




关注gongzhonghao【图灵学术SCI科研圈】,解锁更多SCI相关资讯!
在当今计算密集型应用中,大规模数据处理面临严峻挑战:高维度、稀疏性和动态环境下的非平稳性不断推高系统开销,引发带宽瓶颈、延迟激增与资源浪费。三篇前沿论文不约而同地聚焦这一痛点,提出创新性解决方案——通过智能分区与聚类策略重塑计算架构。TeraNoC的混合网状交叉开关、SpGEMM的矩阵重排序与聚类优化、以及多标签数据流的增量分层分区,均以动态调整为核心,打破传统可扩展性枷锁。
这些方法巧妙平衡局部与全局交互,在内存访问、标签依赖和互连拓扑中挖掘隐性规律,将计算效率提升至新高度。它们不仅显著压缩延迟与功耗,更赋予系统实时适应能力,为下一代AI推理、科学计算与流处理奠定高效基石。
TeraNoC: A Multi-Channel 32-bit Fine-Grained, Hybrid Mesh-Crossbar NoC for Efficient Scale-up of ... 1000+ Core Shared-L1-Memory Clusters
方法:
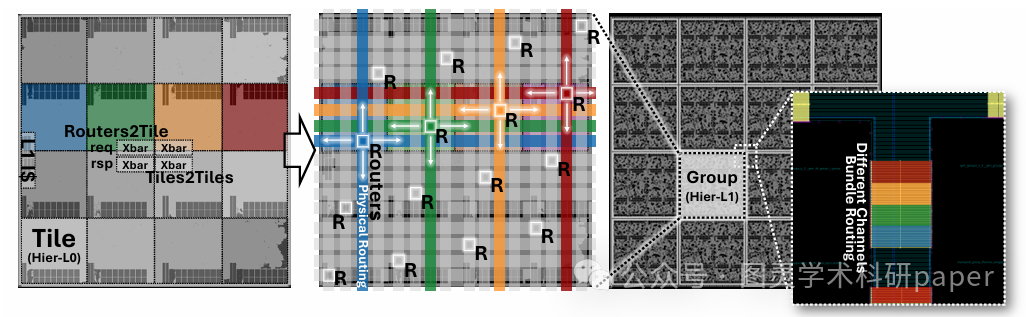
文章首先构建了一个两层的层次化设计流程,将大规模集群划分为多个层次,每个层次采用不同的拓扑结构以平衡可扩展性、延迟和物理设计的可行性。在基础层次(Hier-L0)中,使用全组合交叉开关连接少量核心与部分L1内存银行,实现单周期低延迟访问;在更高层次(Hier-L1),通过2D网格NoC连接多个基础层次块,并利用路由器重映射器优化流量分配,以支持大规模集群的高效扩展。此外,文章还详细描述了TeraNoC的关键设计元素,包括对数交叉开关、细粒度路由器、路由器重映射器以及非对称请求通道的设计与实现,这些设计共同确保了TeraNoC在大规模多核集群中的高性能和高面积效率。
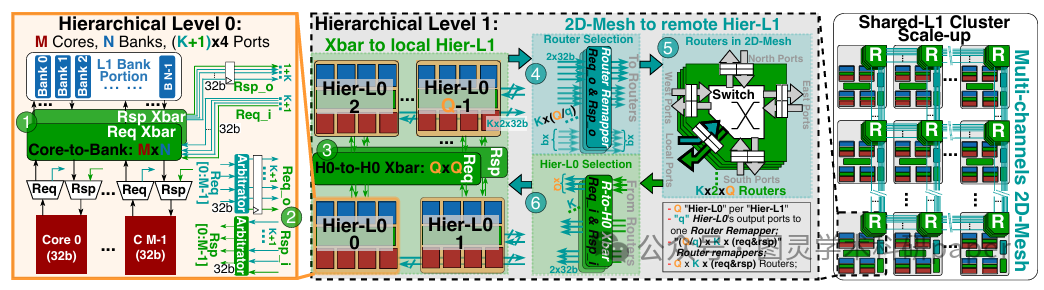
创新点:
-
提出了一种混合网格-交叉开关(Mesh–Xbar)拓扑结构,结合了2D网格的可扩展性和交叉开关的低延迟特性,有效解决了传统架构在大规模集群扩展时面临的性能瓶颈。
-
设计了一种路由器重映射器(Router Remapper),能够动态平衡网络流量负载,显著提高了多通道带宽的利用率,从而在高负载情况下保持高效的通信性能。
-
引入了可配置数量的读写请求通道,最大化利用物理布线资源,同时通过物理设计感知架构简化了多通道NoC的实现,降低了硬件设计的复杂度。
论文链接:
https://arxiv.org/pdf/2508.02446
关注gongzhonghao【图灵学术SCI科研圈】,获取层次聚类最新选题和idea
Improving SpGEMM Performance Through Matrix Reordering and Cluster-wise Computation
方法:
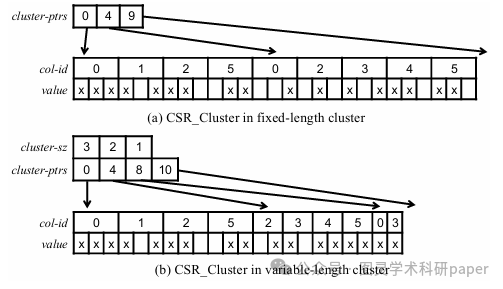
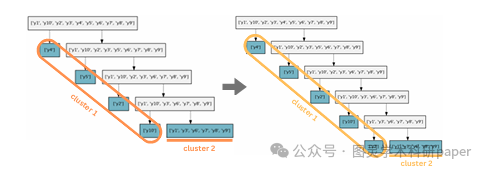
