




在数据分析的过程中,少不了对DataFrame的列进行聚合分组,如求均值、最大值、最小值、计数、求和等。
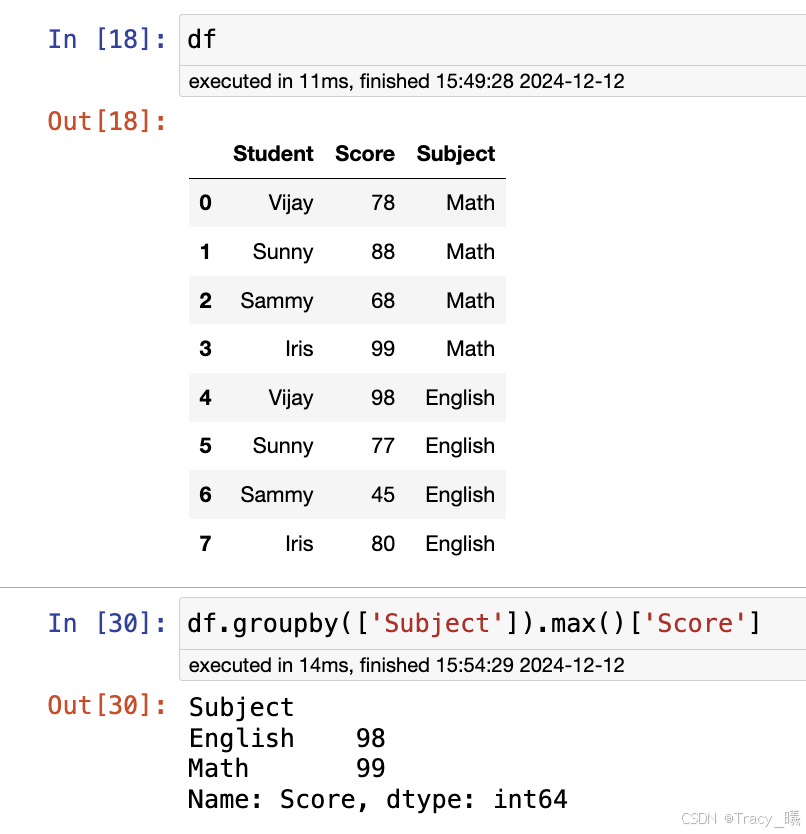
1.groupby()是针对DataFrame中特定的列进行聚合,类似于SQL中group by操作。
select max(Score),Subject from score_table group by Subject
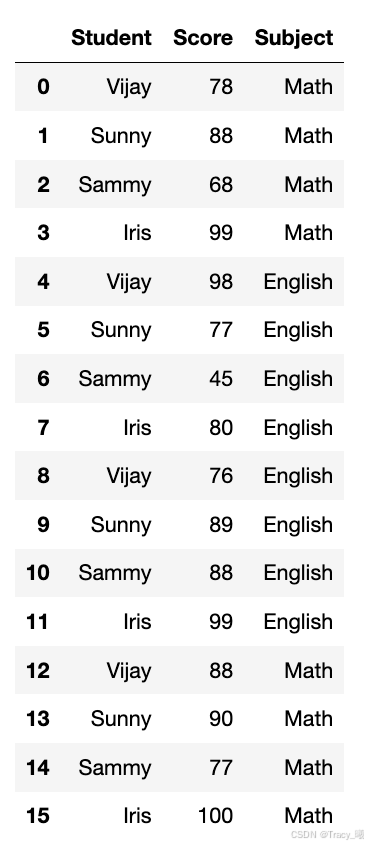
2.pivot_table()用于汇总二维下的数据聚合操作。例如上述例子中,如果我们有多次数学和英语测试的分数,想看每个同学每门科目下的最好的分数,就需要使用数据透视表来进行聚合分组。
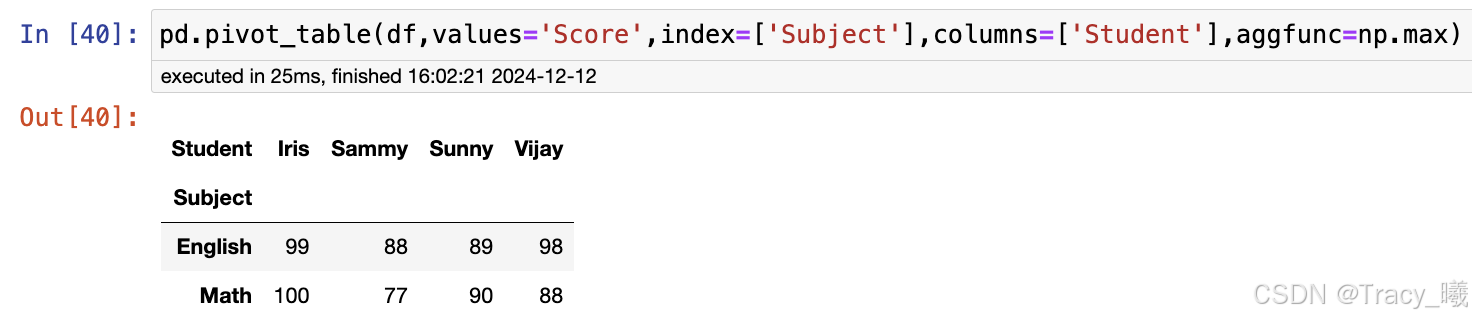
总结一下,使用groupby()时需要想明白针对哪一列分组,针对哪一列数据计算聚合值;使用pivot_table()时需要想明白表格最终呈现出来的样子,横标签为哪一列,纵标签为哪一列,以此为最基础的理解然后展开更为复杂的分析结果。

















 1045
1045

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









