




一、引言
在自然语言处理(NLP)领域,将文本转换为数值表示是众多任务的基石。本文将深入探究几种主流的方法与技术,涵盖Word2Vec、BERT和BGE,并剖析如何将词向量转换为句子向量,旨在为相关研究与实践提供全面且深入的参考。
二、Word2Vec:基于上下文的词向量生成框架
(一)核心思想
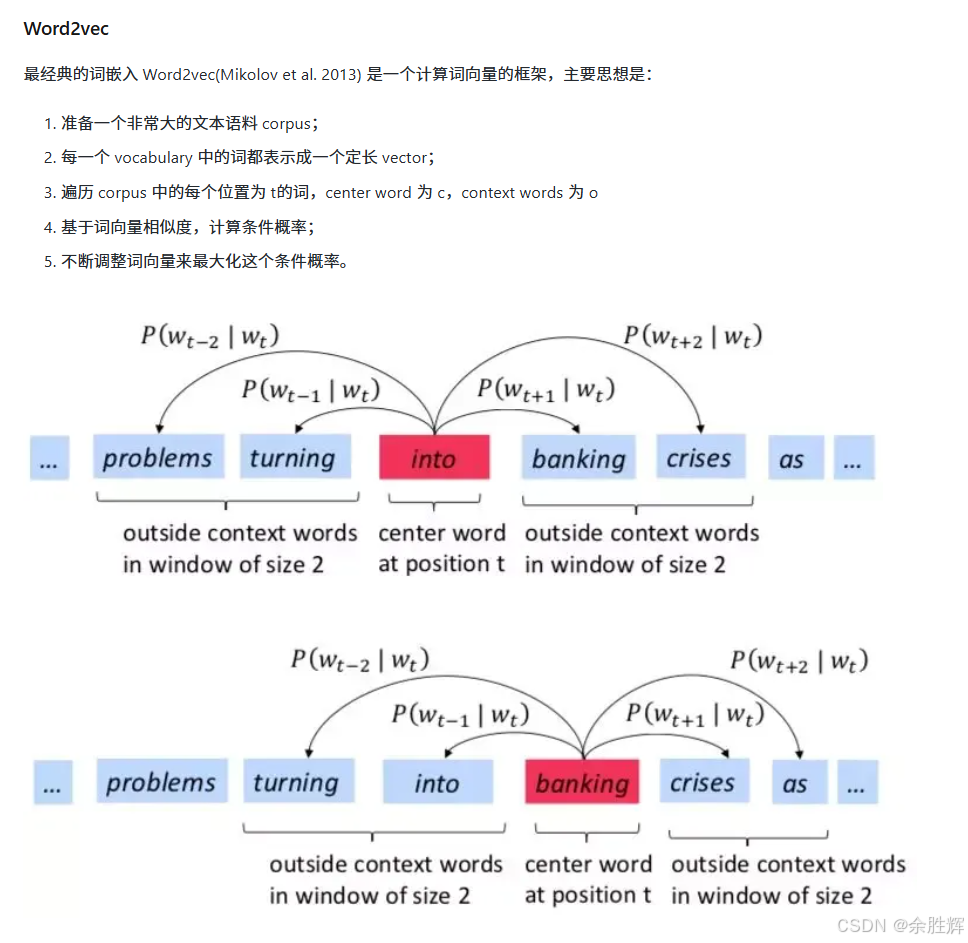
Word2Vec作为一种计算词向量的框架,其理论根基是Vector Semantics中的distributional hypothesis,即词的语义由其在相似上下文中的出现频率所界定。其核心运作机制为:
- 筹备大规模文本语料库:将词汇表内的每个词映射为定长向量。
- 遍历语料库中每个词的位置:基于词向量的相似度计算条件概率。
- 持续优化词向量:以实现该条件概率的最大化。
从本质上讲,Word2Vec是一个双层神经网络,以文本语料作为输入,输出为一组表征语料中词语特征的向量。其目的在于向量空间内依据相似性对词向量进行聚类,能够精准识别数学层面的相似性,生成的向量能够以分布式数值形式有效表征词的上下文等关键特征,且无需人工手动干预。
(二)Skip-gram与CBOW模型
Word2Vec主要有两种实现模式:
-
Continuous Bag of Words (CBOW):此模型采用周围词预测中心词的策略,具有训练速度较快的优势。它充分利用周围词的信息,通过对周围词向量的综合处理来推测中心词,从而在大规模语料训练时能够高效地更新词向量。
-
Skip-gram:该模型则是运用中心词预测周围词,尤其擅长处理生僻字。在面对大规模数据集时,其预测结果的准确性更为突出。它侧重于从中心词出发,探索其与周围词的语义关联,通过大量的预测训练,使得词向量能够更精准地捕捉词与词之间的语义关系。
在Word2Vec中,通过计算词的余弦相似性来衡量词之间的关联程度。当余弦值为0(对应90度角)时,表示无相似性;而余弦值为1(对应0度角)时,则表示完全相似。借助这种方式,成功实现了词的“向量化”,让自然语言能够被计算机有效读取与处理,并能够对词语开展复杂的数学运算,进而精准识别词之间的相似性。
(三)训练过程示例
生成One-Hot向量
import numpy as np
# 假设词表中有5个词,这里生成 "apple" 的 One-Hot 向量
word_index = 0 # 假设 "apple" 在词表中的索引为0
vocab_size = 5
one_hot_vector = np.zeros(vocab_size)
one_hot_vector[word_index] = 1
print(one_hot_vector)使用Word2Vec生成词向量
from gensim.models import Word2Vec
# 假设已经训练好的Word2Vec模型
model = Word2Vec.load('your_word2vec_model.bin')
sentence = "This is a sample sentence."