文章首先通过SpGEMM计算生成候选相似行对,避免了传统层次聚类中计算成本高昂的局部敏感哈希(LSH)步骤。接着,利用这些相似行对构建CSR_Cluster格式,该格式通过将相似行分组到集群中,优化了对B矩阵的访问模式。最后,文章通过实验验证了该方法在多种矩阵和工作负载下的有效性,展示了其在提高SpGEMM性能方面的潜力。
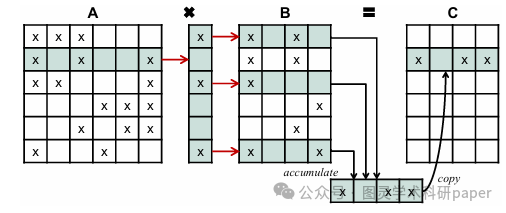
创新点:
-
提出了一种新的层次聚类算法,通过结合基于SpGEMM的快速相似行对生成和新的稀疏矩阵格式,有效提高了SpGEMM的性能,平均加速比达到1.39倍,且预处理成本低。
-
引入了一种新的稀疏矩阵格式CSR_Cluster,支持按集群进行列式处理,提高了对B矩阵行访问的重用性,从而改善了数据局部性。
-
进行了迄今为止最全面的矩阵重排序和聚类对SpGEMM影响的实证研究,涉及110个矩阵、10种重排序算法和3种聚类策略,揭示了重排序和聚类在性能提升与预处理时间之间的权衡。
论文链接:
https://arxiv.org/pdf/2507.21253
关注gongzhonghao【图灵学术SCI科研圈】,获取层次聚类最新选题和idea
Online hierarchical partitioning of the output space in extreme multi-label data streams
方法:
文章首先通过Jaccard相似度度量来捕捉标签之间的相关性,并基于这些相似性进行在线分裂聚合聚类,从而动态地构建标签空间的层次结构。接着,iHOMER利用基于多变量伯努利过程的全局树形学习器来指导实例的划分,并在全局和局部层面集成漂移检测机制,以应对数据的非平稳性。最后,通过在23个真实世界数据集上的实验验证了iHOMER的有效性,结果表明iHOMER在多个性能指标上优于现有的先进方法。
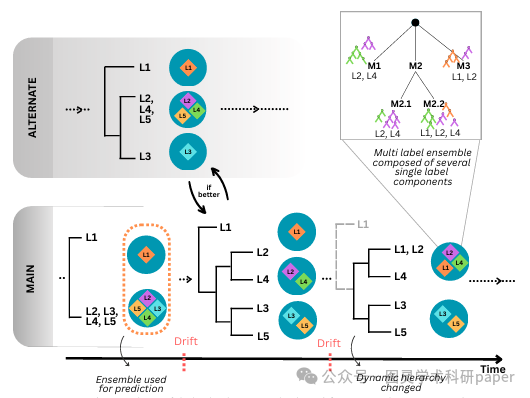
创新点:
-
提出了一种新的在线多标签学习方法iHOMER,该方法能够动态地对标签空间进行划分,形成不相交且相关的标签簇,从而提高了模型对概念漂移的适应能力和预测性能。
-
引入了一种基于Jaccard相似度的在线分裂聚合聚类方法,用于增量式地构建标签空间的层次结构,这种方法能够根据数据的动态变化自动调整标签簇的划分。
-
集成了全局和局部的漂移检测机制,使得模型能够在数据分布发生变化时动态地重新构建标签分区和子树,从而更好地适应非平稳的数据流。
论文链接:
https://arxiv.org/pdf/2507.20894
► 论文发表难题,一站式解决!
TURING
选题是论文的第一步,非常重要!
但很多学生找到了热门的选题,却卡在代码和写作上!可见论文要录用,选题-idea-代码-写作都缺一不可!
图灵学术论文辅导,汇聚经验丰富的实战派导师团队,针对计算机各类领域提供1v1专业指导,直至论文录用!
关注gongzhonghao【图灵学术SCI科研圈】,解锁更多SCI相关资讯!

















 1107
1107

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









