



1.Map
Map是一个接口类,该类中存储的是<K,V>的键值对,并且K是唯一的,不能重复。
它不属于Collection接口。
map中存储的 Key和Value可以是任意类,只要是实现或者重写了equals和hashCode方法的类都可以。
它也是一种存储结构,不过存储的每一个元素是键值对——是由两个值构成的,而不是我们以前经常见到的整数,节点之类的。
1.1Map常见方法
Map<String,Integer> map=new HashMap<>();
map.put("黄色花朵",1);//put方法: 添加键值对
map.put("紫色花朵",3);
map.put("蓝色花朵",5);
map.put("橙色花朵",2);
Integer yellow = map.get("黄色花朵");//get方法:传Key值,得Value值 //输出结果:1
map.remove("蓝色花朵");//删除方法,删除参数Key对应的键值对
Set<String> strings = map.keySet();//获取当前所有key的集合
map.containsKey("黑色花朵");//判断当前map是否包含参数Key 输出结果:false
map.containsValue(3);//判断当前map是否包含参数value 输出结果:true
1.2 Map特性
通过Map类,我们就能很方便的将不同数据之间的关系关联起来,Map本身是一个接口,需要由具体实现类来实现,它的实现类分别是TreeMap和HashMap,其 其中TreeMap的底层其实就是上一篇的二叉搜索树(平衡版)。这个我们后面还会详细介绍。
Map中存放的Key值是不可重复的,Value值可以重复。
TreeMap这个实现类在插入键值对是不允许Key值为空的,会直接抛出空异常,**而HashMap实现类允许Key为空,**这也和它们底层实现方式不同,我们后面也会讲到。
2.Set
Set接口跟Map不太一样:它继承自collection接口。它只存储Key值。
而一样的是:它也需要具体的实现类:分别是TreeSet和HashSet。
由于Set只存储Key值,而Ket值又不可重复,这就使Set有了天然去重的作用。
2.1Set常见方法
Set<Integer> set=new HashSet<>();
set.add(1);//添加元素 若set中已有该元素则添加不会成功
set.add(2);
set.add(3);
set.add(4);
set.add(5);
set.contains(4);//判断参数元素是否在set中 //输出结果:true
int size = set.size();//返回当前set元素的个数 //结果:size==5
