







 本文介绍了如何利用Intel DDP技术提升Tungsten Fabric vRouter的性能,特别是在MPLSoGRE数据包处理中的瓶颈问题。通过DDP,可以实现数据包在所有CPU内核间的平均分配,显著提高处理速度和降低延迟,尤其在多核场景下效果明显。
本文介绍了如何利用Intel DDP技术提升Tungsten Fabric vRouter的性能,特别是在MPLSoGRE数据包处理中的瓶颈问题。通过DDP,可以实现数据包在所有CPU内核间的平均分配,显著提高处理速度和降低延迟,尤其在多核场景下效果明显。
在刚刚结束的“2020虚拟开发人员和测试论坛”上,来自瞻博网络的工程师Kiran KN和同事,介绍了在Tungsten Fabric数据平面上完成的一组性能改进(由Intel DDP技术提供支持),以下为论坛技术分享的精华:
【本文相关资料pdf文档下载】
https://tungstenfabric.org.cn/assets/uploads/files/tf-vrouter-performance-improvements.pdf
【视频链接】
https://v.qq.com/x/page/j3108a4m1va.html
作为DPDK应用的vRouter
在深入到DDP技术之前,首先介绍一下vRouter,它是什么,以及在整个Tungsten Fabric框架中的位置。
实际上,vRouter可以部署在常规X86服务器上,也可以在OpenStack或K8s的计算节点当中。vRouter是主要的数据平面组件,有两种部署的模式,分别是vRouter:kernel module,以及vRouter:DPDK模式。
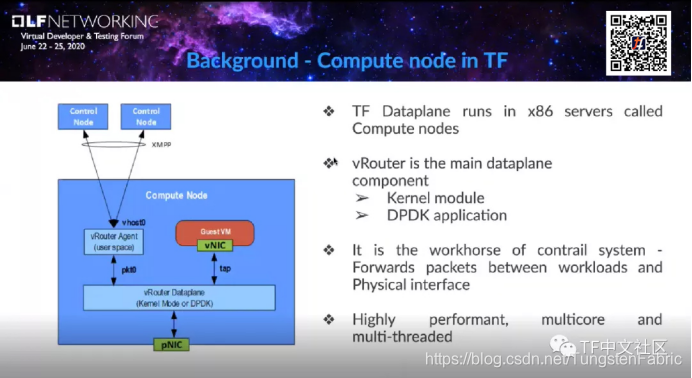
在用DPDK改善性能之前,此用例将涉及DPDK应用和vRouter。vRouter的职责是数据平面,用于数据包转发和由vRouter代理在计算节点上编程的数据包转发,但实际上,整个配置是通过控制器上的XMPP提供的。我们使用XMPP通过vRouter agent与控制器通信,并且有一个专门的接口来对vRouter数据平面进行编程以转发软件包。
在DPDK中,vRouter是一个高性能、多核和多线程的应用程序,这里想强调一下,它是专用于多核的DPDK应用,我们需要寻找多核的正确用法。
我们可以从示例中看到,网卡具有与vRouter相同数量的队列,已为数据包或链接分配了核心。
首先,数据包需要由网卡平均地分配到所有路由器转发核心
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









