




关注gongzhonghao【学术鲸】,解锁更多SCI相关资讯!
在当今快速发展的计算机视觉领域,模型的适应性和泛化能力成为了研究的核心焦点。无论是面对类别不断变化的图像分割任务、需要区分已知与未知类别的细粒度图像分类,还是在测试时动态适应新数据分布的视觉语言模型,一个共同的挑战始终存在:如何在不依赖大量额外标注数据的情况下,让模型更好地适应新环境并保持高性能?
小图特为您带来这三篇论文,分别从不同的角度出发,提出了创新性的解决方案,共同指向了这一关键问题。它们不仅展示了各自领域的最新进展,更揭示了模型适应性研究的共通之处,为未来的研究方向提供了宝贵的启示,为我们打开了通往智能视觉系统新时代的大门!
Rethinking Query-based Transformer for ContinualImage Segmentation
方法:
文章首先分析了基于查询的Transformer在连续图像分割中的内置目标性及其在训练过程中的变化,发现其在不同阶段会因语义先验的变化而逐渐失效。为此,SimCIS通过懒惰查询预对齐方法直接利用图像特征图中的语义信息初始化查询特征,确保了目标性在每个阶段的保留。同时,通过一致性选择损失约束跨阶段的特征选择,进一步增强了目标性在连续学习中的稳定性。最后,通过虚拟查询策略在解码器中重放虚拟查询,模拟旧类别的语义信息,有效避免了灾难性遗忘,同时降低了对实际图像数据的依赖,提高了模型的鲁棒性和效率。
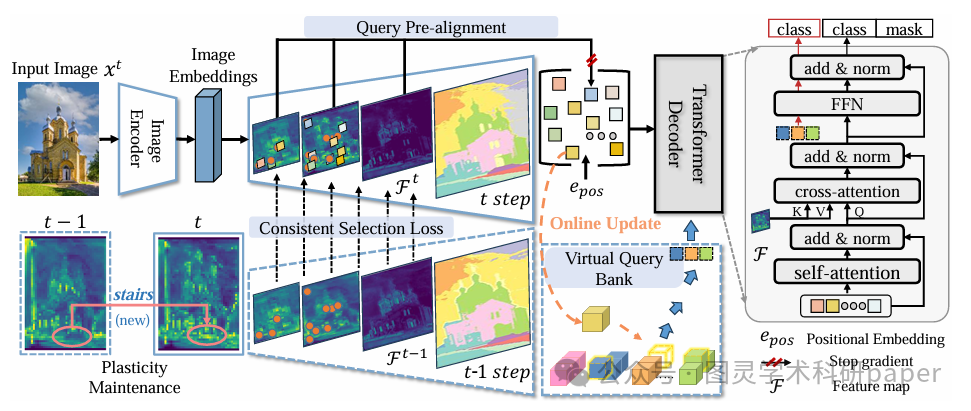
创新点:
-
提出了懒惰查询预对齐(Lazy Query Pre-Alignment)方法,通过直接从图像特征图中选择语义显著的特征来初始化查询特征,确保了查询与语义先验的完美对齐,从而保留了目标性。
-
引入了一致性选择损失(Consistent Selection Loss),通过跨阶段的特征选择一致性约束,确保了同一图像在不同阶段选择的语义显著位置保持一致,进一步增强了目标性在连续学习中的稳定性。
-
设计了虚拟查询(Virtual Query)策略,通过在解码器中重放虚拟查询来模拟旧类别的语义信息,避免了灾难性遗忘,同时减少了对实际图像数据的依赖,降低了存储需求。