set.remove(1);//删除set中的1元素
ArrayList<Integer> list=new ArrayList<>();
list.add(10);list.add(15);list.add(20);list.add(10);list.add(40);
set.addAll(list);//将集合中元素全部添加到set,可以达到去重的效果
2.2Set特性
Set是继承Collection的一个接口类
Set中存储的数据不可重复
Set中的数据不可修改,如果一定要修改,要先删除这个值再插入目标修改值
其实现类TreeSet不能插入null,但HashSet可以。
3.哈希表(HashMap)
当我们在学习顺序结构(顺序表)或者树形结构时,由于value值和其存储位置没有对应的关系,所以我们在进行查找元素时,通常需要将存储的元素与目标值进行多次比对,最终才能找到目标值。
但是有没有另一种可能:我们在存储元素的时候就将元素的位置与其存储值建立关联,通过某个特定公式,这样当我们在查找元素时,只需根据公式就能计算出该元素的存储位置,直接找到该元素,大大提升查找效率。
而这也就是哈希表的基本思想,特定公式也被称为哈希函数。图来:
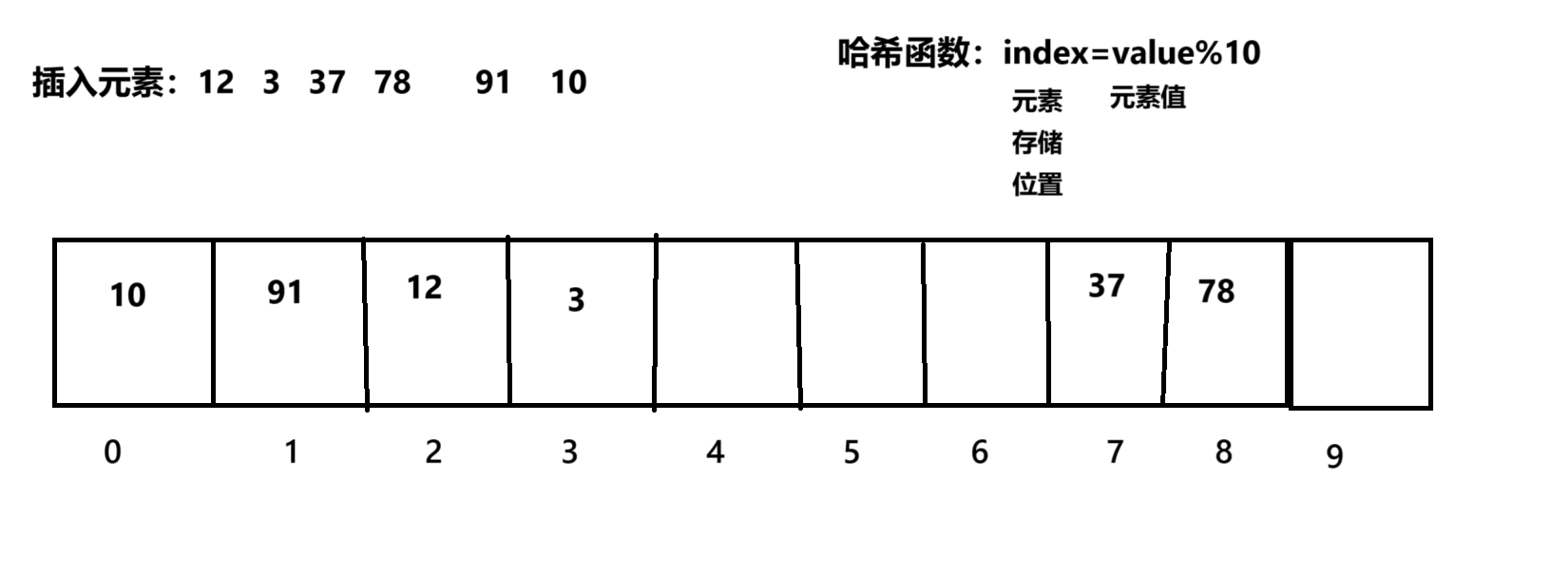
这样的话我们就通过一个公式将元素值跟存储位置关联了起来,假设我们现在要去找37,只需带入哈希函数计算就能得出该元素下标为7,O(1)时间就能找到。
然而问题又来了:如果这时我们再放一个13呢,根据哈希函数计算出存储地址为3,但是这个存储地址已经有元素了呀,这不就冲突了?对 这就是哈希冲突:不同的元素通过哈希函数计算出了相同存储地址。
另外,我们把计算出的相同存储地址的不同元素称为“同一词”。
那么问题就在于如何尽量避免哈希冲突?(注意:哈希冲突是无法完全避免的,我们只能尽量降低概率)
3.1避免哈希冲突
引起哈希冲突的一个原因可能是哈希函数设计不够合理
哈希函数的设定原则:
1.哈希函数的的定义域必须包括所有要存储的 元素
2.哈希函数计算的地址应该能均匀的分布在整个空间
3.哈希函数应该尽量简单
我们常见的哈希函数有两种:
1.Hash(Key)=A*Key+B,优点是比较简单,方便,缺点是需要事先知道元素的分布情况
2.Hash(Key)=Key%M M是最接近地址数的质数。
另一原因就是负载因子,负载因子=放入地址元素的数量/地址数。(比如地址数是10,我放了5个元素,负载因子就是0.5).
我们要明确:负载因子和哈希冲突率是完全成正比的,所以我么也可以通过降低负载因子来变相降低哈希冲突。
但是放入地址中元素是不可控的,所以我们能做的就是扩大地址数。
3.2解决哈希冲突
以上我们讲的都是降低哈希冲突率的,但是当哈希冲突真的发生,我们又如何应对呢?
