




这篇文章主要介绍了一个名为 BigBang-Proton 的新型大规模语言模型,它是一个面向科学多任务学习的统一序列架构。该研究旨在解决当前主流大语言模型在理解和处理真实世界科学问题上的局限性。
以下是其主要研究内容的概括:
1. 核心目标
开发一个能够跨尺度、跨结构、跨学科进行多任务学习的科学通用学习器,通过语言引导的计算方式解决从粒子物理到材料科学、基因组学、环境科学等领域的复杂问题。
2. 三大关键创新
-
理论与实验学习范式:将大规模数值实验数据(如粒子对撞参数、材料晶体结构)与文本理论知识对齐,让模型在统一上下文中学习如何用语言解释和指导对数值数据的分析。
-
二进制块编码:替代传统的字节对编码(BPE),直接以字节序列处理所有模态数据(文本、数字、符号),解决了BPE在分词时破坏数字语义和结构的问题,从而实现了高精度的算术运算和大规模数值计算。
-
蒙特卡洛注意力机制:取代标准Transformer的自注意力,通过块间委托机制,使模型的有效上下文长度随层数指数级增长(理论上可达宇宙尺度 10801080),解决了处理超长科学数据序列(如完整基因组、地球系统模型)的计算瓶颈。
3. 验证的性能表现
模型在多个科学领域达到了与专用模型相当甚至更优的性能:
-
算术:50位数加法达到100%准确率。
-
粒子物理(喷注标记):11类分类准确率51.29%,接近专用模型ParticleNet。
-
材料科学(形成能预测):平均绝对误差0.043 eV,优于多个传统机器学习模型。
-
环境科学(湖泊水质预测):在叶绿素-a预测上表现优异。
-
基因组学:在突变功能预测等任务上,斯皮尔曼相关性超过生物学基础模型Evo。
4. 核心结论与更大愿景
-
语言引导的科学计算是可行的:通过统一架构和新的编码方式,单一模型可以在多个科学领域执行分类、回归等任务,而无需为每个任务设计专门架构。
-
结构学习优于长链思维:研究强调,理解物质世界的物理结构(如晶体、DNA、喷注)比纯粹的语言长链推理(COT)对于实现真正的科学理解和AGI更为根本。
-
提出“宇宙尺度预训练”假设:文章大胆假设,预训练的终极极限是宇宙本身。如果将宇宙中所有可观测和可计算的信息(约 10801080 个重子)作为训练数据,模型可能会收敛到支配宇宙的基本物理定律。BigBang-Proton的架构(特别是蒙特卡洛注意力)为这一愿景提供了理论和技术基础。
5. 意义与影响
-
方法论突破:为构建面向真实世界科学的基础模型提供了新的架构范式和训练方法。
-
跨学科统一:挑战了传统科学研究的学科壁垒,展示了用单一模型整合多领域知识的可能性。
-
AGI路径探索:强调了结构学习和物理世界建模在通向AGI道路上的重要性,区别于仅依赖语言推理的现有路径。
-
风险与呼吁:同时指出了这种强大能力在武器设计、军事技术等领域可能带来的严重风险,呼吁建立相应的安全治理框架。
总而言之,BigBang-Proton不仅是一个高性能的科学多任务模型,更是一项旨在重新定义如何利用人工智能进行科学发现、并最终理解宇宙根本规律的前沿探索。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