tokens = sentence.split()
vectors = [model.wv[token] for token in tokens if token in model.wv]
sentence_vector = np.mean(vectors, axis=0)
print(sentence_vector)在训练过程中,若某词的特征向量无法精准预测其上下文,模型会相应调整向量要素。语料库中每个词的上下文如同“老师”一般,会传回误差信号以驱动特征向量的调整优化。经过训练,相似词的向量在向量空间内会逐渐靠近,相似的事物与概念亦会在向量空间中呈现“邻近”态势,从而将语义的相对关系转化为可量化的距离,为算法的有效运行奠定基础。
三、BERT:双向编码器表示
(一)核心思想
BERT(Bidirectional Encoder Representations from Transformers)采用双向Transformer架构,在自然语言理解任务中表现卓越。它借助遮盖语言模型(Masked Language Model,MLM)和下一句预测(Next Sentence Prediction,NSP)两大训练策略进行预训练。其双向性的独特设计使得模型能够同时兼顾词左侧和右侧的上下文信息,极大地增强了对文本语义的理解能力。
BERT属于基于上下文的嵌入模型,能够依据词所在的上下文生成不同的向量表示,从而有效区分同一词在不同语境下的语义差异。例如,“bank”一词在“金融银行”语境和“河岸”语境中,BERT能够生成截然不同的向量来准确表征其语义。
(二)预训练策略
-
掩码语言模型(MLM):类似于完形填空任务,随机选取输入句子中的部分词并将其遮蔽,然后预测这些被遮蔽的词。这种训练方式促使模型深入理解句子的整体语义和语法结构,因为它需要依据上下文信息来推测被遮蔽词的可能性。
-
预测下一句(NSP):该任务旨在预测第二句是否与第一句在语义上连贯。具体操作是通过使用分类层将[CLS]标记的输出转换为2×1形状的向量,随后运用SoftMax函数计算第二句是否跟在第一句后面的概率。例如,对于句子对“今天天气真好。”“我打算出去散步。”和“今天天气真好。”“明天可能会下雨。”,模型能够通过NSP任务学习到句子之间的逻辑关联和语义连贯性。
BERT的预训练是迁移学习理念的典型应用。首先利用海量数据训练得到泛化能力强劲的预训练模型,然后针对特定任务,使用特定数据进行增量训练并精细调整权重,以实现对特定场景的完美适配。BERT由多层的Transformer编码器堆叠而成,每一层均包含自注意力机制(Self-Attention)和前馈神经网络。自注意力机制能够让模型动态地关注输入文本的不同部分,从而捕捉从浅层语法特征到深层语义特征的多级别语言信息。
(三)应用示例
使用BERT进行文本分类
from transformers import BertTokenizer, BertForSequenceClassification
import torch
# 加载预训练的BERT tokenizer和模型
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
# 输入文本
text = "This is a great movie."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
logits = output.logits
predicted_class = torch.argmax(logits, dim=1).item()
print(f"预测类别: {predicted_class}")使用BERT的MLM功能
from transformers import BertTokenizer, BertForMaskedLM
# 加载预训练的BERT tokenizer和模型
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForMaskedLM.from_pretrained('bert-base-uncased')
# 输入文本,其中有一个词被替换为[MASK]
text = "I [MASK] to the park."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
logits = output.logits
mask_token_index = torch.where(encoded_input['input_ids'] == tokenizer.mask_token_id)[1]
masked_token_logits = logits[0, mask_token_index, :]
predicted_token_index = torch.argmax(masked_token_logits, dim=-1)
