




 这篇博客探讨了垃圾回收中的复制算法,包括基础实现、Cheney的GC复制算法和近似深度优先搜索方法。复制算法具有高吞吐量、无碎片等优点,但也存在堆使用效率低和不兼容保守式GC的问题。Cheney算法通过迭代解决了递归可能导致的栈溢出,而近似深度优先搜索则平衡了内存空间局部性和缓存友好性。多空间复制算法则是复制算法与MarkSweep的结合,旨在缓解一些缺点。
这篇博客探讨了垃圾回收中的复制算法,包括基础实现、Cheney的GC复制算法和近似深度优先搜索方法。复制算法具有高吞吐量、无碎片等优点,但也存在堆使用效率低和不兼容保守式GC的问题。Cheney算法通过迭代解决了递归可能导致的栈溢出,而近似深度优先搜索则平衡了内存空间局部性和缓存友好性。多空间复制算法则是复制算法与MarkSweep的结合,旨在缓解一些缺点。
整体思路是,将堆分为二等份,当其中一份分配不够时,启动 GC 递归从根节点出发(深度优先),将对象拷贝到另外一半,然后将原先部分全部回收。循环往复。
考虑到对象被引用的复杂性,只有当一个对象被 完全拷贝 完成以后,才会更新指向其的地址。
基础实现
代码
type object struct {
isCopied bool // 用来标记是否已经被复制过
forwarding *object // 在完成拷贝之前,是不能更新对该 obj 的引用的。这是一个暂存的地方
size int
children []*object
data interface{}
}
func copy(obj *object) *object {
if !obj.isCopied {
copy_data(heapStart, obj, obj.size)
obj.isCopied = true
obj.forwarding = heapStart
heapStart += obj.size
for i, child := range obj.Children {
obj.children[i] = copy(child)
}
return obj.forwarding
}
return obj
}
优点
- 吞吐量大(只搜索和复制活动对象,相比 mark-sweep 整体堆扫描,快的多。堆越大,差距越明显)
- 可实现高速分配(不需要空闲列表,就顺着块移动就好)
- 不会发生碎片(复制到了集中的地方,此种现象被称为 压缩, 而 mark-sweep 不允许对象移动,所以必然会产生碎片)
- 与缓存兼容(递归复制,空间局限性要好,对缓存的预读机制比较友好)
缺点
- 堆使用效率低(多空间复制算法)
- 不兼容保守式 GC 算法(挪动了对象位置)
- 递归调用函数(可能会引发栈溢出)
针对 缺点 1,有多空间复制算法可以缓解
针对 缺点 3,有 Cheney 算法 以及 近似深度优先算法 缓解
Cheney 的 GC 复制算法
相比标准的 GC 复制算法,该算法不使用递归函数(解决掉一个缺点),而是迭代函数。
这个算法更多是针对复制算法工程上的改进,将递归调用(深度优先)变成了遍历调用(广度优先)。代码中先初始化了扫描以及空闲部分的起点,然后通过拷贝根引用,使两者之间拉开差距,然后这个差距就形成的一个队列机制(很巧妙的队列机制),后面不停遍历该队列(scanStart++),同时将新节点加入到队列尾部(freeStart++),一直到最后完成,两者相等,该 GC 流程就完成了。
