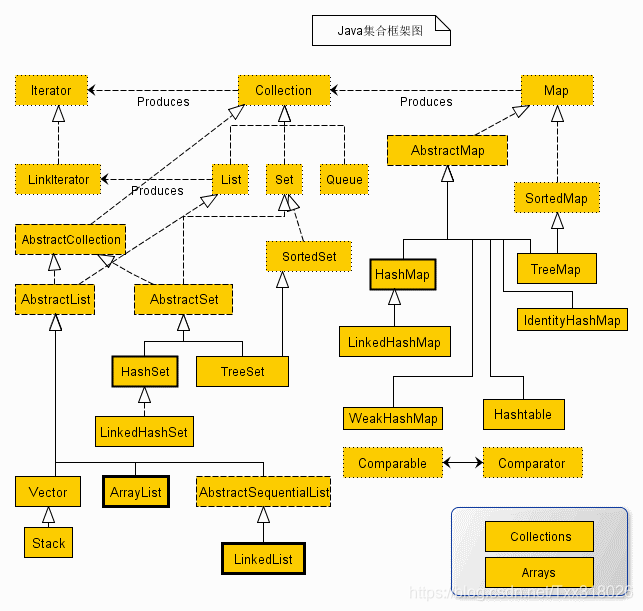
Java 集合框架主要包括两种类型的容器,一种是集合(Collection),存储一个元素集合,另一种是图(Map),存储键/值对映射
HashMap
HashMap实际上是一个“链表散列”的数据结构,即数组和链表的结合体。
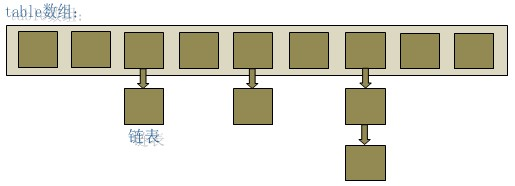
HashMap 底层就是一个数组结构,数组中的每一项又是一个链表。当新建一个 HashMap 的时候,就会初始化一个数组。
当我们往 HashMap 中 put 元素的时候,先根据 key 的 hashCode 重新计算 hash 值,根据 hash 值得到这个元素在数组中的位置(即下标),如果数组该位置上已经存放有其他元素了,那么在这个位置上的元素将以链表的形式存放,新加入的放在链头,最先加入的放在链尾。如果数组该位置上没有元素,就直接将该元素放到此数组中的该位置上。
HashMap 包含如下几个构造器:
HashMap():构建一个初始容量为 16,负载因子为 0.75 的 HashMap。
HashMap(int initialCapacity):构建一个初始容量为 initialCapacity,负载因子为 0.75 的 HashMap。
HashMap(int initialCapacity, float loadFactor):以指定初始容量、指定的负载因子创建一个 HashMap。
Fail-Fast 机制
java.util.HashMap 不是线程安全的,因此在HashMap迭代器迭代过程中,如果有其他线程修改了map,会抛出 ConcurrentModificationException,这就是 fail-fast 策略。
解决方案
fail-fast 机制,是一种错误检测机制。它只能被用来检测错误,因为 JDK 并不保证 fail-fast 机制一定会发生。若在多线程环境下使用 fail-fast 机制的集合,建议使用“java.util.concurrent 包下的类”去取代“java.util 包下的类”。
HashMap遍历
有两种遍历方式
一
Map map = new HashMap();
Iterator iter = map.entrySet().iterator();
while (iter.hasNext()) {
Map.Entry entry = (Map.Entry) iter.next();
Object key = entry.getKey();
Object val = entry.getValue();
}
二
Map map = new HashMap();
Iterator iter = map.keySet().iterator();
while (iter.hasNext()) {
Object key = iter.next();
Object val = map.get(key);
}
第一种更高效,是基于HashMap的存储原理,先遍历数组,再遍历Entry
第二种则是先遍历出所有的key,再根据key去查找value,根据单链表增删快,查找慢的特性,所以效率低
HashMap在jdk1.8之后,如果map的size大于8,则转为红黑树实现
(基于时间复杂度及空间复杂度的考虑)
HashSet
HashSet底层基于HashMap实现,用hashMap put相同的key时,只会覆盖对应value,key不会改变的特性,保证hashSet的唯一性,使用hashSet时,需重写对象的hashCode()及equals()方法
有五种构造方法,HashSet(int initialCapacity, float loadFactor),HashSet(int initialCapacity),HashSet(int initialCapacity),HashSet(Collection<? extends E> c),HashSet(int initialCapacity, float loadFactor, boolean dummy)其中第五种为包访问权限,不对外公开,实际为支持LinkedHashSet实现( * Constructs a new, empty linked hash set. (This package private
* constructor is only used by LinkedHashSet.) The backing
* HashMap instance is a LinkedHashMap with the specified initial
* capacity and the specified load factor.)。
https://blog.youkuaiyun.com/shengwusuoxi/article/details/22792361
HashTable
HashTable与hashMap类似,也是一个散列表。put与get方法实现原理也与hashMap相同,先计算hash值,找到对应位置,看是否已经有Entry数组,有则迭代,有相同key,替换old value,返回old value;没有则存放键值对,返回空。
Hashtable 与 HashMap 的简单比较
1、HashTable 基于 Dictionary 类,而 HashMap 是基于 AbstractMap。Dictionary 是任何可将键映射到相应值的类的抽象父类,而 AbstractMap 是基于 Map 接口的实现,它以最大限度地减少实现此接口所需的工作。
2、HashMap 的 key 和 value 都允许为 null,而 Hashtable 的 key 和 value 都不允许为 null。HashMap 遇到 key 为 null 的时候,调用 putForNullKey 方法进行处理,而对 value 没有处理;Hashtable遇到 null,直接返回 NullPointerException。