项目地址在这里,如下所示:
模型地址在这里,如下所示:
摘要
我们介绍 BigBang-Proton,一种基于序列的统一架构,用于在跨尺度、跨结构、跨学科的实世界科学任务上进行自回归语言建模预训练,以构建科学多任务学习器。与主流通用大语言模型相比,BigBang-Proton 融合了三项根本性创新:理论与实验学习范式 将大规模数值实验数据与理论文本语料对齐;二进制块编码 取代字节对编码(BPE)分词;蒙特卡洛注意力 替代传统的 Transformer 架构。通过在混合通用文本语料的跨学科科学数据集上进行下一词预测预训练,随后在下游任务上进行微调和推理,BigBang-Proton 在高达 50 位数的算术加法运算中展现出 100% 的准确率,在粒子物理喷注标记任务中性能与领先的专用模型相当,在原子间势模拟中的平均绝对误差(MAE)与专用模型匹配,在水质预测中性能媲美传统的时空模型,并在基因组建模中取得超越基准的性能。这些结果证明,语言引导的科学计算可以匹配甚至超越特定任务科学模型的性能,同时保持多任务学习能力。我们进一步提出假设,将预训练扩展到宇宙尺度,作为开发物质世界基础模型的关键一步。
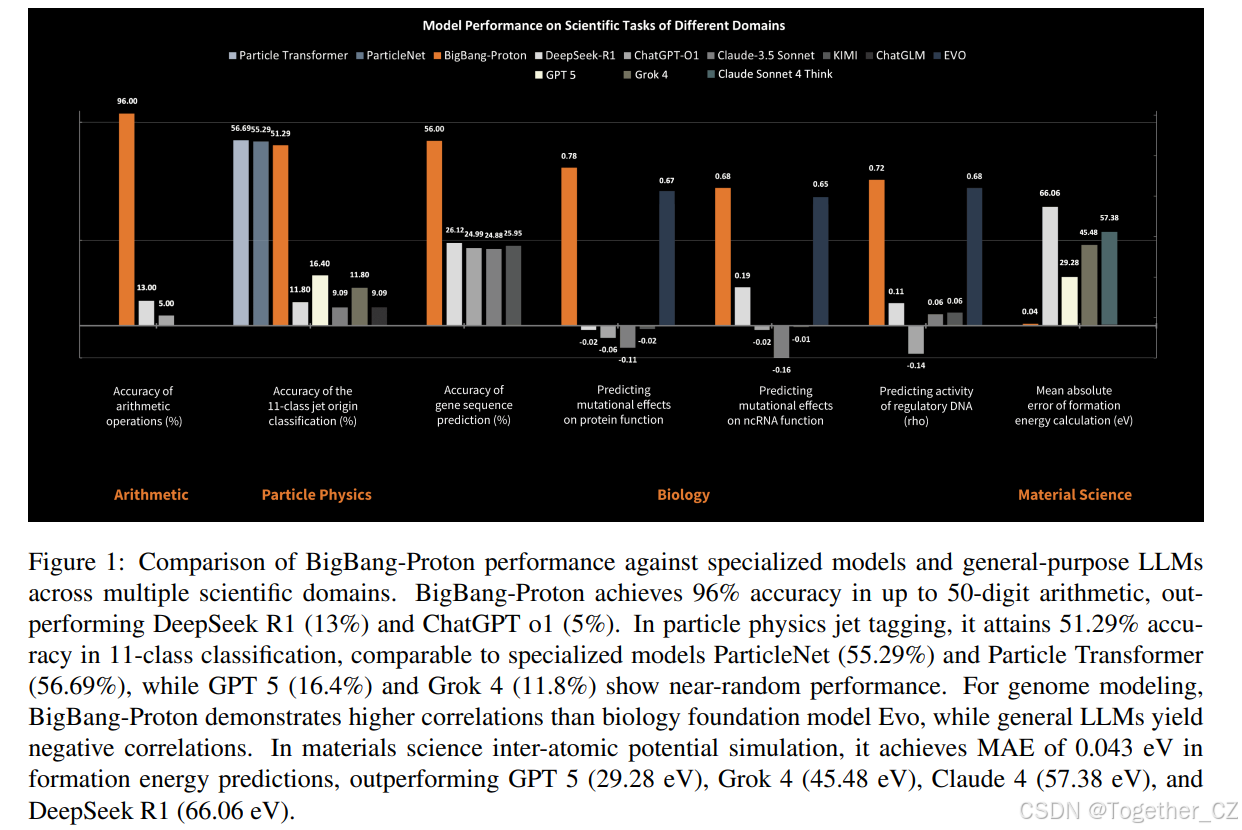
图 1: BigBang-Proton 在多个科学领域与专用模型和通用大语言模型(LLM)的性能对比。BigBang-Proton 在高达 50 位数的算术运算中取得 96% 的准确率,优于 DeepSeek R1 (13%) 和 ChatGPT o1 (5%)。在粒子物理喷注标记中,它在 11 类分类中达到 51.29% 的准确率,与专用模型 ParticleNet (55.29%) 和 Particle Transformer (56.69%) 相当,而 GPT 5 (16.4%) 和 Grok 4 (11.8%) 则表现接近随机水平。在基因组建模中,BigBang-Proton 展现出比生物学基础模型 Evo 更高的相关性,而通用 LLM 则产生负相关。在材料科学的原子间势模拟中,其在形成能预测上达到 0.043 eV 的 MAE,优于 GPT 5 (29.28 eV)、Grok 4 (45.48 eV)、Claude 4 (57.38 eV) 和 DeepSeek R1 (66.06 eV)。
1 引言
大型语言模型通过在基于序列的架构上进行下一词预测预训练[386][287][55][262][129][85][84],已在人类传统执行的各种任务中展现出卓越的通用能力。这些模型在文本生成、编程和标准化考试等领域表现出色,尤其在符合提示-响应框架的场景中,这在诸如 LMSYS Chatbot Arena[72]、MMLU[149]、GPQA[295]、Humanity's last exam[277] 等成熟的基于语言的基准测试中得到了证明。
然而,LLM 迄今为止在解决真实世界科学挑战或产生新的科学见解方面取得的成功有限,因为这些任务通常需要超越传统提示-答案范式的解决方案。旨在模拟人类认知过程的流行评估基准主要局限于多项选择或文本补全格式,这限制了它们在评估 LLM 科学应用潜力方面的应用。LLM 在科学发现中的现有应用可分为以下几类:第一,LLM 被用于搜索、总结和组织科学论文和文档中的信息和知识,作为传统搜索引擎的增强替代。使用经过强化学习后训练(例如 ChatGPT [261] 和 DeepSeek-R1[84])来解决需要长程推理步骤的博士级问题也属于此类。第二,通用 LLM 使用科学数据进行微调以用于特定领域应用,例如 Darwin[381, 380] 和 Matterchat[339]。第三,LLM 使用科学数据在已有模型上或从零开始训练,如 NatureLM[377] 和 Galatica[341] 所示。第四,通用 LLM 被用作生成代码或其他中间输出的工具,而非最终解决方案,如 Funsearch[299] 和 Deepmind 的 AI Co-scientist[127]。值得注意的是,通用 LLM 已应用于符号和语言密集型领域,特别是在数学定理证明方面,这得益于形式化的数据集,包括 LeanDojo[389] 和其他定理证明器 LLM[36][208]。此外,LLM 已被应用于基于理论见解和编程实验的计算机科学研究,例如 Sakana AI[219] 开发的算法。尽管 LLM 在科学研究中的理论驱动型任务中显示出前景,但在解决实验性挑战,特别是在自然科学领域的进展仍然有限。
实验科学的一个重要类别涉及数据驱动计算问题中的数值分析。现代科学研究建立在理论与实验观测之间的相互作用之上,后者经常产生跨越不同学科的定量数据集。尽管在语言推理方面具有优势,主流 LLM 在数值问题解决方面表现出微不足道的能力,这种局限性源于字节对编码(BPE)分词在数值数据表示上的低效性。例如,在算术运算中,对于超过五位数的运算,LLM 的准确率急剧下降至 50% 以下[401]。通过调用外部代码解释器或特定任务算法(如在智能体操作中所见)来规避直接数值计算,进一步证明了 LLM 在实验科学数值分析方面缺乏内在能力。
数值计算能力在包括时间序列分析、表格数据处理和时空建模在内的众多科学领域是不可或缺的。最近的研究越来越关注开发世界模型以解决以语言为中心的预训练的局限性,探索多模态整合,如 Feifei Li 的空间智能[388],或用于物理属性学习的专门架构,如 JEPA[115] 和 NVIDIA 的 Cosmos[20]。然而,这些努力常常忽视一个基本原则:包括空间和时间在内的物理世界的内在属性是定量定义的。未来在模型架构和预训练方法上的进步将需要在数值推理方面取得突破,以使 LLM 能够真正理解世界。
在过去的几十年里,科学界已经开发了多种专门的计算模型来解决特定任务的挑战。著名的例子包括计算生物学中用于蛋白质结构预测的 AlphaFold[173][3],材料科学中用于分子动力学的原子间势模型[406][25],高能粒子物理中的喷注标记算法[285][286],核聚变研究中的等离子体控制系统[87][309],计算流体动力学(CFD)模拟[358],数值天气预报(NWP)模型[296][41],以及用于半导体开发的电子设计自动化(EDA)工具[154]。这些模型采用高度专业化的架构,针对各自领域优化,融入了独特的数据结构和模态。
科学研究在历史上是按学科组织的,这种范式是由人类研究人员的认知和后勤约束塑造的。然而,这种分割与物理现实的相互关联性形成了鲜明对比,现象跨越多个尺度和结构。学科的人为分割导致了物质世界模型的不完整和碎片化,阻碍了跨学科原理的发现。最近关于统一多尺度领域学习的努力主要集中在材料科学和生物医学[377][406],因为材料晶体和生物分子都可以通过源自多体薛定谔方程第一性原理计算的分子动力学来描述。多尺度建模[351, 225, 236, 103, 411, 310] 和多物理场迁移学习[218, 391, 390, 214, 328, 323, 139, 327, 232, 68, 140] 也在计算流体动力学以及土壤和地球系统的地质建模[15] 中进行了探索,通过有限元法[335]、有限体积法、有限差分法、离散元法等数值分析技术求解偏微分方程,目的是构建领域特定的基础模型。然而,这些模型往往局限于各自的领域,通常无法泛化到其他研究领域。因此,迫切需要一种能够跨所有科学学科泛化的基础模型。
为了弥补通用神经网络架构中固有的缺乏领域特定归纳偏置的问题,研究人员引入了物理信息神经网络(PINNs)[289, 290, 22, 69, 188, 170, 113, 243, 70, 405, 124, 157, 291],它们将来自热力学、量子力学的物理原理以及描述某些物理定律的偏微分方程(PDE)、常微分方程(ODE)、随机微分方程(SDE)和对称性与直觉物理学[397, 215, 316, 403, 363, 184, 164, 360] 作为物理先验或约束整合到模型架构、损失函数的正则化项或优化器设计、推理方法[141, 178, 81, 59, 93, 242, 163, 362, 223, 207, 383, 58] 中。虽然这些方法在狭义定义的应用中展示了更好的收敛性,但它们有一个关键局限:其架构的专门化本质上隔离了学习过程,限制了它们的适用性并阻碍了跨学科知识迁移。与 LLM 通过在庞大、多样的语料库[4, 370]上进行预训练来实现多任务泛化和涌现推理能力不同,科学模型仍然局限于特定领域,缺乏一个可扩展、可迁移学习的统一机制。
出于几个原因,一个任务无关的通才架构[287]对于科学发现是必要的。当前特定任务的模型受限于其狭窄的范围,统一的框架可以超越学科界限,使得单一模型能够处理从分子动力学到气候模拟的各种科学任务,而无需重新设计架构。一个通才模型还将通过识别不同领域之间的潜在模式,促进跨尺度、跨结构和跨学科的知识迁移[266, 138, 35],从而加速依赖于看似无关系统之间类比的发现,例如流体中的湍流和星系结构形成。此外,科学知识既存在于语言形式(如理论、假设和出版物)中,也存在于定量形式(如实验和观测数据集)中,统一模型必须将符号推理与数据驱动学习相结合,使得在一个单一的预训练框架内能对两种模态进行直接推理。虽然基于语言的预训练中的缩放定律已开始趋于平稳[142, 11, 161, 228],但它们在科学中的潜力很大程度上仍未得到探索。鉴于物理结构的复杂性,增加模型规模,结合多模态科学预训练,可能导致预测准确性和泛化能力的突破,类似于在大型语言模型中观察到的涌现能力。计算科学的未来在于开发通用的、兼容预训练的架构,这些架构整合跨学科知识,同时尊重领域特定的约束。通过统一语言、数值数据和物理原理,这样的模型可以克服人类定义的学科界限的限制,促进对自然更全面的理解。
在本研究中,我们介绍 BigBang-Proton,一个专为跨多样科学领域的多任务学习设计的通才架构。作为其前身 BigBang-Neutron[375] 的高级迭代,BigBang-Proton 保留了二进制块框架,同时融入了显著的架构增强。所提出的系统利用基于序列的架构[333],通过二进制块编码表示将包括文本、数值和符号科学数据在内的多模态输入转换为字节序列。涵盖粒子碰撞实验中的夸克喷注标记、材料科学中的原子间势模拟、基因组和蛋白质序列结构预测,以及环境工程中的湖泊水质预测的多学科数据集,在理论与实验学习范式的指导下进行整理,并无需定制预处理就连接成一个统一的序列用于下一词预测预训练。这些经过块处理后的表示由蒙特卡洛注意力层处理,该层在计算注意力矩阵的同时,相对于层深度指数级扩展了有效的上下文长度。在推理过程中,科学计算中的传统分类和回归任务通常需要专门的模型架构,例如图神经网络(GNNs),常用于喷注标记[413, 286]和原子间势建模[89, 406]中,这些通常与下一词预测模型不兼容。BigBang-Proton 的前身 BigBang-Neutron[375] 采用经典的大型语言模型架构,包括 Transformer 层和 MLP 前馈网络,并通过调整的 LM 头层来执行分类或回归任务,从而支持语言生成、分类和回归任务。相比之下,BigBang-Proton 统一地通过下一块预测来处理分类和回归,将所有科学任务转化为自回归推理问题。
BigBang-Proton 作为一个统一的多任务学习器运行,使得多样的科学建模任务能够在一个单一的架构框架内被重新表述为序列到-x(其中 x 代表语言、分类、回归、材料结构、DNA、传感器信号等)的学习问题。该模型使用我们的理论与实验学习范式进行预训练,该范式将文本理论知识与大规模实验数值数据集相结合。我们工作的核心贡献包括:
-
本研究首次确立自回归模型能够在真实世界科学研究中跨不同领域执行多任务学习。BigBang-Proton 被设计为一个任务无关的架构,通过将人类语言与包括空间、时间、能量和物质在内的基本物理元素相结合,实现跨尺度、跨结构和跨学科的预训练。使用来自多个科学领域的高度异构数据集构建了超越语言推理和思维链(COT)推理的能力。这项工作首次尝试将物质世界视为一个统一实体来开发用于科学发现、工程、制造、机器人技术和空间智能的基础模型。
-
我们的结果表明,在处理大数字和大规模数值计算方面,二进制块编码明显优于字节对编码(BPE)分词,展示了模拟算术逻辑单元(ALU)操作原理的能力。鉴于科学和工程领域的大多数实验结果都源自以数值数据形式存储的观测和测量,在隐藏空间中有效地表示数字对于构建物质世界的基础模型至关重要。
-
我们证明,通过语言引导的科学计算,BigBang-Proton 在包括粒子喷注标记、原子间表面势模拟、DNA 和蛋白质结构预测以及湖泊水质预测等任务中,取得了超越或媲美最先进的专用模型的性能。
-
我们验证了理论与实验学习框架,它综合了语言知识和实验数据,为解决跨科学学科、领域的语料库差异以及理论与实验之间的鸿沟提供了一种有效的方法。
-
我们的分析表明,BigBang-Proton 能够捕捉粒子喷注、材料晶体和 DNA 序列的完整结构,并能生成相应的伪结构,从而为模型学习日益复杂的结构(如 QCD、细胞系统和地球系统中的结构)铺平了道路。与广泛采用的长程思维链方法相比,结构学习对于理解物质世界至关重要,并且代表了通往人工通用智能(AGI)或人工超智能(ASI)的重要途径。我们的结果表明,长程思维链方法在处理真实世界科学任务时完全失败。
-
我们引入蒙特卡洛注意力作为主流 LLM 中使用的 Transformer 架构的替代方案。蒙特卡洛注意力旨在解决二进制块注意力计算中固有的计算复杂度问题,同时保留稀疏注意力和状态空间模型的优势,后者被认为是 Transformer 的主要替代方案。通过蒙特卡洛注意力,语言模型的上下文长度可以随着注意力层数的增加而指数增长。在本研究中,BigBang-Proton 使用了 20 层蒙特卡洛注意力,实现了 10301030 字节的上下文容量。为了达到可观测宇宙中的重子粒子估计数量 10801080,可以将蒙特卡洛注意力层数设置为 60。如此高的上下文长度对于模型有效地学习复杂的物质结构至关重要,范围从微观系统(如细胞和 QCD 现象)到宏观结构(如地球系统、飞机、汽车和宇宙)。
-
我们的工作说明预训练尚未达到其根本极限。预训练的终极极限是宇宙的边界。这项工作自然而然地推动了对将模型规模扩大到宇宙量级的追求。
BigBang-Proton 的多任务学习性能提供了令人信服的证据,表明尽管不同领域专用科学任务的数据特征和解决方法存在显著差异,但它们可以通过基于序列的自回归端到端学习有效地统一起来。这一发现为开发全面的物质世界基础模型建立了关键基础。所展示的能力表明,一个单一、经过适当设计的架构可以同时实现跨科学学科的广泛应用广度以及与专用解决方案相媲美的性能深度。
2 方法
2.1 语言引导科学计算的理论与实验学习
理论与实验学习范式通过创建一个统一框架,将实验数据与理论知识通过基于序列的学习对齐,从而解决了当前 LLM 在大规模实验数据计算方面的关键局限。核心创新在于建立一个混合表示,直接将数值实验数据与文本描述对齐,借鉴了视觉-语言模型[288, 204, 293, 396, 39, 53]中视觉数据与标题配对的原理。如图 11 所示,例如,在粒子物理喷注标记中,每个末态粒子的数值测量值(电荷、能量、动量分量、碰撞参数等)都与一个文本注释配对,例如“带电π介子”或“中性强子”,形成一个类似于双模态图像-标题对[288]的实验数据-文本对齐。类似地,如图 16 所示,在材料科学中,数值格式的大规模实验或模拟数据集可以系统地转换为自然语言描述,并嵌入理论语境中。例如,对于 Ag₂SnYb 晶体结构,来自原始 MPtrj 格式[89]的原始数值数据,包括晶格矩阵值 [4.9526721, 0.0, 0.0]、[-2.47633605, 4.27679244, 0.00653309]、[0.0, 2.85731761, 4.0453514],原子分数坐标和化学式(Ag₂SnYb)、原子组成(Yb:1 个原子,Sn:1 个原子,Ag:2 个原子)、晶格参数(aa = 4.9527 Å,bb = 4.942 Å,cc = 4.9527 Å,αα = 59.977°,ββ = 90.0°,γγ = 120.0715°)和晶胞体积(85.59 ų),被分解并转换为自然语言描述。这创建了一个统一的序列,其中原始数值与其语义解释共存,使得模型能够学习经验观察与物理意义之间的对应关系。除了这些直接注释之外,该框架还纳入了更深层的理论解释,例如来自 Wikipedia 和研究文献等通用科学语料库的粒子物理中的 QCD 原理、夸克-胶子动力学以及凝聚态物理中的密度泛函理论[192]、电子结构[245]。在预训练期间,这些理论概念被放置在与实验数据序列相同的上下文中,创建了一个具有局部层面直接数据-标题对和全局层面全面理论解释的双重对齐结构。基于序列的自回归语言模型学习实验数据中的模式(这些模式传统上由像 GNNs[413, 89] 或数值分析模型[296]这样的专用模型捕获),并在统一上下文中将数值观察与理论概念对齐,通过集成的模式识别和语言推理实现语言引导的科学计算。总的来说,该范式包含几个关键组成部分。第一,通过文本表示将大规模数值、表格或时间序列实验数据嵌入理论语境中。第二,根据领域特定特征,在预处理阶段控制理论输入和实验输入之间的比例。例如,在粒子碰撞研究中,用于分析的直接实验结果通常是从大量原始二进制数据中压缩而来。第三,采用二进制块编码方法(见 2.3 节)处理语言和数值输入而不失真信息,如先前在 BigBang-Neutron(论文中命名为 BBT-Neutron)[375]中介绍的那样。第四,我们在训练和推理过程中将广泛的科学问题(主要是分类和回归任务,如粒子喷注标记、电子结构计算、基因组结构预测和 PDE 求解)转化为语言引导的计算任务,将其在自然语言语境中框定为下一词预测问题。第五,利用蒙特卡洛注意力(见 2.4.2 节)实现足够大的超长上下文长度,以容纳跨尺度的物质结构。通过将理论建构和实验数据作为序列对齐,理论与实验学习可以实现任务无关和学科无关的跨物理世界不同尺度和结构的预训练和推理,并为构建基础模型(特别是处理大规模实验数据的大科学实验)提供了一个框架,包括高能物理[2]、核物理[237]、宇宙学和天文学[114]、计算流体动力学[358]和生物医学[350]。
2.2 数据集
我们为预训练和后训练阶段精心策划的训练语料库,旨在支持开发一个科学多任务学习器,使其能够跨物理世界(包括自然语言、数学、物理、材料科学、基因组学、传感器动力学、金融和编程)的不同尺度和结构进行推理。该语料库由九个主要数据子集组成,每个子集都旨在灌输领域归纳偏置和特定任务知识,如表 1 所总结:
-
通用文本语料库(SlimPajama) 来源于 SlimPajama 数据集[320],该组件提供了广泛的语言和概念覆盖,包括网络文本、书籍、科学文章和技术问答。它包含 26.7% 的 C4、5.2% 的 GitHub、4.2% 的书籍、4.6% 的 arXiv、3.8% 的 Wikipedia 和 3.3% 的 StackExchange。这种多样化的混合确保了接触通用知识和领域特定的科学文献,为理论与实验学习形成了强大的跨学科理论背景。
-
算术运算 我们生成了 3 亿个合成的算术示例(加法、减法、乘法各 1 亿个),涉及高达 50 位的整数。这些运算使用 Python 的任意精度算术精确计算。在涉及高达 50 位数的算术运算上训练模型在现实世界应用中并不常见。它的设计是为了对模型的数值推理进行压力测试,探究性能差的数值能力源于字节对编码(BPE)分词破坏数字表示的假设。通过用保留数值语义的二进制块编码方法替代 BPE,我们测试是否能够恢复稳健的算术计算,并识别由像 ChatGPT 的 9.11>9.9 错误[210]这样的失败所凸显的根本原因。
表 1:训练数据集概览
| 数据子集 | 字段/元素 | 数据集样本 | 大小(字节) |
|---|---|---|---|
| SlimPajama | 通用文本语料库 | 在强子化过程中,夸克和胶子结合形成强子 | 230B |
| 算术运算 | 加法、减法、乘法 | 123123457457352354 + 7467458472832 = 4+2,5+3,3+8,2+2,... result=123130924915825186 | 1.7B |
| 粒子物理 | ΔηΔη, ΔϕΔϕ, logPilogPi, logElogE | logPilogPi (5.525968, 23.885775, 10.332325),ΔϕΔϕ 3.281097, logElogE 26.604952 | 20B |
| 材料结构 | 原子数、原子质量、原子电荷、原子位置 | NumberOfAtoms:16; Position:[0.94437093 1.87348563 3.77456225], Mass:158.92535, InitialCharge:0.0 | 641M |
| 基因组学 | 基因序列 | TGATTTTTûûûûûACCA TCATTATATTTT TCACCAGCG | 27.2B |
| 传感器 | 光强度、电压、温度、速度 | 3.84322, 350.84631, 25.55369, 0.27954 | 262M |
| 股票价格 | 日期、开盘价、最高价、最低价、收盘价、成交量 | 2023-10-01, 150.25, 152.30, 149.80, 151.90, 2500000 | 60B |
| Python 代码 | 代码片段 | def add(a, b): return a + b # 将两个数字相加的函数 | 1.1B |
| 后训练数据 | 教科书水平和指令数据 | 解释量子力学 量子力学是... | 38B |


