




 探讨使用段落向量模型和整数线性规划,从相似文章学习内容模板,生成维基百科缺失实体的非侵权文章。通过计算句子间的连贯性得分,确保生成文章的流畅性和信息保留。
探讨使用段落向量模型和整数线性规划,从相似文章学习内容模板,生成维基百科缺失实体的非侵权文章。通过计算句子间的连贯性得分,确保生成文章的流畅性和信息保留。
1.document embeddings → 获得单词和段落的矢量表示 → 向量算相似度 →判别不同的文章(分类器)
2.两步的整数线性规划(ILP)模型 → summarize & rewrite
一、导论
假设1:类别信息是已知的,文章通常属于多个类别,而这些类别往往不是同等重要的。
文章从多个类别总结 → 问题:
- 文章不够精练,某些情况下,分类不能提供太多信息
- 侵犯版权,意味着实体上的内容不能直接复制到维基百科
- 连贯性问题
我们使用段落向量模型(Le and Mikolov, 2014)来获得红色链接实体的向量表示,该模型计算可变长度文本的连续分布向量表示。
我们利用词对**(名词和动词)在句子之间的转换概率来计算任意两个句子之间的连贯性得分**。
二、相关工作
-
前人使用category,限制在一个category中只有几个重要的部分,导致错过了在stubs中附加相关的部分
- 与之前的工作相比,我们的方法不需要维基百科的categories信息。
-
最近的工作:single document extractive summarization.
- 本文:multi-document abstractive summarization
三、方法
想实现的是,没有相应文章的维基百科实体生成一个不侵权的文章
1.实体表示
类似的实体在Wikipedia的其他文章中也在类似的上下文中提到过。
例如,实体Sonia Bianchetti在英文维基百科中并没有相应的文章(截至2015年11月),但是会在referee,judge等词的上下文出现。
因此,我们可以借鉴类似文章的结构来创建实体的文章。
PV-DM
paragraph vector distributed memory
作用:
- 在维基百科上识别类似的文章
- 从web检索的新段落的向量表示的推理
直接用gensim包里的doc2vec
2.内容生成阶段
-
我们需要从web中检索与实体相关的具有信息的文本片段,并将它们分配到本文中适当的部分中
- 语义上相似的部分可能有不同的标题,所以作者用了repeated bisection clustering (RBR)保证每个聚类内部的相似度都在0.5以上
-
我们需要有效地总结和重写分配的内容
- 意译 →生成新句子:word-graph construction , bigram
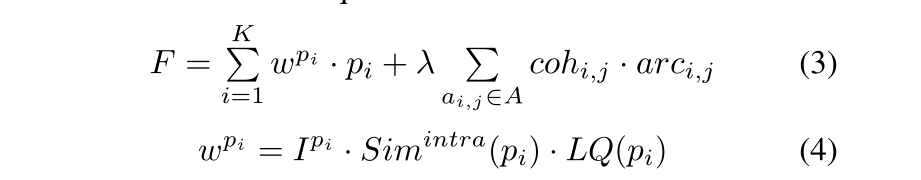
-
线性规划选句子
- pip_ipi和arci,jarc_{i,j}arci,j都是01变量,表示句子是否选中,以及i,j是否相邻
- 考虑了句子的质量:句子的权重wpiw^{p_i}wpi就是由句子的语言质量LQ和、句子的重要性IpiI^{p_i}Ipi、平均向量的相似度计算出的
- 考虑了句子之间的连贯性:cohi,jcoh_{i,j}cohi,j衡量句子i,j之间的连贯性
-
改写句子
- 使用的是trigram
- 又是一个线性规划,针对覆盖性、语言质量进行了限制
四、实验结果
实验用2015年的维基语料,有50GB,480万文章,15500个红色链接
基准模型重建文章的时候,由于时间长,只选1000篇构建文章
WikiWrite在分类任务上的表现优于WikiKreator
有摘要器的系统保留更多的信息
五、亮点
- 没有用类别信息,而是从相似的文章学习内容模板
- 我们利用词对**(名词和动词)在句子之间的转换概率来计算任意两个句子之间的连贯性得分**,转移概率是从相似文章中相邻句子对中获得的,这个过程好像可以复现
- gensim包里的doc2vec
六、疑问
red-linked articles →缺少的引用??
答:应该是没有被授权的引用链接


















 3457
3457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









