







本文只记录HQL语法的特殊之处及SQL语法中不常用但HQL常用的语法内容
HQL
DDL
库操作
创建数据库
CREATE DATABASE [IF NOT EXISTS] database_name
[LOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];
LOCATION:指定数据在HDFS的存放路径,默认在/user/hive/warehouse/*.db
WITH DBPROPERTIES:添加数据库的属性(没什么用)
查看数据库详情
desc database db_hive;(与SQL语法一致)
特殊地:extended 关键字
desc database extended db_hive;(显示数据库详细信息)
修改数据库
修改数据库的属性信息
alter database db_hive set dbproperties('createtime'='20220830');
数据库的其他元数据信息都是不可更改的,包括数据库名和数据库所在的目录位置。
删除数据库
1)删除空数据库(与SQL语法一致)
drop database db_hive2;
2)特殊地:如果数据库不为空,可以采用cascade命令,强制删除
drop database db_hive cascade;
表操作
建表语法
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
[AS select_statement]
[LIKE table_name]
特殊地,
- external关键字:指定该表是外部表
- partitioned by创建分区表
- clustered by创建分桶表
- sorted by不常用,对桶中的一个或多个列另外排序
- row format delimited 指定列的分割条件,Hive使用Serde进行行对象的序列与反序列化。
- stored as指定存储文件类型 常用的存储文件类型:sequencefile(二进制序列文件)、textfile(文本)、rcfile(列式存储格式文件)
- location:指定表在HDFS上的存储位置
- as:后跟查询语句,根据查询结果创建表。
- like允许用户复制现有的表结构,但是不复制数据。
案例:
CREATE TABLE `stadium`(
`id` int,
`visit_date` date,
`people` int
)row format delimited fields terminated by '\t';
上传数据(将符合列分割条件的数据上传到HDFS中该表的存放路径)
hadoop fs -put student.txt /user/hive/warehouse/student
外部表:删除该表并不会删除掉这份数据,不过描述表的元数据信息会被删除掉。
管理表与外部表的互相转换
修改外部表student为内部表
alter table student3 set tblproperties('EXTERNAL'='FALSE');
注意:(‘EXTERNAL’=‘TRUE’)和(‘EXTERNAL’=‘FALSE’)为固定写法,区分大小写
DML
向表中装载数据(Load)
load data [local] inpath '数据的path'
[overwrite] into table student [partition (partcol1=val1,…)];
(1)load data:表示加载数据。
(2)local:表示从本地加载数据到Hive表;否则从HDFS加载数据到Hive表。
(3)inpath:表示加载数据的路径。
(4)overwrite:表示覆盖表中已有数据,否则表示追加。
(5)into table:表示加载到哪张表。
(6)student:表示具体的表。
(7)partition:表示上传到指定分区。
案例:
加载本地文件到hive
hive (default)> load data local inpath '/opt/module/hive/datas/student.txt' into table student;
加载HDFS文件到hive中
①上传文件到HDFS
dfs -put /opt/module/hive/datas/student.txt /user/atguigu;
②加载HDFS上数据,导入完成后去HDFS上查看文件是否还存在
load data inpath '/user/atguigu/student.txt' into table student;
加载数据覆盖表中已有的数据
①上传文件到HDFS
dfs -put /opt/module/hive/datas/student.txt /user/atguigu;
②加载数据覆盖表中已有的数据
load data inpath '/user/atguigu/student.txt'
overwrite into table student;
insert也可使用overwrite 关键字,insert overwrite table student3
数据导出
Insert导出
1)将查询的结果导出到本地
insert overwrite local directory '/opt/module/hive/datas/export/student' select * from student;
2)将查询的结果格式化导出到本地
insert overwrite local directory '/opt/module/hive/datas/export/student'
row format delimited fields terminated by '\t'
select * from student;
3)将查询的结果导出到HDFS上(没有local)
insert overwrite directory '/user/atguigu/student2'
row format delimited fields terminated by '\t'
select * from student;
Export导出到HDFS
export table default.student to '/user/hive/warehouse/export/student';
Import数据到指定Hive表中
注意:先用export导出后,再将数据导入。并且因为export导出的数据里面包含了元数据,因此import要导入的表不可以存在,否则报错
import table student2 from '/user/hive/warehouse/export/student';
DQL
语法:
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference -- 从什么表查
[WHERE where_condition] -- 过滤
[GROUP BY col_list] -- 分组查询
