




 本文提出一种新颖的自监督框架,无需人工标注物体位置顺序,即可从复杂场景中恢复被遮挡物体的完整形态。该方法通过构建遮挡顺序图,确定物体间遮挡关系,进而使用部分补全网络逐步恢复物体的缺失部分。
本文提出一种新颖的自监督框架,无需人工标注物体位置顺序,即可从复杂场景中恢复被遮挡物体的完整形态。该方法通过构建遮挡顺序图,确定物体间遮挡关系,进而使用部分补全网络逐步恢复物体的缺失部分。
Self-Supervised Scene De-occlusion(2020CVPR 港中文
)
1.要解决的问题:
Natural scene understanding 是一个具有挑战的任务,特别是当多个物体因前后顺序位置而产生
遮挡时。有些时候需要去分析每个独立的物体,恢复其被遮掩的部分。
在
instance segmentation 的数据集中,像 COCO、KITTI、LVIS 这些。里面并没有遮挡关系和 amodal mask 的标注,所以有监督学习的思路是无法解决上述问题的。
论文能够实现的效果图:
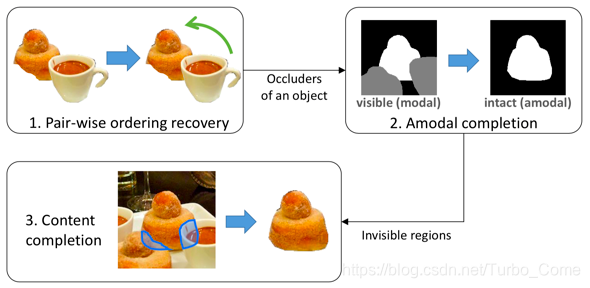
仅使用自身的数据,将一张真实场景的,有遮掩关系的图片分解为完整的物体和背景。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3007
3007

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