3、Hashtable 方法是同步,而HashMap则不是。我们可以看一下源码,Hashtable 中的几乎所有的 public 的方法都是 synchronized 的,而有些方法也是在内部通过 synchronized 代码块来实现。所以有人一般都建议如果是涉及到多线程同步时采用 HashTable,没有涉及就采用 HashMap,但是在 Collections 类中存在一个静态方法:synchronizedMap(),该方法创建了一个线程安全的 Map 对象,并把它作为一个封装的对象来返回。
但目前Hashtable已过时,如果需要线程安全,则使用ConcurrentHashMap。否则使用HashMap
LinkedHashMap
有序的 HashMap
LinkedHashMap 是 Map 接口的哈希表和链接列表实现,具有可预知的迭代顺序。此实现提供所有可选的映射操作,并允许使用 null 值和 null 键。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
LinkedHashMap 实现与 HashMap 的不同之处在于,LinkedHashMap 维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,该迭代顺序可以是插入顺序或者是访问顺序。
LinkedHashMap的如下两个特性,可用于实现LRUCcahe(LRU 即 Least Recently Used,最近最少使用)
1、实现了按访问顺序存储
2、本身有方法判断是否需要移除最不常读取的数
LinkedHashSet
继承于HashSet,基于LinkedHashMap实现;有四种构造方法,LinkedHashSet(int initialCapacity, float loadFactor),LinkedHashSet(int initialCapacity),LinkedHashSet(int initialCapacity),LinkedHashSet(Collection<? extends E> c),默认初始容量initialCapacity 16,加载因子loadFactor 0.75 。
注意:
1、LinkedHashSet 是 Set 的一个具体实现,其维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,该迭代顺序可为插入顺序或是访问顺序。
2、LinkedHashSet 继承与 HashSet,并且其内部是通过 LinkedHashMap 来实现的。有点类似于LinkedHashMap 其内部是基于 Hashmap 实现一样,不过还是有一点点区别的。
3、如果我们需要迭代的顺序为插入顺序或者访问顺序,那么 LinkedHashSet 是需要你首先考虑的。
ArrayList
ArrayList可以理解为动态数组,就是List接口的可变数组的实现,允许包括null在内的所有元素。除了实现list接口外,此类还提供一些方法来操作内部用来存储列表的数组大小。(此类大致等同于Vector类,除了此类是不同步的)
ArrayList自动增长会带来数据向新数组的重新拷贝,因此,如果可预知数据量的多少,可在构造 ArrayList 时指定其容量。在添加大量元素前,应用程序也可以使用 ensureCapacity 操作来增加 ArrayList 实例的容量,这可以减少递增式再分配的数量。
ArrayList 提供了三种方式的构造器:
public ArrayList()可以构造一个默认初始容量为10的空列表;
public ArrayList(int initialCapacity)构造一个指定初始容量的空列表;
public ArrayList(Collection<? extends E> c)构造一个包含指定 collection 的元素的列表,这些元素按照该collection的迭代器返回它们的顺序排列的
存储
1.set(int index, E element)
2.add(E e)
3.add(int index, E element)
4.addAll(Collection<? extends E> c) 和 addAll(int index, Collection<? extends E> c)
读取
get(int index)
删除
1.public E remove(int index)
2.public boolean remove(Object o)
删除元素后,数组该元素之后的元素都会向左移动一位
LinkedList
LinkedList基于链表实现,支持高校的插入和删除操作,随机访问比ArrayList差。
https://www.jianshu.com/p/56c77c517e71
ConcurrentHashMap
线程安全的HashMap
HashMap线程安全的另外两种实现:Hashtable 或者Collections.synchronizedMap(hashMap),但这两种方式基本都是对整个 hash 表结构做锁定操作,这样在锁表的期间,别的线程就需要等待了,性能不高。
Segment&HashEntry
他们都是ConcurrentHashMap的内部类,在Segment中有一个HashEntry数组,而在HashEntry数组中,包含了 key 和 value 以及 next 指针(类似于 HashMap 中 Entry)
所以通俗的讲,ConcurrentHashMap 数据结构为一个 Segment 数组,Segment 的数据结构为 HashEntry 的数组,而 HashEntry 存的是我们的键值对,可以构成链表。
ConcurrentHashMap 的高并发性主要来自于三个方面:
1、用分离锁实现多个线程间的更深层次的共享访问。
2、用 HashEntery 对象的不变性来降低执行读操作的线程在遍历链表期间对加锁的需求。
3、通过对同一个 Volatile 变量的写 / 读访问,协调不同线程间读 / 写操作的内存可见性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