将通用人类语言纳入预训练和后训练语料库对于模型开发语言引导科学计算的能力至关重要。这些能力使模型能够解释复杂指令并有效地应用它们来指导科学任务。通过人类语言引导的分类和回归,可以指令模型基于给定的参数,使用自然语言命令对不同的粒子相互作用进行分类或预测材料性质。这种方法弥合了人类理解与计算分析之间的鸿沟,使模型更具通用性,并适用于各种科学领域。有关数据集的更多细节,请参阅附录 A.1。

2.3 二进制块编码
传统的分词器 BPE[308]、sentence piece[196] 和 word piece[305] 被二进制块编码取代,该编码旨在处理多样化的数据模态,包括文本、科学符号、数值数据和图像,确保所有类型的数据得到统一处理。这种方法建立在我们先前的工作[375]以及该领域的其他重要贡献之上,如 BGPT [376]、Megabyte [398]、SpaceByte [317] 和 BLT [265]。这些工作是探索基于字节编码对各种数据类型有效性的先驱性字节级模型。该方法利用了所有数据最终都以二进制格式存储在计算机中这一事实,允许我们一致地处理不同的数据类型。图 2 展示了粒子物理中使用的输入编码方案,最初在我们之前的工作 BigBang-Neutron[375] 中提出。该图直观地展示了不同类型的数据如何被编码成一致的基于字节的格式。
字节对编码(BPE)[308] 及其变体[196, 305] 已被广泛用于文本数据的分词。然而,BPE 在处理数值数据方面存在显著的局限性。字节对编码(BPE)在分词数字时可能引入歧义和不一致性,导致同一数字根据上下文被分割成不同的片段。例如,由于相邻对压缩的机制,相同的数字 12345 可能在一种上下文中被分词为‘12’、‘34’和‘5’,或在另一种上下文中被分词为‘1’、‘23’和‘45’,从而失去了原始数值的固有含义。此外,BPE 导致数值实体的分词 ID 碎片化,例如‘7’和‘8’分别被分配分词 ID 4779 和 5014。分词 ID 的这种不连续性使得数值数据的管理和处理更加复杂,特别是当连续或有模式的分词 ID
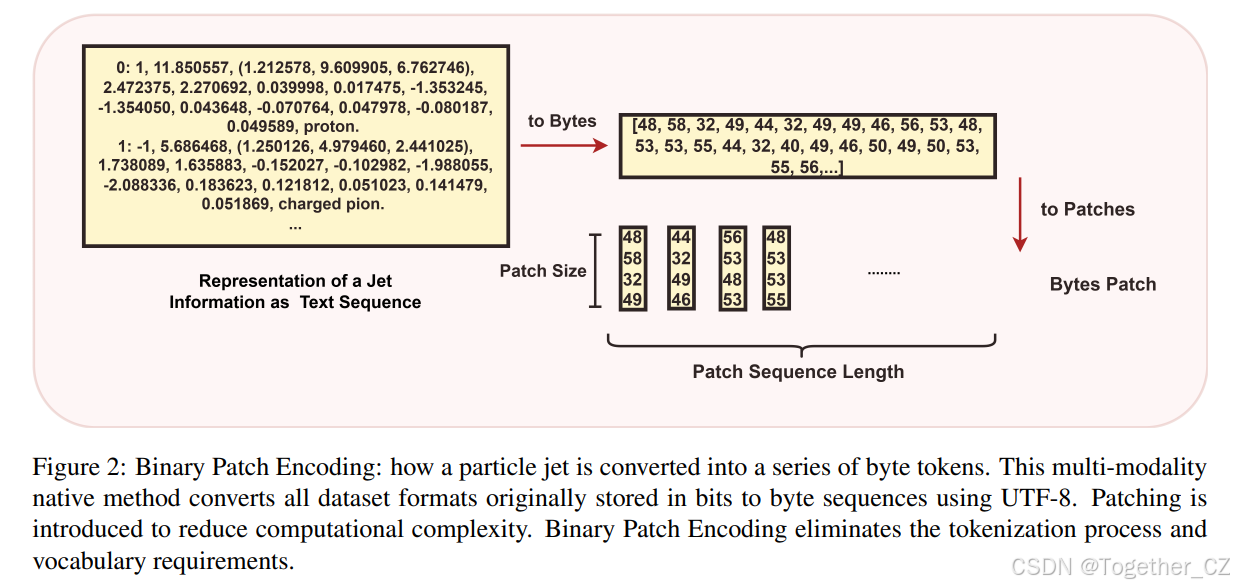
图 2: 二进制块编码:一个粒子喷注如何被转换成一个字节 token 序列。这种原生多模态方法使用 UTF-8 将所有原本以比特存储的数据集格式转换为字节序列。引入分块以降低计算复杂度。二进制块编码消除了分词过程和词汇表要求。
有益时。类似地,单位数分词[97]虽然简单,但也会导致多位数的分词 ID 不连续,例如 15 被分解为单独的分词‘1’和‘5’,每个分词随后被映射到一个独立的分词 ID。这种碎片化可能破坏数值信息的连续性和真实性,可能使得模型更难以捕捉多位数数字内部的固有结构和关系。这些方法并非旨在有效地编码数值,这通常在处理富含数值信息的数据集时导致次优性能(更多讨论见 3.2 节)。这种局限性对我们的跨学科科学模型尤其相关,因为准确处理和理解数值数据(例如金融文档、粒子物理、材料晶格和基因组序列中的数值数据)对于实现稳健和通用的预测能力至关重要。因此,尽管 BPE 仍然是文本分词的有力工具,但其在数值数据上的不足凸显了开发针对科学数据集多样化需求的更先进的输入编码策略的必要性。相比之下,我们的二进制块编码通过提供一种统一、完整性保持且灵活的输入表示方法,解决了传统分词的根本局限。通过将所有数据(包括文本、代码、数字和科学符号)视为原始字节序列,它确保了跨模态的一致性,消除了对特定模态分词方案的需求,并简化了预处理流程。直接在二进制表示上操作保证了数据的完整性,因为没有信息因分割而丢失或扭曲。这对于数值推理尤为关键,因为传统的子词分词器(例如 SentencePiece [196])可能将像 9⋅11 这样的数字碎片化为 9, . .11,导致错误的比较,如在主流 LLM 中观察到的 9.11>9.9[210]。我们的方法通过将数字保持在其原生格式中而无需不必要的碎片化为子词 token,从而带来了简洁性,实现了准确的算术计算,同时还提供了灵活性,无需复杂适应即可处理多样和新型的数据类型。这些优势共同确立了二进制块编码作为语言引导科学计算的坚实基础。
许多科学数据集以原生二进制格式存储(例如 .bin, .dat)。我们尝试过将输入数据表示为比特序列(即 0 和 1)而不是字节(0 到 255 的值),因此将此方法命名为二进制块编码,但由于计算复杂度的增加而推迟了。目前,BigBang-Proton 使用 UTF-8 字节序列。直接二进制编码仍然是使模型能够从信息的基本构建块中学习的一个关键目标。
2.4 架构
BigBang-Proton 架构由三个核心组件组成。输入嵌入将离散的输入 token 转换为连续、密集的向量表示,使模型能够捕捉语义关系。蒙特卡洛注意力通过块间委托机制增强信息流,实现极长序列长度且计算复杂度可控。时序卷积网络(TCN)通过分层卷积层捕捉序列依赖性和时间模式,无需位置编码。
2.4.1 输入嵌入
输入表示 嵌入模块的输入是一个离散 token 序列,其中每个 token 由一个整数值表示。
字节值范围从 0 到 255,代表原始输入数据。特殊 token 包括填充 token、序列开始 token 和序列结束 token。填充 token(pad id:258):用于将序列填充到固定长度。序列开始 token(bos id:256):标记序列的开始。序列结束 token(eos id:257):标记序列的结束。因此,输入词汇表大小为 259,覆盖了所有可能的字节值和特殊 token。