常见方法也有两种——闭散列和开散列
3.2.1闭散列
闭散列(开放地址法):就是说当哈希冲突真的发生,如果当前哈希表还未被装满,那么必然又空余位置,我们就将该元素方法下一个“空”的位置中。
但是关键在于如何寻找下一个空位置?我们依然有两种方法:
3.2.1.2 线性探测法
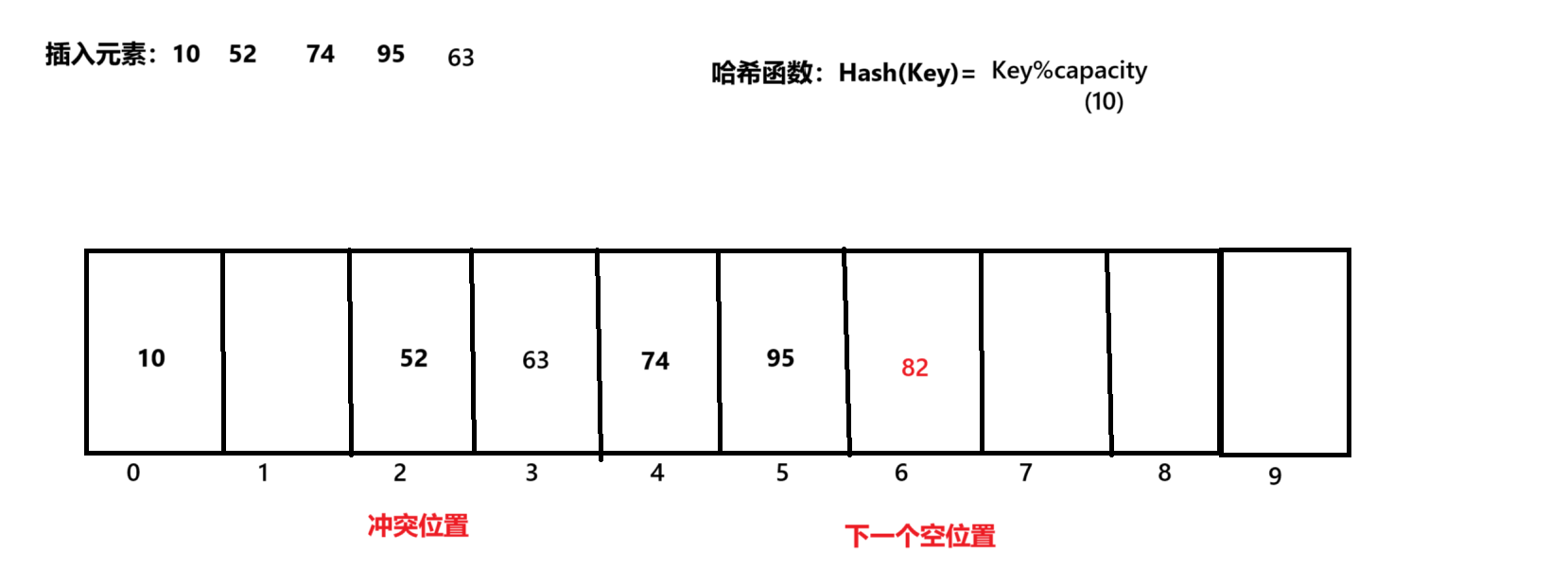
线性探测法就是从当前冲突位置开始,依次延后寻找“空位置”,直到找到位置,放入元素,像一条线一样寻找,如图:
3.2.1.2二次探测法
线性探测法会导致冲突的数据存放位置很相似,上图中如果345位置空着,我又一次性放了5个存储地址为2的元素,那它们就堆在一起了。二次探测法为了避免该缺陷,选择通过一个公式去计算冲突元素的位置在哪放:H(m)=【H(冲突地址)+i平方】%m。i的值由冲突次数决定,第一次就是1,第二次2…以此类推。m就等于原哈希函数中capacity。
3.2.2 开散列——哈希桶
开散列的核心思想就是:首先对关键码集合进行哈希运算,相同存储地址的数据放在一个小集合中(也就是桶),每一个桶中元素通过单链表串联起来,每个桶中的链表的头节点存放在哈希表中。也就是说,我们在搜索元素时只需计算出该元素在哪个桶中然后遍历对应的链表即可,将大集合(哈希表)搜索问题转换成小集合(桶)搜索问题。
可以这样理解:数组加链表:每一个数组元素都是链表的头节点。
3.2.2.1性能分析
如果哈希函数合适,可以认为每一个链表中存放的元素数量是相对均等的,所以我们查找元素遍历长度也可以视作常数,所以可以视为查找时间复杂度为O(1).
