







一、入门知识
(1)基本术语
-
Topic
Kafka将消息种子(Feed)分门别类,每一类的消息称之为一个主题(Topic). -
Producer
发布消息的对象称之为主题生产者(Kafka topic producer) -
Consumer
订阅消息并处理发布的消息的种子的对象称之为主题消费者(consumers) -
Broker
已发布的消息保存在一组服务器中,称之为Kafka集群。集群中的每一个服务器都是一个代理(Broker). 消费者可以订阅一个或多个主题(topic),并从Broker拉数据,从而消费这些已发布的消息。
(2)分区
Topic是发布的消息的类别或者种子Feed名。对于每一个Topic,Kafka集群维护这一个分区的log,就像下图中的示例:
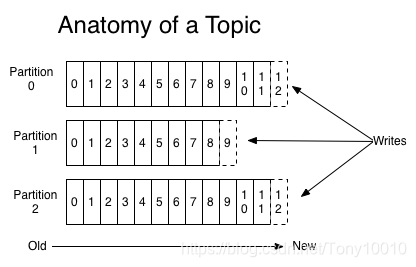
每一个分区都是一个顺序的、不可变的消息队列, 并且可以持续的添加。分区中的消息都被分了一个序列号,称之为偏移量(offset),在每个分区中此偏移量都是唯一的。
Kafka集群保持所有的消息,直到它们过期, 无论消息是否被消费了。 实际上消费者所持有的仅有的元数据就是这个偏移量,也就是消费者在这个log中的位置。 这个偏移量由消费者控制:正常情况当消费者消费消息的时候,偏移量也线性的的增加。但是实际偏移量由消费者控制,消费者可以将偏移量重置为更老的一个偏移量,重新读取消息。 可以看到这种设计对消费者来说操作自如, 一个消费者的操作不会影响其它消费者对此log的处理。 再说说分区。Kafka中采用分区的设计有几个目的。一是可以处理更多的消息,不受单台服务器的限制。Topic拥有多个分区意味着它可以不受限的处理更多的数据。第二,分区可以作为并行处理的单元,稍后会谈到这一点。
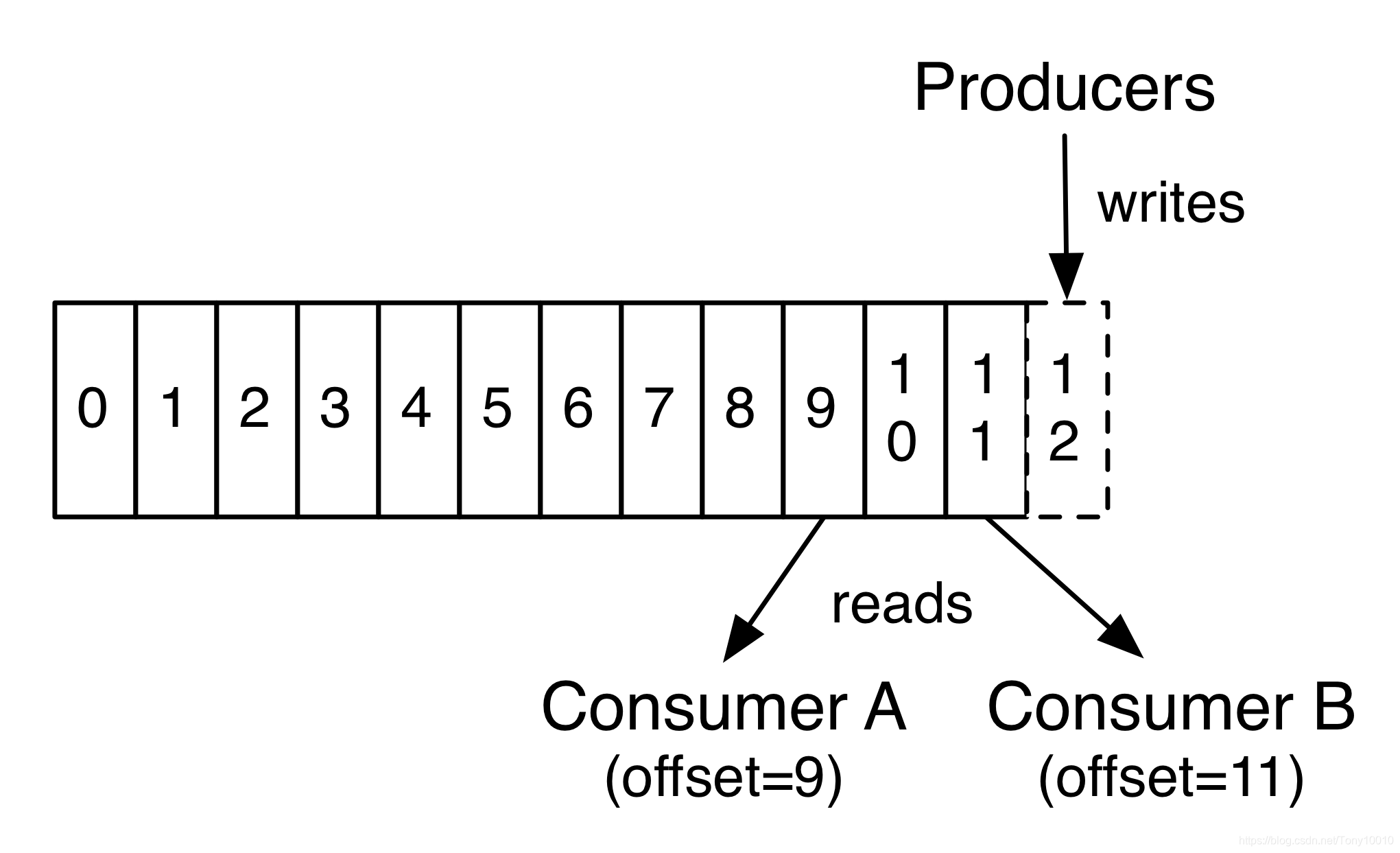