2.4.2 蒙特卡洛注意力
蒙特卡洛注意力旨在实现超大的上下文长度,用于在计算可行的复杂度下对物理结构进行建模。蒙特卡洛注意力是一种稀疏注意力,可作为具有完整注意力计算的普通 Transformer 的替代方案。物理结构与自然语言有根本性的不同,前者通常需要比主流 LLM 预训练中使用的上下文长度大许多数量级的上下文长度。因此,根本性的架构重新设计是必要的。
稀疏注意力 由于标准注意力机制的二次缩放行为[349],大型语言模型中序列长度的扩展带来了巨大的计算挑战。这种计算负担推动了旨在保持模型性能的同时提高效率的广泛研究。一个关键的研究方向利用了注意力分布中自然出现的稀疏性,这种稀疏性既通过 softmax 操作[168] 在数学上表现出来,也通过神经连接模式[367] 在生物学上表现出来。当前的方法论通常采用固定的结构限制,包括基于水槽的[378] 或滑动窗口方法[34],或者在运行时自适应选择 token 子集的动态机制,例如 Quest [338]、Minference [169] 和 RetrievalAttention [212]。虽然这些技术减少了扩展序列的计算需求,但它们未能解决与长上下文模型相关的显著训练开销,限制了其可扩展部署到百万 token 上下文。为了应对这些局限性,像 MoBA [221] 和 NSA [400] 这样的稀疏注意力框架引入了高效的解决方案。MoBA 应用专家混合范式[312] 将上下文分割成块,使用门控机制将查询路由到相关块,从而降低计算成本。NSA 采用压缩和选择策略来构建紧凑的键值表示,优化 GPU 上的推理和训练。两者都增强了长上下文模型的效率。同时,线性注意力架构,以 Mamba [82]、RWKV [272, 273] 和 RetNet [329] 为代表,用线性变换替代 softmax 计算以降低开销。然而,将它们适配到现有的 Transformers 需要昂贵的转换[235, 359, 42, 410] 或重新训练[202],并且在复杂推理任务中的验证有限。长上下文能力作为下一代模型必需品的认识日益增强,这是由于对物质结构(如材料晶体、细胞、生态系统或星系)建模的需求驱动,这些结构需要超过数十亿或数万亿 token 的超长序列,远超过当前百万 token 的上下文限制[402]。复杂推理[84, 404]、代码生成[408] 和自主智能体[268] 中的应用进一步凸显了这一挑战。经验分析表明,对于 64k-token 序列,标准注意力占用了大部分的推理延迟[402]。需要能够实现数百上千万亿 token 同时降低计算需求的超长序列方法。
蒙特卡洛注意力 上下文长度,定义为一层 Transformer 在一次完整注意力计算中可以读取的极限,与 Transformer 层的深度无关。Transformer 中的直接信息流被限制在上下文长度内的 token。在预训练中,批次之间的信息流依赖于共享权重,而非注意力计算。相比之下,卷积神经网络(CNN)的感受野随着网络深度而扩展[224]。我们受到启发,采用逐层操作来增强所有输入嵌入之间甚至批次之间的信息流。蒙特卡洛注意力的关键创新在于每一层中的委托操作,导致动态的 token 重组。
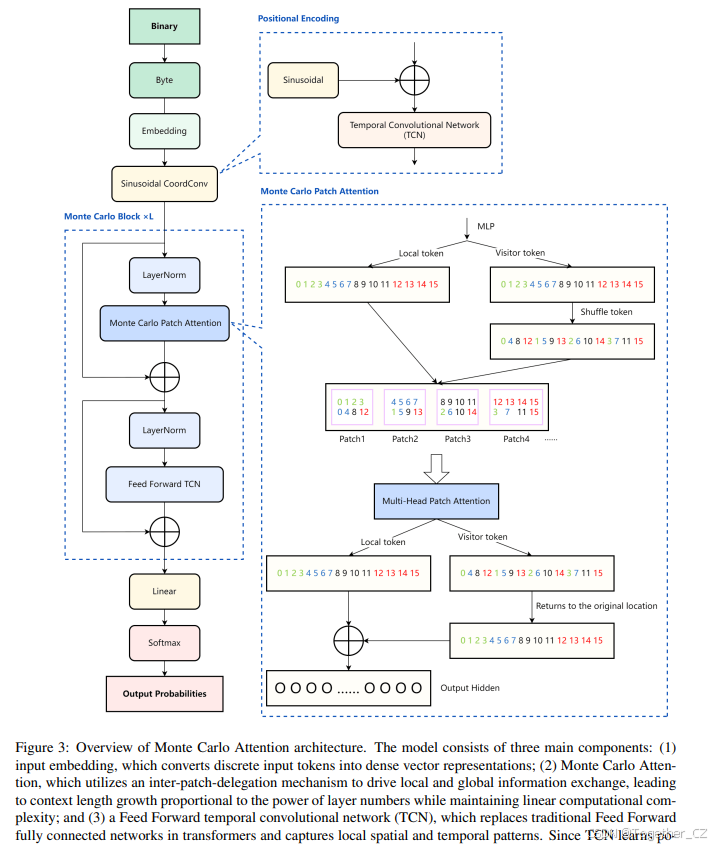
图 3: 蒙特卡洛注意力架构概览。该模型由三个主要组件组成:(1) 输入嵌入,将离散的输入 token 转换为密集的向量表示;(2) 蒙特卡洛注意力,利用块间委托机制驱动局部和全局信息交换,导致上下文长度增长与层数的幂成正比,同时保持线性计算复杂度;(3) 前馈时序卷积网络(TCN),替代了 Transformer 中传统的前馈全连接网络,并捕捉局部空间和时间模式。由于 TCN 学习位置信息,Transformer 中使用的位置嵌入被消除。


图 4: 嵌入向量在块之间被重组。每个块发送委托到其他块并从其他块接收委托,通过注意力计算进行信息交换。





表示退化、循环注意力和稀疏性 普通的 Transformer 依赖于完整的注意力计算,让输入嵌入从预定义上下文长度内的其他 token 获得表示。蒙特卡洛注意力采用块间委托机制来实现全局表示交换,实现超大的有效上下文长度。然而,通过蒙特卡洛注意力,表示只能通过多次注意力计算间接地在块之间交换。这种间接的注意力计算可能在迭代表示传播过程中导致信息退化。为了解决这个限制,我们通过重复单层操作多次引入了循环蒙特卡洛注意力。循环 Transformer 已成功应用于通过测试时计算优化[118]来增强长度泛化[102]和潜在推理[304]。循环注意力的基本原理是利用重复的表示交换来减轻信息损失,并在迭代注意力计算中增强表示质量。
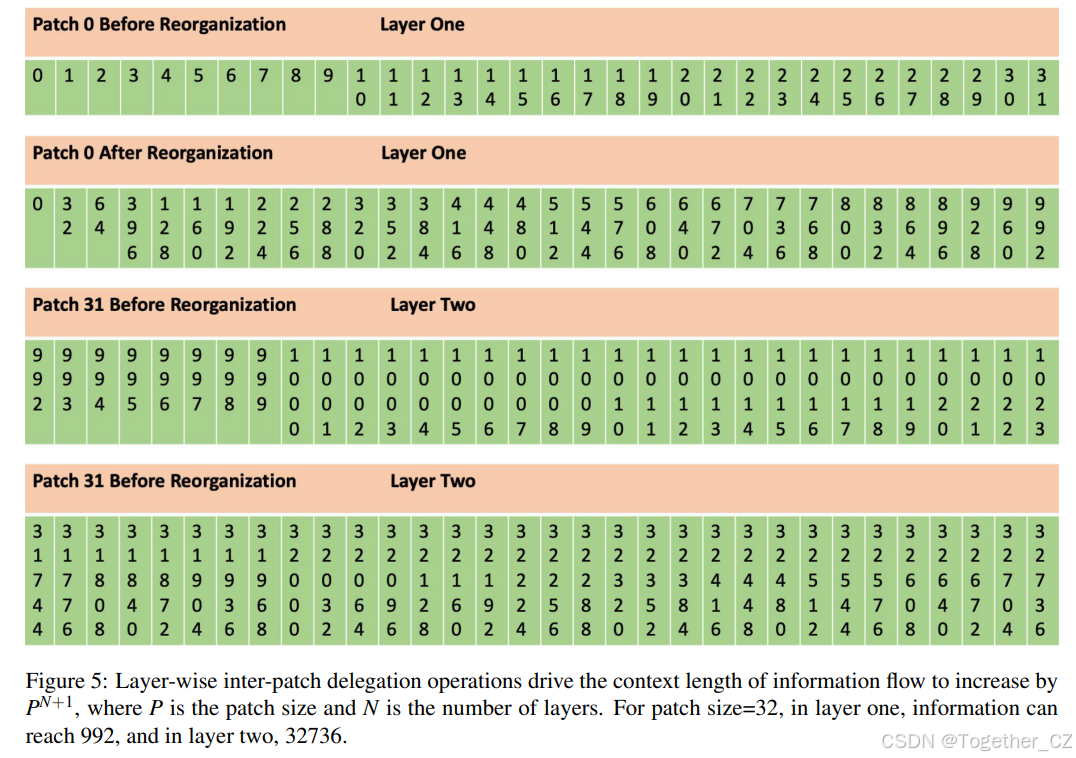
表 2: 不同层数(N)下,P=32 时的上下文长度 C(N)
| 层数 (N) | 上下文长度 C(N) | 比较 |
|---|---|---|
| 1 | 992 | - |
| 2 | 32,736 | - |
| 3 | 1,048,544 | - |
| 4 | 33,554,400 | - |
| 8 | 35,184,372,088,800 | GPT-4 语料库 token 数 |
| 10 | 36,028,797,018,963,936 | 人体细胞原子数 × 100 |
| 20 | 3.741444191567e+30 | Starship 飞船原子数 |
| 40 | 4.056481920730e+60 | 地球原子数 × 10 |
| 60 | 4.398046511104e+90 | 可观测宇宙比特数 |
| 80 | 4.767240170282e+120 | - |
| 100 | 5.165034368751e+150 | - |