论文链接:
https://arxiv.org/pdf/2507.07831
关注gongzhonghao【学术鲸】,获取模型适应性最新选题和idea~
Adaptive Part Learning for Fine-Grained Generalized Category Discovery: APlug-and-Play Enhancement
方法:
文章首先通过利用 DINO(一种自监督视觉Transformer)的部件先验和共享可学习部件查询,实现了跨不同图像的一致部件发现和对应关系。接着,通过全最小对比学习和多样性损失函数,强化了部件的区分性和泛化能力。最后,APL作为一个即插即用的增强模块,被无缝集成到现有的GCD框架中,通过替换传统的CLS令牌特征来提升模型的整体性能。
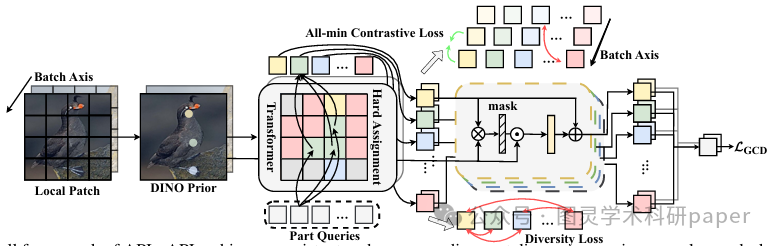
创新点:
-
APL是首个通过强调区分性部件来增强可区分性,同时通过共享其他部件来促进知识迁移和泛化的方法,有效解决了现有GCD方法中可区分性与泛化能力之间的固有矛盾。
-
提出了一种简单而有效的无监督对象部件发现方法,能够跨不同图像一致地发现和对应部件,无需额外注释,即可实现细粒度图像理解。
-
引入了一种新颖的全最小对比学习目标,能够自适应地选择并约束负样本对中最区分性的部件,从而促进区分性但可泛化的表示学习。
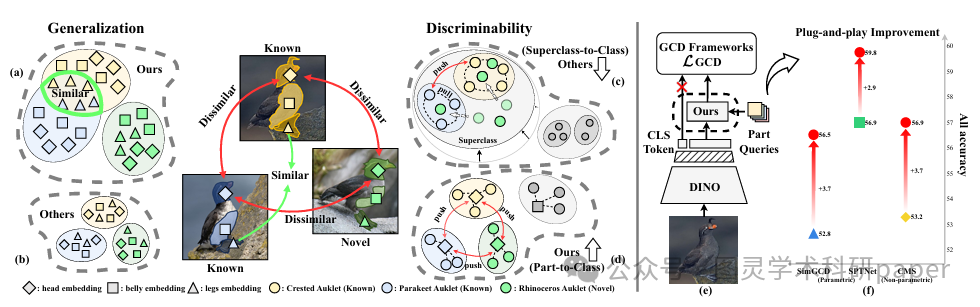
论文链接:
https://arxiv.org/pdf/2507.06928
关注gongzhonghao【学术鲸】,获取模型适应性最新选题和idea~
Free on the Fly: Enhancing Flexibility in Test-Time Adaptation with Online EM
方法:
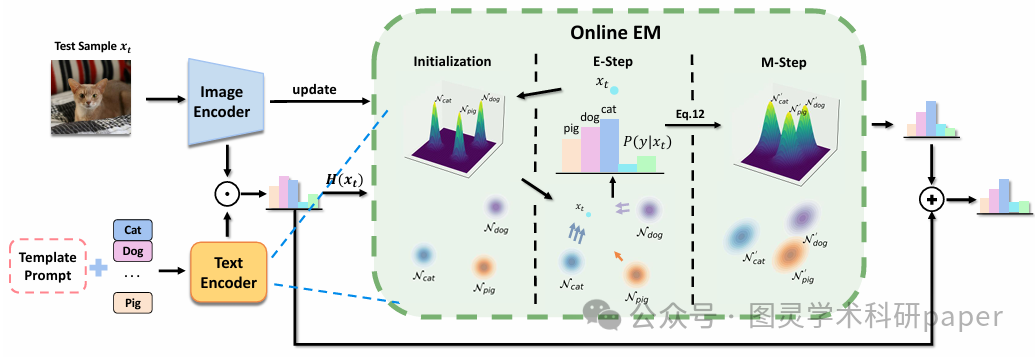
文章首先假设每个类别的测试样本服从独立的高斯分布,并基于此采用高斯判别分析(GDA)进行分类。然而,直接应用GDA面临诸多挑战,如测试样本无标签、样本无法同时观测等。为此,FreeTTA引入在线EM算法,利用VLMs提供的零样本预测作为先验,通过E步计算后验概率和M步更新参数,动态地调整每个类别的均值向量和共享协方差矩阵。此外,FreeTTA还结合了VLMs的零样本预测结果,通过评估每个样本的置信度来调整其对参数更新的贡献,从而在目标域中实现更稳定和鲁棒的预测。
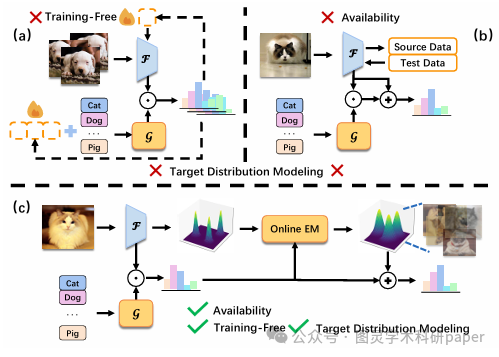
创新点:
-
FreeTTA是首个同时满足目标分布建模、可用性和无需训练这三个关键特性的TTA方法,为VLMs的高效测试时适应提供了全新的解决方案。
-
提出了一种在线EM算法,利用VLMs的零样本预测作为先验,迭代计算每个在线测试样本的后验概率并更新参数,实现了无需访问或存储过去数据的连续在线适应。
-
通过将VLM的零样本分类结果与基于概率生成模型的预测相结合,FreeTTA在目标域中增强了模型的稳定性和鲁棒性,同时显著提升了分类性能。
论文链接:
https://arxiv.org/pdf/2507.06973
► 论文发表难题,一站式解决!
TURING
选题是论文的第一步,非常重要!
但很多学生找到了热门的选题,却卡在代码和写作上!可见论文要录用,选题-idea-代码-写作都缺一不可!
图灵学术论文辅导,汇聚经验丰富的实战派导师团队,针对计算机各类领域提供1v1专业指导,直至论文录用!
关注gongzhonghao【学术鲸】,解锁更多SCI相关资讯!


















 1392
1392

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