predicted_token = tokenizer.decode(predicted_token_index)
print(f"预测的词: {predicted_token}")四、BGE:高质量文本嵌入模型
(一)核心思想
BGE(Beijing Academy of Artificial Intelligence General Embedding)是由北京智源人工智能研究院开发的一系列高质量文本嵌入模型。BGE家族的新成员BGE-M3支持超过100种语言,在多语言、跨语言检索领域展现出领先优势。该模型能够全面且高质量地处理“句子”、“段落”、“篇章”、“文档”等不同粒度的输入文本,最大输入长度可达8192,并创新性地一站式集成了稠密检索、稀疏检索、多向量检索三种检索功能,在多个评测基准中均达到最优水平。
BGE作为首个集多语言(Multi-Linguality)、多粒度(Multi-Granularity)、多功能(Multi-Functionality)三大技术特征于一体的语义向量模型,极大地提升了语义向量模型在现实世界的实用性与可用性。其相关模型还包括BGE-re-ranker、BGE-re-ranker-m3(主要用于实现精准排序功能)、BGE visualized(重点拓展视觉数据处理能力,实现多模态混合检索功能)、BGE-ICL(首次赋予向量模型上下文学习能力,可依据用户意图灵活适配下游任务)。BGE模型在Hugging Face月度榜单中荣登榜首,总下载量超数亿次,是当前下载量最多的国产AI系列模型之一。
BGE遵循开放的MIT许可协议,社区用户能够自由地使用、修改并进一步分发其模型权重、推理及训练代码、训练数据,这使得BGE在国内外各主流云服务和AI厂商中得到了广泛的集成与应用,形成了较高的社会商业价值。
(二)应用示例
from sentence_transformers import SentenceTransformer
# 加载BGE模型
model = SentenceTransformer('BAAI/bge-base-en')
# 输入文本
text = "This is a sample sentence."
vector = model.encode(text)
print(vector)五、从词向量到句子向量
将一句话转换为向量主要有以下几种方法:
(一)Word2Vec
- 平均词向量法:先利用Word2Vec将句子中的每个token转换为向量,然后对这些向量求平均值,最终以该平均向量代表整个句子。这种方法简单直观,能够在一定程度上反映句子的整体语义,但可能会忽略词序等信息。
(二)BERT
- 平均词向量法:与Word2Vec类似,先通过BERT将句子中的每个token转换为向量,再计算这些向量的平均值作为句子向量。
- [CLS]标记向量法:将句子输入BERT模型后,取BERT输出层第一个位置(即[CLS]标记)对应的向量作为句子向量。该向量在模型预训练过程中经过了对整个句子的语义信息整合,能够较好地代表句子的整体语义。
- 池化层向量法:借助BERT的
outputs_source.pooler_output,获取经过最后一层所有隐藏状态池化后的结果作为句子向量。这种方法能够综合考虑句子中各个词的信息以及它们之间的关系,从而生成更具代表性的句子向量。
(三)M3E、BGE
借助SentenceTransformer工具,可以直接读取编码器的最后一层隐藏层状态或池化层的结果,以此获取句子向量。这种方式能够充分利用模型对文本的深度理解能力,生成高质量的句子向量。
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('your_model_name')
sentence = "This is a sample sentence."
vector = model.encode(sentence)
print(vector)六、总结
本文全面且深入地阐述了几种常用的文本表示方法,包括Word2Vec、BERT和BGE,并详细探讨了如何将词向量转换为句子向量。Word2Vec以其简洁高效的框架在词向量生成方面有着广泛应用,尤其适用于大规模语料的初步处理;BERT凭借双向Transformer架构和创新的预训练策略,在自然语言理解的众多复杂任务中表现卓越;BGE则以其多语言、多粒度、多功能的特性在实际应用场景中展现出强大的适应性和实用性。
然而,每种方法都有其优势与局限性,在实际项目中,需要根据具体任务需求、数据特点以及计算资源等因素综合考量,灵活选择合适的文本表示方法与向量转换策略,以实现最优的效果。未来,随着技术的不断发展,这些方法有望进一步融合与创新,为自然语言处理领域带来更多的突破与进步。

















 2578
2578

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