2.4.3 前馈 TCN
作为注意力模块的补充,我们提出了一个具有增强模式捕获能力的时序卷积块。这个时序卷积网络(TCN)通过堆叠的核大小为 K 的 1D 卷积实现多尺度处理,提取分层的时序特征。

2.4.4 物理世界建模的上下文长度
蒙特卡洛注意力的开发是为了满足 BigBang-Proton 框架的理论需求,尽管实际实现面临硬件限制。驱动这一开发的基本假设包括几个关键考虑因素。首先,对于自回归预训练,二进制块编码作为一种原生的多模态方法,可以无缝地将所有数字数据格式转换为标准的二进制序列,这对超长上下文长度提出了严格的需求。第二,理论与实验学习范式有潜力在预训练期间整合来自跨尺度、跨结构、跨学科的历史和正在进行的科学实验的实验数据,这需要的上下文长度远远超过纯自然语言预训练所需的长度。最后,在将宇宙视为单一实体的终极场景中,如果所有原子(10801080[216])的信息可以被转换为一个单一的序列进行预训练,那么上下文长度能否达到宇宙尺度?

2.4.5 架构优势与比较
稀疏注意力和蒙特卡洛注意力之间的根本区别在于它们的核心计算机制。稀疏注意力方法,包括 NSA[400] 和 MoBA[221],采用基于选择的机制,通过选择 token 子集进行注意力计算来过滤键值对,以降低计算复杂度。NSA 采用三种复杂策略:通过块级聚合进行 token 压缩,通过块内 top-n 识别进行 token 选择,以及滑动窗口机制来保留局部上下文,动态地从 N 个 token 中选择 top-K 子集来构建紧凑表示。MoBA 采用专家混合启发的方法,将上下文划分为块,并应用 top-k 门控机制进行选择性注意力计算。相比之下,蒙特卡洛注意力通过块间委托采用基于重组的机制,通过将全局上下文压缩为代表 token 并在块之间交换这些 token 来结构性地重组 token 信息,通过委托 token 交换实现间接信息传播,而不是在选定的 token 之间进行直接注意力计算。

与其他稀疏注意力机制相比,我们的方法提供了独特的优势。随机稀疏注意力[158]随机选择元素进行动态调整,而我们的块间 token 重组实现了结构化的全局-局部交互。BigBird 稀疏注意力[78] 将局部注意力与跳跃机制结合,但与我们的动态委托 token 通信不同,它依赖于预定义的模式。有界稀疏注意力[1] 将注意力限制在局部区域以处理短程依赖关系,而我们的方法通过块连接平衡了局部和全局上下文。固定稀疏注意力[73] 使用预定义模式,缺乏适应性,而我们的动态重组则适应输入结构。星形稀疏注意力[158] 将中心节点连接到外围节点,关注特定区域,而我们的方法通过 token 洗牌全面分配全局上下文。对数稀疏注意力[206] 使用对数函数调整权重,而我们的方法通过委托 token 和增强梯度稳定性的残差连接实现平滑性。


最后,将时序卷积网络(TCN)[21] 整合到架构中,使得捕获瞬时相关性和演化的时间模式成为可能,而无需位置编码。TCN 旨在通过堆叠膨胀卷积来处理序列,这允许网络访问长程依赖关系,同时保持因果性。由于 TCN 中卷积的固有性质,模型可以自然地学习序列中元素的相对位置,从而消除了对显式位置编码的必要性。
正如我们的结果所示(第 3 节),这种结构在实现最先进性能的同时,相比传统方法需要显著更少的计算资源。定量复杂度分析和详细的 FLOPs 比较在附录 A.2 中提供。
2.5 训练
本节详细介绍 BigBang-Proton 的训练方法,包括预训练和后训练阶段。
2.5.1 预训练
如表 3 所示,BigBang-Proton 模型具有 15 亿参数,配置为 20 层蒙特卡洛注意力架构,隐藏状态维度为 1024,每层 4 个注意力头。它使用词汇表大小为 259,包含 256 个可能的字节值和 3 个特殊 token(开始、结束和填充)。前馈网络采用扩展比(mlp_ratio)为 2 以增加通道容量。为了正则化训练并提高泛化能力,模型采用了 dropout 机制,最大 dropout 率为 0.15 应用于各层,注意力特定的 dropout 率为 0.1,随机深度生存率为 0.15。这种设置使模型能够有效地处理和生成科学数据上下文中的序列,利用架构的可扩展性处理多样化的模态。
我们使用分布式框架完全分片数据并行(FSDP)来实现分布式预训练。如表 4 所示,预训练过程配置如下:模型对其蒙特卡洛注意力层使用块维度为 (16,32,1024),其中块被随机划分为 16 到 32 个 token,最后两个蒙特卡洛注意力层使用更大的块大小 1024 用于全局上下文整合。输入序列长度固定为 8192×88192×8 个 token,因为最大和最小输入大小都设置为此值。词汇表大小为 259,包括 256 个字节级数据值(0-255)和三个用于开始、结束和填充的特殊 token。训练设置为 20 个周期,但过程主要由迭代次数管理。预训练使用的学习率为 0.00004,预热期为 100 步以稳定初始收敛。对于微调,学习率降低到 0.00001。为了优化资源使用并防止过拟合,采用了早停策略。批次大小设置为 1,其中多个序列被连接成一个长序列,并在 4 个步骤上应用梯度累积以有效模拟更大的批次大小。使用 AdamW 优化器进行参数更新,权重衰减为 3×10−3 用于正则化。数据加载由 8 个工作进程处理以确保高效的 I/O。每个批次的 token 限制为 8192×8。训练循环受到监控,每 70 步进行一次评估,每 10 步打印一次进度,每 280 步保存一次模型检查点。为防止验证运行时间过长,验证过程上限为 300 步。
如图 6 所示,训练损失和困惑度曲线在 61,381 步中表现出一致、平滑和单调的收敛,表明在整个预训练过程中学习稳定且有效。损失稳步下降至 0.613,而困惑度降至 2.04,反映了模型在所有九个不同任务中准确预测下一个 token 的能力有显著提高。这种一致的改进表明,
表 3:模型超参数
| 超参数 | 值 |
|---|---|
| embedding_dim | 1024 |
| num_classes | 259 |
| num_layers | 20 |
| num_heads | 4 |
| mlp_ratio | 2 |
| dropout_rate | 0.15 |
| attention_dropout | 0.1 |
| stochastic_depth_rate | 0.15 |
表 4:预训练超参数
| 超参数 | 值 |
|---|---|
| patch_size | (16,32,1024) |
| max_input_size | 8192×88192×8 |
| min_input_size | 8192×88192×8 |
| vocab_size | 259 |
| epochs | 20 |
| lr | 0.00004 |
| warmup | 100 |
| batch_size | 1 |
| grad_accum | 4 |
| optimizer | AdamW |
| weight_decay | 3×10−33×10−3 |
| workers | 8 |
| limit_tokens | 8192×88192×8 |
| iter_val | 70 |
| iter_print | 10 |
| iter_save | 280 |
| iter_break_val | 300 |
使用二进制块编码实现的下一词预测,克服了高度的数据异构性并有效地实现了稳健的模型收敛。
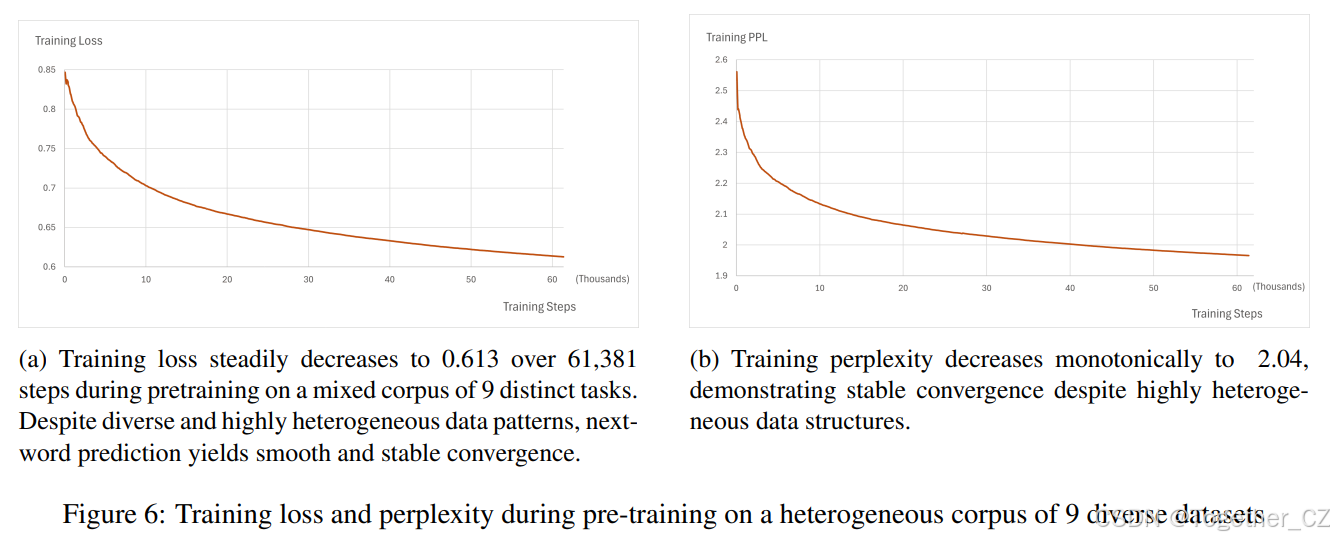
图 6: 在 9 个不同数据集的异构语料库上进行预训练时的训练损失和困惑度
2.5.2 后训练
在预训练的最后阶段,我们使用教科书水平的高质量数据[134]进行退火,然后使用 Infinity-Instruct 数据集[18]进行监督指令微调。之后,对于科学下游任务,预训练模型在任务数据集上进一步微调,以执行语言引导的科学计算。
3 结果
3.1 语言生成
拥有 15 亿参数的 BigBang-Proton(与 GPT-2[287] 模型大小相同)在五个广泛认可的基准测试上进行了测试,以评估其在语言理解和生成的各个方面的性能。基于第 2.5.2 节详述的高质量数据集,我们使用旨在增强其对话能力的指令数据对模型进行了微调。这个过程涉及将 Infinity-Instruct [18] 和 Open Phi [134, 263] 等数据集改编为指令格式。
如表 5 所示,模型在包含约 60B BPE token 的通用目的数据集上进行了训练(数据来源于 SlimPajama[320] 数据集 10 个分块中的十分之一)。BigBang-Proton 在 MMLU[149]、ARC、HellaSwag 和 PIQA 基准测试上的得分分别为 25.44%、25.29%、26.19%、25.19% 和 51.14%,这一表现是显著的。这些结果表明,使用二进制块编码方法的 BigBang-Proton 实现了与 GPT-2 相当的推理能力(GPT-2 在来自 WebText 的约 40B BPE token 上训练,在 MMLU[149] 上获得 25.83% 的准确率)。这一发现特别值得注意,因为它表明二进制块编码策略不仅对处理科学和数值数据有效,而且在通用语言推理任务中也具有巨大潜力。这个结果表明,这种独特的编码方法并没有损害其进行复杂推理的能力。这种语言能力是模型核心功能——语言引导的科学计算——的关键前提。
表 5:BigBang-Proton 字节级模型在七个领先基准测试上的性能
| 基准测试 | 准确率(%) |
|---|---|
| MMLU | 25.44 |
| Arc-E | 25.29 |
| Arc-C | 26.19 |
| HellaSwag | 25.19 |
| PIQA | 51.14 |
通用对话
用户:现在你是一位物理学家,请告诉我量子力学是什么?
BigBang-Proton 回答
量子力学是物理学的一个分支,研究物质和能量在原子和亚原子尺度上的行为。它基于波粒二象性、不确定性原理和叠加态原理。
我们在图 7 中展示了一个通用语言生成能力的例子。该图展示了用户与模型之间的对话,突出了 BigBang-Proton 通过通用文本训练学习了基本的物理学知识。