代码
type o struct {
children []*o
}
func CheneyGC() {
heapSize := 100
root := make([]*o, 10)
heap := make([]o, heapSize)
freeStart := 50
scanStart := 50
myCopy := func(src *o) *o {
heap[freeStart] = *src
p := &heap[freeStart]
freeStart++
return p
}
// 假设 heap 前面已经满了,现在要进行复制拷贝
for i := range root {
root[i] = myCopy(root[i])
}
for {
if scanStart != freeStart {
for i := scanStart; i <= freeStart; i++ {
for ci := range heap[scanStart].children {
heap[freeStart] = *myCopy(heap[scanStart].children[ci]) // 拷贝值
heap[scanStart].children[ci] = &heap[freeStart] // 修改引用
freeStart++
}
scanStart++
}
}
}
}
优点
- 递归改迭代,消除了可能的栈溢出
- 同时使用堆空间当做队列,省去了内存空间
缺点
- 深度优先修改成广度优先,导致内存空间局部性变差,那么缓存的友好也就消失了
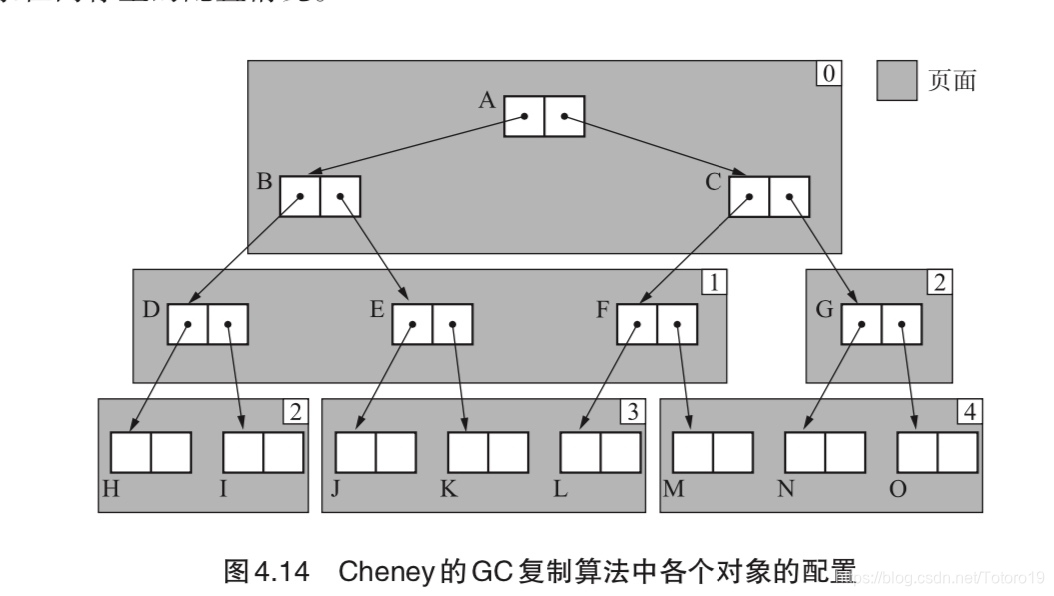
近似深度优先搜索方法
在原生算法中使用的是深度优先,从而对缓存友好,Cheney 则将算法进行改善,从深度优先变成广度优先,虽然消除了递归,但是也将缓存友好的特性给毁的一干二净。
状态
page 将内存分页(大小未必固定)。page[i] 指向第 i 个页面的开头
local_scan 扫描是按页面推进,local_scan[i] 则指向第 i 个页面下一个要扫描的位置(页内偏移)
major_scan major_scan 就是维护搜索尚未完成(第一阶段)的页面开头的指针
free 就是空闲页面的开头位置
执行过程
该算法的执行阶段分为两段执行,
- 通过 major_scan 拿出下一个要扫描的对象,将其移动到 free 指向的页面(深度优先)
- 将上述对象的所有子节点进行移动,移动完成,认为该阶段完成(广度优先)
循环以上过程,最终就可以得到如下的内存分布
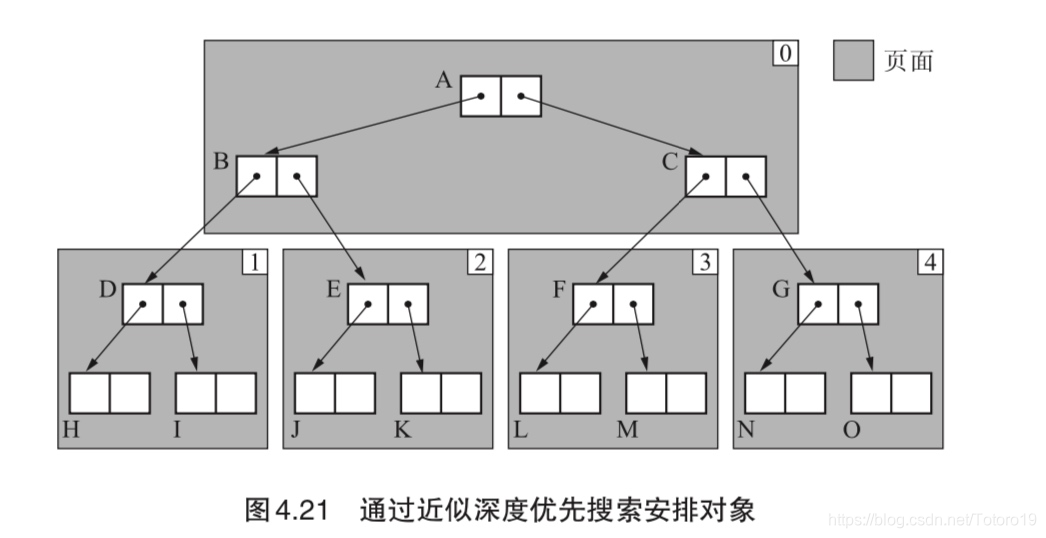
对比 Cheney 的内存分布,对缓存的友好性要好的多
多空间复制算法
多空间复制算法是 复制算法和MarkSweep的一种组合实现。将堆进行 n 等分,然后每次 GC 时,将其中相邻的两块执行复制算法,对于剩余的块则执行 MarkSweep. GC 执行完成以后,下次执行复制的块,就是现在的块往后挪动一块。感觉是一个很难受的实现。

















 1958
1958

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