4.Tree和Hash
不管是TreeMap还是TreeSet内部都是基于红黑树实现的,红黑树又是基于二叉搜索树实现的,因此当插入元素时需要与树中已有元素进行比较,从而确定插入的位置,这也就是为什么Tree方向的实现类的存储类都需要实现Compareable接口,实现CompareTo方法,哪怕你是个student类,只要给我一个比较的逻辑,我就能给你按我的逻辑存进去。
对于Tree方向,插入 删除 和查找时间复杂度均为O(logN).
Hash方向的实现类则是基于哈希表实现的,而哈希表又是基于哈希桶实现的,所以Hash方向的存储类都需要重写hashcode()方法,保证这个对象能计算出哈希值,从而通过哈希值计算出存储地址,实现Hash的存储逻辑。
同时也需要重写equals方法,这个方法用于比较已存储元素和插入元素是否相等,有这两个方法才能保证Hash方向类正确运行。
对于Hash方向,插入 删除 和查找时间复杂度均为O(1).
4.练习题
4.1只出现一次的数字
题目链接:https://leetcode.cn/problems/single-number
具体思路:这道题使用Map再合适不过,将数组中数字作为Key,出现次数作为Value,第一遍遍历数组将数组数字和出现次数记录下来,完成后肯定有一个Keyd对应的Value是1,接下来只需遍历一下Map找到这个Key并返回即可。具体代码如下:
public static int singleNumber(int[] nums) {
Map<Integer,Integer> map=new HashMap<>();
for(int i=0;i<nums.length;i++){
int number=nums[i];
if(map.containsKey(number)){//如果已经存储该Key,就将出现次数加一
int length=map.get(number)+1;
map.remove(number);
map.put(number,length);
}
else{
map.put(number,1);//妹存储就存进去
}
}
Set<Map.Entry<Integer, Integer>> entries = map.entrySet();
int value=0;
for(Map.Entry<Integer, Integer> s:entries){
value=s.getValue();
if(value==1){
value=s.getKey();//找到Value为1的Key
break;
}
}
return value;//返回
}
4.2随机链表的复制
题目链接:https://leetcode.cn/problems/copy-list-with-random-pointer
具体思路:图来!

具体代码如下:
public static Node copyRandomList(Node head) {
Map<Node,Node> map=new HashMap<>();
Node cur=head;
while(cur!=null&&cur.next!=null){
Node node=new Node(cur.val);
map.put(cur,node);
cur=cur.next;
}
cur=head;
while(cur!=null){
map.get(cur).next=map.get(cur.next);
map.get(cur).random=map.get(cur.random);
}
cur=head;
Node newHead=map.get(cur);
return newHead;
}
4.3宝石与石头
题目链接:https://leetcode.cn/problems/jewels-and-stones
具体思路:我们首先创建一个变量作为“宝石计数器”,然后遍历宝石,将宝石的字符存到set里面,然后遍历石头的每一个字符,判断该字符是否在set中,在就给“宝石计数器”++,最后返回计数器即可,具体代码如下:
public static int numJewelsInStones
(String jewels, String stones) {
int jewelsCount=0;
Set<Character> set=new HashSet<>();
for(int i=0;i<jewels.length();i++){
Character c=jewels.charAt(i);
set.add(c);
}
for(int i=0;i<stones.length();i++){
Character c=stones.charAt(i);
if(set.contains(c)){
jewelsCount++;
}
}
return jewelsCount;
}
THAT’S ALL

















 1450
1450



 到【灌水乐园】发言
到【灌水乐园】发言