图 7: 展示模型通用语言生成能力的对话说明。该图展示了一个对话示例,其中模型以连贯的方式响应用户提示。
3.2 算术运算
众所周知,LLM 在执行复杂数值计算时会遇到巨大困难。GPT-4 在 3 位数乘以 3 位数的乘法中仅能达到 59% 的准确率[100, 392, 401],对于更大的数字,性能进一步急剧下降[205, 100]。Yuan 等人 (2023)[401] 对 LLM 算术任务能力的一项系统性研究表明,GPT-4 在处理高达 100,000 的两个整数乘法时在所有情况下都失败了。这一根本缺陷可以追溯到主流字节对编码(BPE)分词不适合数字表示[200, 36]。BPE 倾向于将多位数数字分割成不规则的块(例如,“1009 + 8432”可能被分割为“100”、“9”、“+”、“84”、“32”),这会破坏模型正确对齐操作数和执行算术运算的能力[394]。
针对这些局限性,最近的研究专注于开发增强 LLM 算术能力的策略。Nogueira 等人 [254] 和 Wang 等人 [355] 的早期探索为评估 LLM 执行基本算术运算(如加法和减法)的能力奠定了基础。随后,Muffo 等人 [244] 对语言模型在两位数乘法中的表现进行了重点评估,为模型在这一特定领域的熟练程度提供了宝贵的见解。BIG-bench 数据集[324] 包含涉及高达五位数的各种算术任务,已成为对这些模型能力进行基准测试的关键资源。Nye 等人[258] 实现了基于草稿纸的微调方法,显著增强了模型执行八位数加法的能力。Goat [213] 采用监督指令微调来增强 LLM 在大整数基本算术运算(包括加法、减法、乘法和除法)上的性能。Jelassi 等人[166] 探索了基本算术任务中的长度泛化概念,利用相对位置嵌入和训练集预热等方法来提高模型的适应性。在这些进展的基础上,Zhen 等人[392] 提出了 MathGLM,该模型在不依赖外部计算器的情况下,在 5-12 位数算术任务中达到了 93.09% 的准确率。该模型在涉及大数、小数和分数的复杂算术运算中表现出优于 GPT-4 和 ChatGPT 的性能。MathGLM 的成功可归功于其逐步策略和课程学习方法,这使得模型能够有效地学习算术运算的基本规则。
在另一个重要贡献中,McLeish 等人[233] 通过引入算盘嵌入解决了 Transformer 位置编码的局限性。使用字符级分词器,算盘嵌入编码每个数字相对于数字起始的位置,使得 Transformer 能够对齐算术运算中数字的确切位置。这项创新带来了算术任务中达到最先进的性能,模型在 100 位数加法问题上达到高达 99% 的准确率。该研究还展示了这些嵌入在其他算法推理任务(如乘法和排序)中的潜力,进一步扩展了 LLM 数值能力的范围。虽然算盘嵌入在处理复杂数值计算方面显示出显著的改进,但它们给模型架构引入了额外的复杂性,难以适配当前主流通用预训练架构。
相比之下,BigBang-Proton 采用二进制块编码,这与 BPE 分词有根本不同,也不同于算盘嵌入的字符级位置对齐。我们使用二进制块来保持数字表示的完整性,并在预训练中融入思维链(COT)推理,让模型直接学习位置对齐,而无需对模型架构引入额外的修改。
在此任务中,我们再次使用预训练语料库中的算术 COT 数据集进行微调,包括高达 50 位数的加法和减法,以及高达 12 位数的乘法。如图 8 所示,我们构建了一个算术 CoT 数据集,模拟人类用来解决算术问题的逐步计算过程。对于加法和减法,CoT 将问题分解为一系列位置对齐的双位数运算序列(例如,‘4+2’,‘5+3’),而对于减法,包含比较步骤(‘A>B’)至关重要,因为它教授了模型减法中借位的概念,将单一复杂问题转化为一系列简单的、按位置进行的运算,模型可以顺序学习。乘法 CoT 要复杂得多,特别关注进位机制。模型被展示为取第一个数字 A 的一位数字与整个第二个数字 B 相乘,标记 ‘b=0’、‘b=1’、‘b=2’ 明确表示从一位乘法到下一位的进位值。例如,在 ‘5*2+B=10+0=10 b=1’ 中,模型学习到结果是 10,所以写下数字 ‘0’ 并将进位 ‘1’ 传递到下一个更高位,而标记 ‘res=3158504704e0’ 和 ‘res=6317009408e1’ 明确编码了部分积的位置值,其中 ‘e0’、‘e1’、‘e2’ 代表乘以 100100、101101、102102 等,这对于在对不同位置的部分积进行最终求和之前正确对齐它们是必不可少的。CoT 隐含地展示了最终答案是通过对所有部分积求和得到的(例如,‘res=...e0 + res=...e1 + res=...e2 + ...’)。
进位机制是算术逻辑单元(ALU)[181](微处理器的基本构建模块)的核心操作原理。建立在二进制块编码之上并经过 COT 逐步推理训练的 BigBang-Proton 学习了 ALU 的操作原理,包括进位机制,这本质上是算术逻辑单元的位级求和原理。ALU 对二进制输入执行位并行操作,如图 9 所示。一个典型的 ALU 包括输入寄存器、功能单元和输出多路复用器。输入寄存器存储操作数 AA 和 BB,示例中显示为 4 位宽度。功能单元包括带有进位链的加法器/减法器、逻辑门(AND/OR/XOR)以及移位/旋转电路。这些组件使 ALU 能够执行各种算术和逻辑运算。最后,输出多路复用器根据控制信号选择结果,确定 ALU 的最终输出。ALU 中的进位原理指的是在位级加法过程中,从一个比特位的溢出(进位比特)被传播到下一个更高比特位,通过以链式方式处理比特之间的依赖关系,确保跨二进制数字的准确求和。
在测试我们模型时遇到的一个乘法任务示例如下,这证明了 BigBang-Proton 掌握了按位进位原理。输入序列是:

更多突出模型对数字位置敏感性的例子可以在附录 A.3.1 中看到。BigBang-Proton 学会了管理进位传播和位级求和,并且能够泛化到任意位数的算术任务,因为计算器和 ALU 从根本上就是围绕这个为无限可扩展性而设计的原则。
这种能力代表了语言引导的科学计算和财务分析的核心,尤其是在处理来自大科学实验的大规模实验数据集时,这些数据集通常包含海量的数值实验结果。加法、减法和乘法等基本运算是数值分析的基础,其中的计算过程和结果需要 100% 的准确性,才能准确地映射到所描述的物理结构和物理现象。通过使 LLM 学习 ALU 进位原理,100%
基础算术运算_加法运算
123123457457352354 + 7467458472832 =
BigBang-Proton 回答
4+2,5+3,3+8,2+2,5+7,3+4,7+8,5+5,4+4,7+7,5+6,4+4,3+7,2+0,1+0,3+0,2+0,1+0;结果:123130924915825186
(a) 加法示例
基础算术运算_减法
739827983928 - 2983293 =
BigBang-Proton 回答
8-3,2-9,9-2,3-3,8-8,9-9,7-2,2-0,8-0,9-0,3-0,7-0,A-B,A>B;结果:739825000635
(b) 减法示例
基础算术运算_乘法
1579252352 * 2152340642 =
BigBang-Proton 回答
CoT: 1579252352*2e0:2*2+B=4+0=4 b=0,5*2+B=10+0=10 b=1,3*2+B=6+1=7 b=0,2*2+B=4+0=4 b=0,5*2+B=10+0=10 b=1,2*2+B=4+1=5 b=0,9*2+B=18+0=18 b=1,7*2+B=14+1=15 b=1,5*2+B=10+1=11 b=1,1*2+B=2+1=3 b=0,res=3158504704e0; 1579252352*4e1:2*4+B=8+0=8 b=0,5*4+B=20+0=20 b=2,3*4+B=12+2=14 b=1,2*4+B=8+1=9 b=0,5*4+B=20+0=20 b=2,2*4+B=8+2=10 b=1,9*4+B=36+1=37 b=3,7*4+B=28+3=31 b=3,5*4+B=20+3=23 b=2,1*4+B=4+2=6 b=0,res=6317009408e1; 1579252352*6e2:2*6+B=12+0=12 b=1,5*6+B=30+1=31 b=3,3*6+B=18+3=21 b=2,2*6+B=12+2=14 b=1,5*6+B=30+1=31 b=3,2*6+B=12+3=15 b=1,9*6+B=54+1=55 b=5,7*6+B=42+5=47 b=4,5*6+B=30+4=34 b=3,1*6+B=6+3=9 b=0,res=9475514112e2; 1579252352*0e3:case0*; res=0e3; 1579252352*4e4:2*4+B=8+0=8 b=0,5*4+B...; 结果:3399089021183689984
(c) 乘法示例