[HAVING col_list] -- 分组后过滤
[ORDER BY col_list] -- 排序 统称为hive中4个by
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY col_list]
]
[LIMIT number] -- 限制输出的行数
特殊地,
满外连接
满外连接:将会返回所有表中符合where语句条件的所有记录。如果任一表的指定字段没有符合条件的值的话,那么就使用null值替代。
hive (default)>
select
e.empno,
e.ename,
d.deptno
from emp e
full join dept d
on e.deptno = d.deptno;
联合
union&union all上下拼接
union去重,union all不去重
排序
每个Reduce内部排序(Sort By)
1)设置reduce个数
hive (default)> set mapreduce.job.reduces=3;
2)查看设置reduce个数
hive (default)> set mapreduce.job.reduces;
3)根据部门编号降序查看员工信息
hive (default)>
select
*
from emp
sort by deptno desc;
分区排序(Cluster By)
当distribute by和sort by字段相同时,可以使用cluster by方式。
cluster by除了具有distribute by的功能外还兼具sort by的功能。但是排序只能是升序排序,不能指定排序规则为asc或者desc。
(1)以下两种写法等价
hive (default)>
select
*
from emp
cluster by deptno;
hive (default)>
select
*
from emp
distribute by deptno
sort by deptno;
子查询
特殊地,
with语法
与子查询相似,便于阅读
查询各部门名称和人数:
hive (default)>
with t1 as (select deptno,
count(empno) emp_count
from emp e
group by deptno)
select t1.deptno,
d.dname,
t1.emp_count
from t1
join dept d
on t1.deptno = d.deptno;
函数
1)系统的自带函数
hive> show functions;
2)显示自带的函数的用法
hive> desc function upper;
3)详细显示自带的函数的用法
hive> desc function extended upper;
高级聚合函数
collect_list 收集并形成list集合,结果不去重
collect_set 收集并形成set集合,结果去重
炸裂函数
1)explode 将数组或者map展开,posexplode在explode 的基础上多生成一列索引列,索引从0开始,
select explode(array('a','b','d','c'));
结果:
a
b
d
c
select posexplode(array('a','b','d','c'));
结果:
+------+------+
| pos | val |
+------+------+
| 0 | a |
| 1 | b |
| 2 | d |
| 3 | c |
+------+------+
2)json_tuple 取出json字符串中属性的值
select json_tuple('{"name":"王二狗","sex":"男","age":"25"}','name','sex','age');
结果:
王二狗 男 25
注意:炸裂函数和聚合函数一样不支持和普通列一起查询。需要用到侧写
lateral view 侧写
用法::lateral view udtf(expression) tableAlias AS columnAlias
解释:lateral view用于和split,explode等UDTF一起使用,它能够将一行数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合。
select
name,
friend
from employee
lateral view
explode(friends) tbl AS friend;
select
name,
friend
from employee
lateral view
posexplode(friends) tbl AS pos,friend;
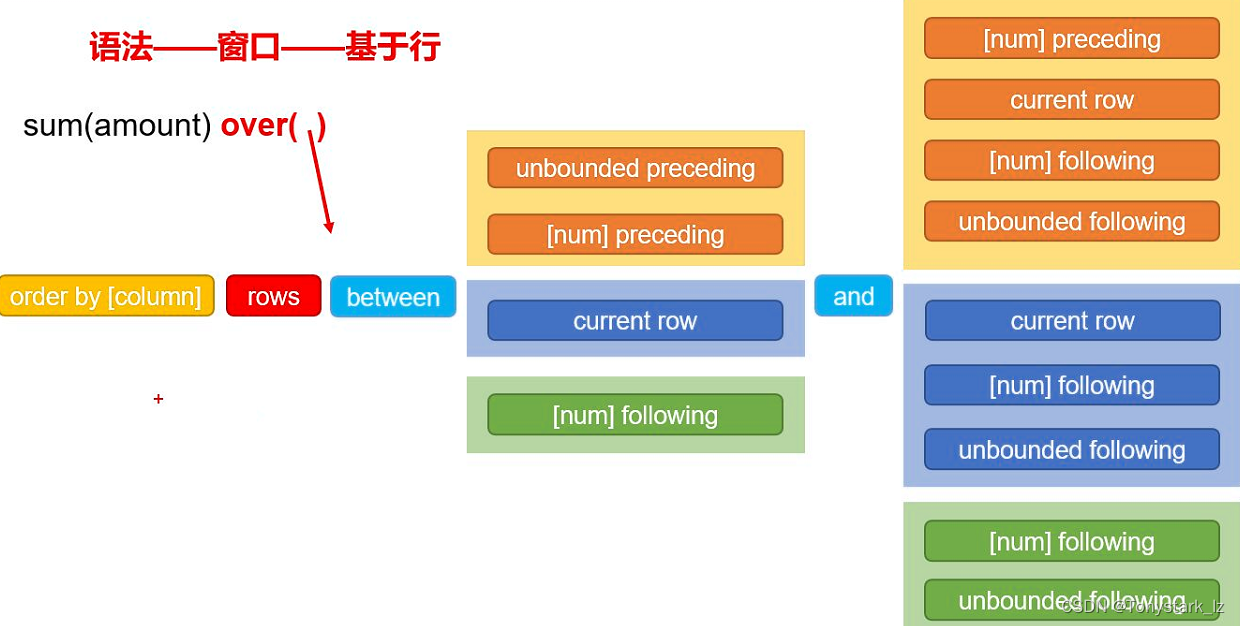
窗口函数(开窗函数)
语法
函数 + over( [partition by …] [order by …] [窗口子句] )
窗口子句:(rows | range) between … and …
范围值:
负无穷: unbounded preceding;
前几列/值:[num] preceding;
当前行/值:current row
后几列/值:[num] following;
正无穷:unbounded following
遵循前小后大
哪些函数是窗口函数
窗口函数
lag(col,n,default_val):往前第n行数据。
lead(col,n, default_val):往后第n行数据。
first_value (col,true/false):当前窗口下的第一个值,第二个参数为true,跳过空值。
last_value (col,true/false):当前窗口下的最后一个值,第二个参数为true,跳过空值。
聚合函数
max:最大值。
min:最小值。
sum:求和。
avg:平均值。
count:计数。
排名分析函数
rank:排名相同时会重复总数不会减少。
dense_rank:排名相同时会重复总数会减少。
row_number:行号。
ntile:分组并给上组号。
select
*
from
(
select
course_id,
stu_id,
score,
rank() over (partition by course_id order by score desc) rk,
dense_rank() over (partition by course_id order by score desc) dense_rk,
row_number() over (partition by course_id order by score desc) rn,
ntile(10) over (partition by course_id order by score desc) nt
from score_info
)t1
where rk<=3;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