(3)生产者
生产者往某个Topic上发布消息。生产者也负责选择发布到Topic上的哪一个分区。最简单的方式从分区列表中轮流选择。也可以根据某种算法依照权重选择分区。开发者负责如何选择分区的算法。
(4)消费者
通常来讲,消息模型可以分为两种, 队列和发布-订阅式。 队列的处理方式是 一组消费者从服务器读取消息,一条消息只有其中的一个消费者来处理。在发布-订阅模型中,消息被广播给所有的消费者,接收到消息的消费者都可以处理此消息。Kafka为这两种模型提供了单一的消费者抽象模型: 消费者组 (consumer group)。 消费者用一个消费者组名标记自己。 一个发布在Topic上消息被分发给此消费者组中的一个消费者。 假如所有的消费者都在一个组中,那么这就变成了queue模型。 假如所有的消费者都在不同的组中,那么就完全变成了发布-订阅模型。 更通用的, 我们可以创建一些消费者组作为逻辑上的订阅者。每个组包含数目不等的消费者, 一个组内多个消费者可以用来扩展性能和容错。
(5)kafka的流处理
在kafka中,流处理持续获取输入topic的数据,进行处理加工,然后写入输出topic。例如,一个零售APP,接收销售和出货的输入流,统计数量或调整价格后输出。
可以直接使用producer和consumer API进行简单的处理。对于复杂的转换,Kafka提供了更强大的Streams API。可构建聚合计算或连接流到一起的复杂应用程序。
助于解决此类应用面临的硬性问题:处理无序的数据,代码更改的再处理,执行状态计算等。
Sterams API在Kafka中的核心:使用producer和consumer API作为输入,利用Kafka做状态存储,使用相同的组机制在stream处理器实例之间进行容错保障。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