图 8: 使用思维链推理的算术运算提示-答案示例说明。这种设计使模型能够通过位置对齐的逐步计算来学习 ALU 的进位原理,模型在此过程中理解多位数算术运算中进位比特的顺序传播。
如图 10 所示,在涉及高达 50 位数的加法和减法以及高达 12 位数的乘法的算术任务中,三个模型 BigBang-Proton、DeepSeek-R1 和 ChatGPT-o1 的准确率表现如下:BigBang-Proton 在加法、减法和乘法上分别达到 100%、98% 和 90% 的准确率。DeepSeek-R1 达到 19.23%、11.63% 和 9.68%;而 ChatGPT-o1 达到最低的准确率,分别为 3.85%、6.98% 和 3.23%。对于每个任务,BigBang-Proton 在 200 个样本的测试集上进行评估,而 DeepSeek-R1 和 ChatGPT-o1 在 100 个样本的测试集上进行评估,所有模型均在零样本提示设置下进行评估。BigBang-Proton 与通用 LLM 在算术任务上的巨大性能差距源于它们数据编码方法的根本差异。
BigBang-Proton 的优越性能(在 50 位数加法上达到 100% 准确率,在 50 位数减法上达到 98%)源于我们的二进制块编码方法和 CoT 训练。这种方法将所有数据视为原始二进制序列,保留了数值信息的完整性。至关重要的是,它允许模型从包含逐步推理的训练数据中学习数字位置对齐,这是 ALU 原理的核心。通过将数字作为连续的字符序列处理(例如“12345”),模型自然地学习到最右边的数字是个位,接下来是十位,依此类推,从而实现了一种真正的、可泛化的加法和减法算法,可以外推到任意长度。由于 BigBang-Proton 在 12 位数乘法中达到了 90% 的准确率,如图 10 所示,与数字位置相关的错误占大多数不正确的情况,表明其对数字位置的敏感性,如附录 A.3.1 所示。与此形成鲜明对比的是,DeepSeek-R1 和 ChatGPT-o1 使用字节对编码(BPE),它将数字分割成任意块(例如,“12345”可能被分割成“12”、“34”、“5”)。这破坏了对位置的理解,并迫使模型进行记忆而不是算法推理。由于分词不一致而无法学习连贯的算法,这些模型只能在潜在空间中记忆特定的输入-输出对,这解释了它们糟糕的性能(加法分别为 19.23% 和 3.85%)。BPE 为单个数字分配任意的、非连续的分词 ID,创建了不连续的表示。逐步计算数据对基于 BPE 的模型无效,因为它们的分词器破坏了问题的结构。从本质上讲,虽然 DeepSeek-R1 和 ChatGPT-o1 记住了数字事实,但它们未能学习 ALU 的操作原理。
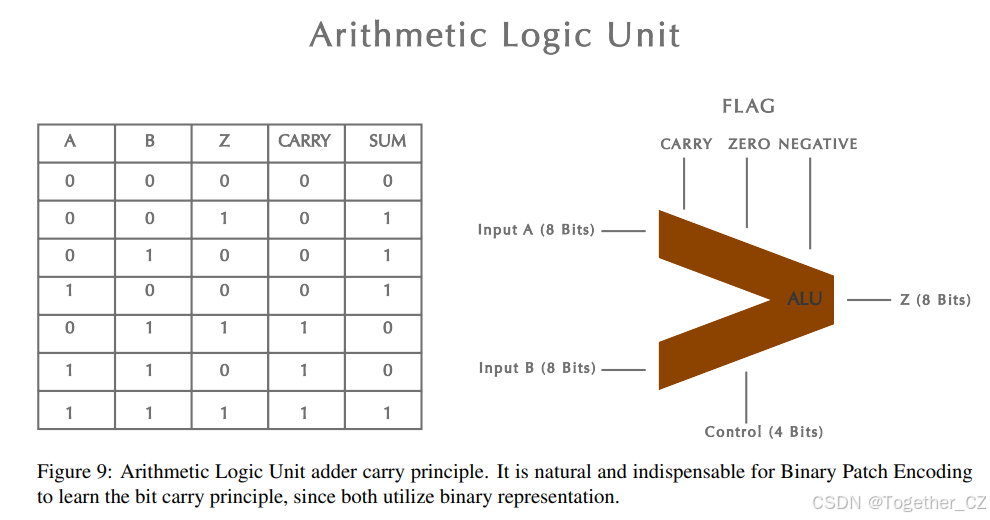
图 9: 算术逻辑单元加法器进位原理。对于二进制块编码来说,学习比特进位原理是自然而不可或缺的,因为两者都使用二进制表示。
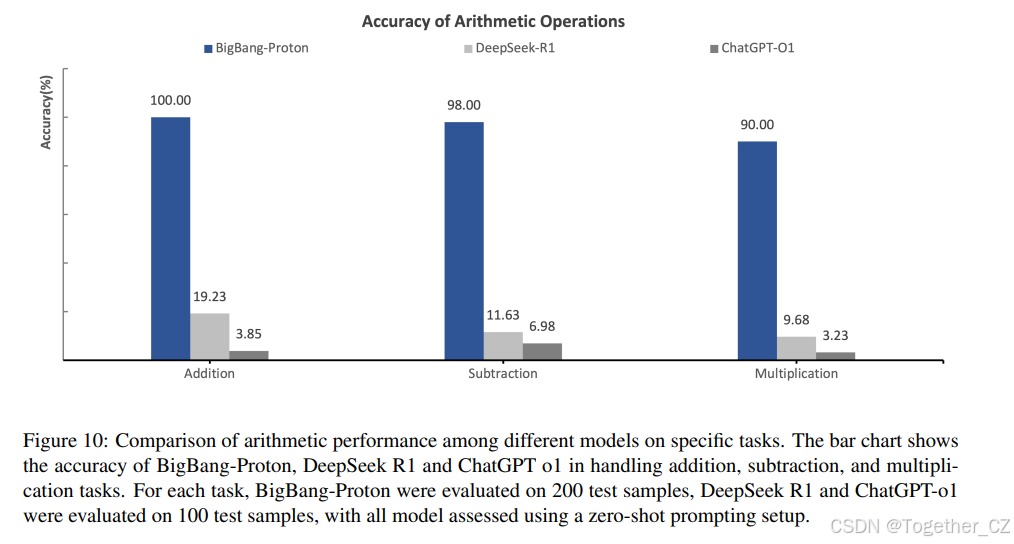
图 10: 不同模型在特定任务上的算术性能比较。条形图显示了 BigBang-Proton、DeepSeek R1 和 ChatGPT o1 在处理加法、减法和乘法任务时的准确率。对于每个任务,BigBang-Proton 在 200 个测试样本上进行评估,DeepSeek R1 和 ChatGPT-o1 在 100 个测试样本上进行评估,所有模型均使用零样本提示设置进行评估。
3.3 粒子物理中的喷注标记任务:语言引导的分类
在 LHC 或未来的电子-正电子希格斯工厂等高能粒子碰撞设施中,夸克和胶子产生朝相同方向运动的强子准直喷流,这些喷流被称为喷注,它们保留了关于底层部分子动力学的信息,并作为研究 QCD 的关键特征。为了解决粒子物理中的特定挑战,继我们之前的工作 BigBang-Neutron[375]之后,我们将喷注起源识别(JOI)数据集[413, 375]与其他多学科数据混合预训练了 BigBang-Proton,然后在进行下游喷注标记任务时,再次使用相同的数据集微调预训练模型。此任务侧重于区分源自不同夸克和胶子的喷注。具体来说,模型被训练以识别 11 种不同类型的喷注,这对于理解高能碰撞的动力学至关重要。训练数据集包含 1100 万个样本,每种喷注类型 100 万个样本,确保了对每个类别的平衡和全面的表示。准确识别喷注起源对于推进高能物理研究至关重要,特别是在研究希格斯、W 和 Z 玻色子时,这些玻色子大部分直接衰变为两个喷注。在喷注起源识别(JOI)任务的微调中,我们对模型进行了 10 个周期的训练,并在包含 10,000 个样本的验证集上评估其性能。与我们之前的工作 BigBang-Neutron[375]使用直接分类 LM 头不同,BigBang-Proton 利用自回归语言建模,基于粒子信息的零样本提示来预测喷注类型。BigBang-Proton 的喷注标记清晰地展示了语言引导的分类。
该数据集被精心设计为提示-分类格式,以从预训练开始就培养语言引导分类的能力,遵循理论与实验学习范式。如图 11 所示,喷注标记任务的提示被结构化为一个完整的、自包含的指令-响应对,无缝集成了自然语言理论和实验数据。它以一个清晰的指令开始:“这里有一个粒子喷注。你需要确定这是什么类型的喷注。” 这个指令设定了上下文并定义了模型的目标。紧接着这个命令,提示提供了全面的自然语言理论解释,详细说明了每个粒子属性(如电荷、动量、能量和碰撞参数)的物理意义,为模型解释后续数值数据提供了必要的背景知识。然后,这个理论基础直接链接到实验输入,实验输入由一系列粒子信息组成。每个粒子由其索引和一组代表其属性的数值来描述。序列以正确的喷注类别(例如“c-jet”)明确陈述作为预期答案结束。有关 JOI 数据集的详细信息,包括特定属性定义和示例提示,请参阅附录 A.1.2。

图 11: 使用 BigBang-Proton 进行喷注起源识别的提示-答案示例说明。每个提示以对模型的指令性命令开始,明确要求其根据模拟或实验测量中给出的粒子数据确定喷注类别。这些数值数据集在提示中有相应的文本解释,为理论与实验学习范式奠定了基础。
我们之前的工作 BigBang-Neutron [375] 依赖于在其基础架构之上添加专门的分类或回归 LM 头,这使得任务能力成为一种架构选择。然而,BigBang-Proton 通过提示-预测范式利用语言引导的科学计算。这使得它能够以端到端自回归的方式执行分类和回归任务,其中任务本身(例如“分类喷注类型”或“预测能量值”)在推理期间在文本提示中指定。这消除了对任何架构修改的需求,使得统一模型能够通过自然语言指令处理多样化的任务。

