




 本文介绍了Deep Speaker神经说话人嵌入系统,它将语音映射到超球面,用余弦相似性衡量说话人相似性。文中测试了ResCNN和GRU两种模型结构,使用三种损失函数。在三个数据集上实验,结果显示该系统优于ivec基准系统,普通话训练模型可提升英语识别准确度,还探讨了多种因素对系统性能的影响。
本文介绍了Deep Speaker神经说话人嵌入系统,它将语音映射到超球面,用余弦相似性衡量说话人相似性。文中测试了ResCNN和GRU两种模型结构,使用三种损失函数。在三个数据集上实验,结果显示该系统优于ivec基准系统,普通话训练模型可提升英语识别准确度,还探讨了多种因素对系统性能的影响。
论文
论文:Deep Speaker: an End-to-End Neural Speaker Embedding System
摘要
我们提出了Deep Speaker,一个神经说话人嵌入系统,它把语音映射到一个超球面上,使用余弦相似性来衡量说话人相似性。Deep Speaker产生的嵌入可以用于许多任务中,包括说话人验证、识别和聚类。我们在实验中使用ResCNN和GRU结构去提取声学特征,然后是均值池化产生话语级的说话人嵌入,训练中使用了基于余弦相似性的三元组损失。在三个不同数据集上的实验表明Deep Speaker胜过了基于DNN的ivec基准系统。我们提出的结果还表明一个使用普通话数据集训练的模型可以提升对英语说话人识别的准确度。
模型结构
本文提出测试了两种模型结构ResCNN和GRU,并且分别使用三种损失函数,softmax、triplet和softmax (pre-train) + triplet。
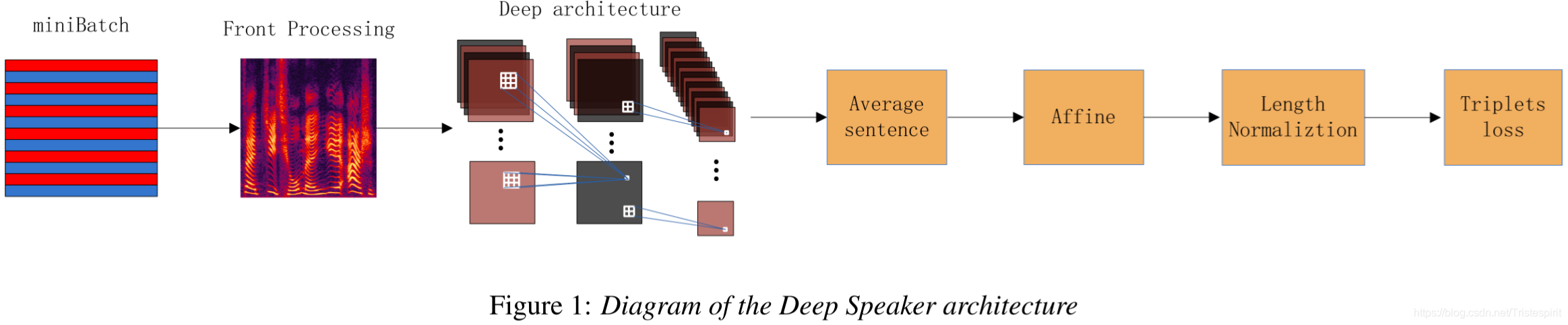
图1就是Deep Speaker的结构。本文使用两种不同的核心结构:一个ResNet style deep CNN和Deep Spech 2-style结构(几个卷积层加上GRU层)。最后的triplet loss把相同说话人嵌入的余弦相似性最大化,不同说话人嵌入的余弦相似性最小。
神经网络结构
Residual CNN
虽然深度神经网络比浅层神经网络有更大的容量,但是往往也更加难以训练。残差网络可以缓解非常深的卷积神经网络的训练,它由若干堆叠的残差块组成。每一个残差块包含了从更低层输出到更高层输入的直接连接,如图2:

这个残差块可以用下面的式子定义:

其中x和h是输入和输出,F是堆叠的非线性层的映射函数,注意x的恒等连接没有增加任何额外的参数和计算复杂度。

表1展示了提出的ResCNN结构的细节,就如图1中所描述的,残差块中包含了两个卷
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1202
1202

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