随后,我们检查了两个关键指标,包括喷注味标效率和电荷反转率。喷注味标效率定义为被正确标记的喷注百分比,不区分喷注的电荷。电荷反转率计算为混淆矩阵块的非对角线元素之和与总和的比率,量化了错误识别喷注电荷的概率,数值越低表示性能越好。图 13 显示了每种夸克类型的味标效率和电荷反转率,表明在 100 万数据量下,PN、ParT、BigBang-Neutron 和 BigBang-Proton 表现出相似的性能。为了研究模型的数据缩放行为和涌现能力[370],我们用不同的数据集大小进行了一系列实验。具体来说,我们在原始数据集的子集上训练模型(从完整数据的 10% 到 100%),并在相同的验证集上评估其性能。
如图 14 所示,当数据集大小超过一个阈值时,BigBang-Proton 模型的性能急剧增加。BigBang-Proton 在 b 喷注的味标效率方面表现出最显著的性能提升,当数据集大小超过 100 时,性能优于其他模型,之后收敛到一个稳定的水平。相比之下,BigBang-Neutron 需要 1000 个样本来开始性能跃升。对于 c 喷注,BigBang-Proton 的味标效率保持在 45% 左右持平,然后当数据集大小超过 104104 时开始提高。对于 d 喷注,BigBang-Proton 从起点开始持续增长。对于 c 喷注和 d 喷注,BigBang-Proton 都显示出效率提高的势头,而其他模型在临界点 104104 之后显示出收敛的迹象。对于 u 喷注和 d 喷注,BigBang-Proton 模型的性能波动性更大,显示出随着数据量增加没有明显趋势的波动。
转向电荷反转率,图 14 显示基于 Transformer 的 BigBang-Neutron 和 BigBang-Proton 的趋势相似。在较小的数据集规模下,这些模型保持接近随机水平,并且在电荷反转率上没有表现出任何
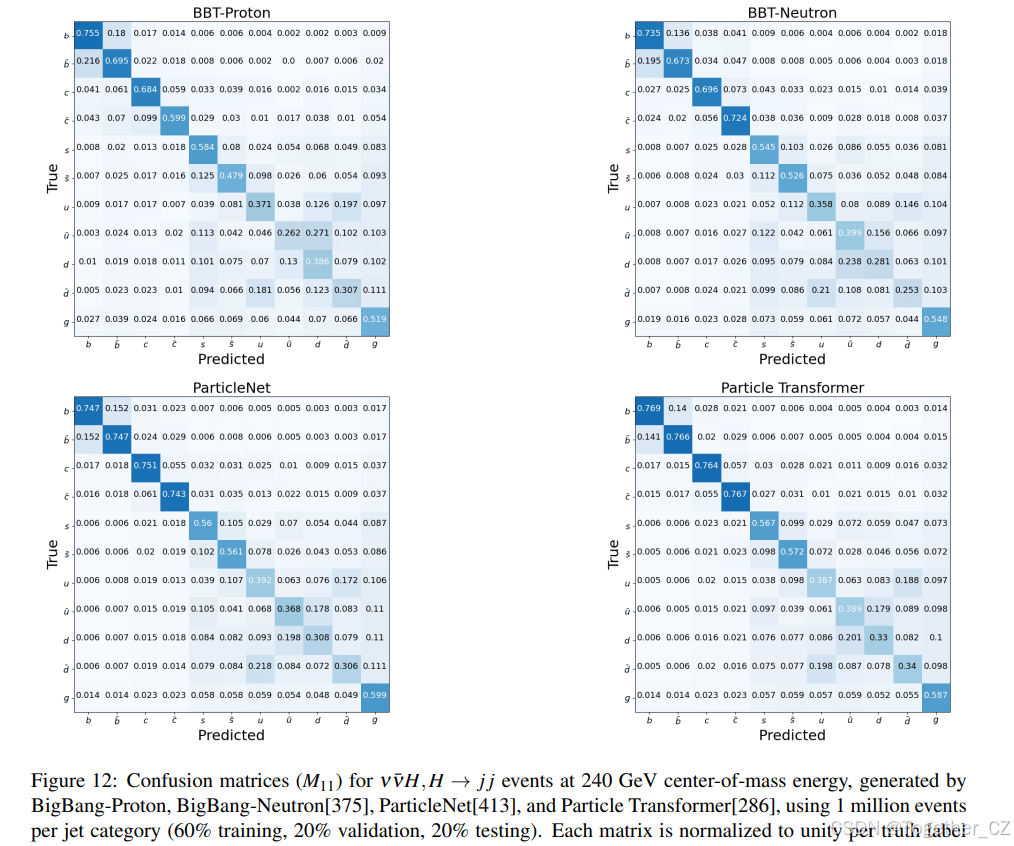

性能跃升。然而,当数据集大小增加到某个临界数据集大小时,电荷反转率急剧下降到与 PN 和 ParT 等专用模型相当的水平。值得注意的是,BigBang-Proton 在更大的数据集大小约 106106 处达到这个临界点,而 BigBang-Neutron 模型在 105105 处看到这种下降,PN 和 ParT 在这个任务中基本上没有表现出涌现行为。
观察到的电荷反转率涌现行为[370]临界数据集大小的差异(自回归的 BigBang-Proton 约为 106106 样本,而具有特定任务分类头的基于 Transformer 的 BigBang-Neutron 约为 105105)突出了这些架构学习专用任务方式的根本差异。自回归模型,如 BigBang-Proton,本质上专注于下一词预测,这将分类框定为生成过程(例如,对粒子数据进行语言引导推理)。这种上下文内方法[95, 322, 287, 55]要求模型构建更丰富、更具组合性的表示,以通过顺序生成将输入映射到输出,通常需要更大的数据集来捕捉像电荷反转这样从跨上下文的概率依赖中出现的微妙模式。相比之下,BigBang-Neutron 的直接分类头显式地针对任务进行优化,使得能够用更少的样本更快地收敛于判别特征,因为它绕过了生成中间步骤的需求。像粒子网络(PN)和粒子 Transformer(ParT)这样的专用模型没有表现出这样的涌现性能跃升,它们用更小的数据集就能达到良好的性能,这可能是因为它们的架构是针对特定任务设计的,并在结构中嵌入了领域知识,从而实现了更强的归纳偏置和更有效的早期学习。BigBang-Neutron 采用了更通用的基于序列的架构。从专用模型到 BigBangNeutron 和 BigBang-Proton 观察到的趋势表明,更通用的架构需要更大的数据集和更多的训练计算量才能达到相变。
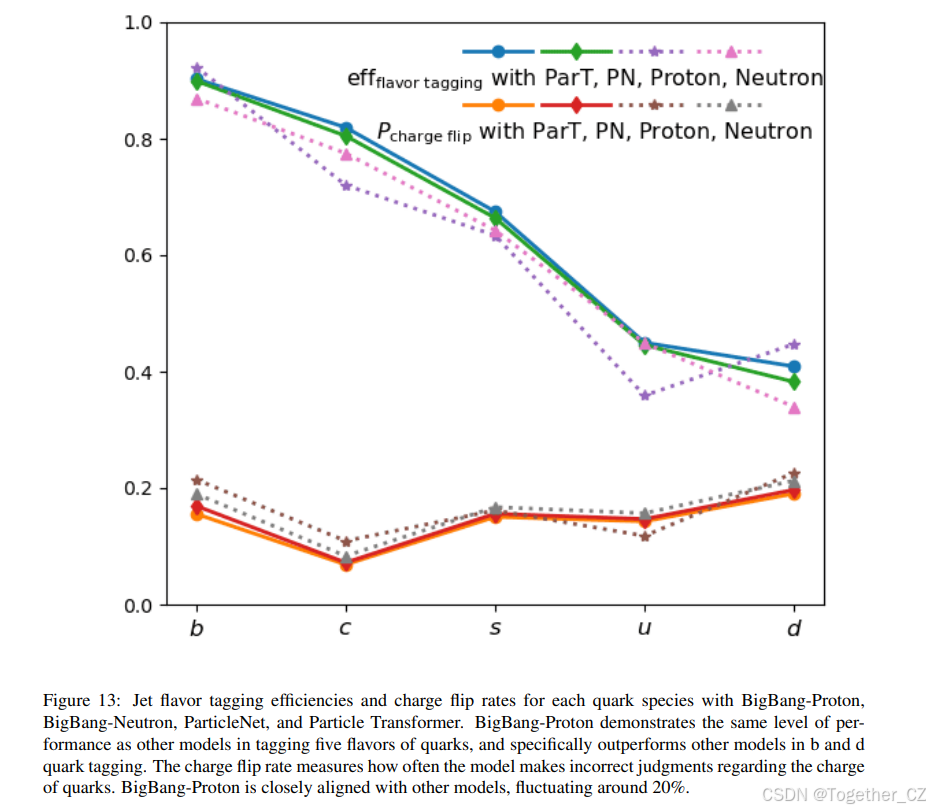
图 13: BigBang-Proton、BigBang-Neutron、ParticleNet 和 Particle Transformer 对各种夸克种类的喷注味标效率和电荷反转率。BigBang-Proton 在标记五种夸克味时表现出与其他模型相同水平的性能,特别是在 b 和 d 夸克标记方面优于其他模型。电荷反转率衡量模型在判断夸克电荷时出错的频率。BigBang-Proton 与其他模型密切一致,在 20% 左右波动。
如图 15 所示,通用 LLM 在 11 类粒子喷注标记任务上的表现严重不足,所有模型的性能都接近随机猜测水平(10%)。DeepSeek-R1 (8%)、ChatGPT-O1 (7%)、Claude 3.5 Sonnet (9%)、KIMI (7%) 和 ChatGPT-0.2 (9%) 仅实现了有限的准确率。即使是专门为复杂推理设计的先进版本,GPT-5 (16.4%)、Grok4 (11.8%) 和 Claude Sonnet 4 思考模式 (5.45%) 也只显示出微小的改进,表明它们复杂的推理能力对此科学任务无效。如附录 A.1.2 所示,由 DeepSeek-R1、Claude 3.5 甚至包括 GPT 5 和 Grok 4 在内的先进推理模型提供的分析揭示了一种一致的浅层推理模式,未能与粒子喷注形成的物理原理进行深入互动。它们的分析局限于一份易于提取的特征清单,包括粒子数量、能量分布、粒子类型组成和基本运动学变量,通常涵盖多重性、软度/硬度、π 介子、光子、K 介子、碰撞参数和角分离。虽然这些特征在数据中被提及,但模型仅仅是计数和分类它们,而没有展示对产生这些特征的因果机制的任何理解。例如,DeepSeek-R1 正确指出胶子喷注由于更大的色荷而具有更高的多重性,但将其视为需要匹配的记忆事实,而不是需要应用的原理。它观察到“软辐射”和“大的 Delta R”作为孤立的事实,未能将它们与部分子级联的基本过程联系起来,在该过程中,高能部分子通过受 QCD 控制的分支过程辐射出较低能量的胶子。类似地,Claude 3.5 对“带电粒子主导”和“带电与中性粒子混合”的关注仅仅是对数据的描述,而不是分析。GPT-5 对“位移显著性”(sd0sd0 和 sd0sd0)的计算使用这一点进行概率猜测,陈述“倾向于 c-jet”,基于 b 与 c 喷注的记忆模式,而不是模拟实际的强子化过程。这种方法在根本上是错误的,因为它将喷注分类视为一组手工制作特征上的模式匹配练习,类似于多项选择测试,其中答案已经知晓,格式与当前的 LLM 基准测试[277, 149, 295]相似。这些模型无法模拟底层的物理过程。它们只能识别从训练数据中学到的统计相关性。
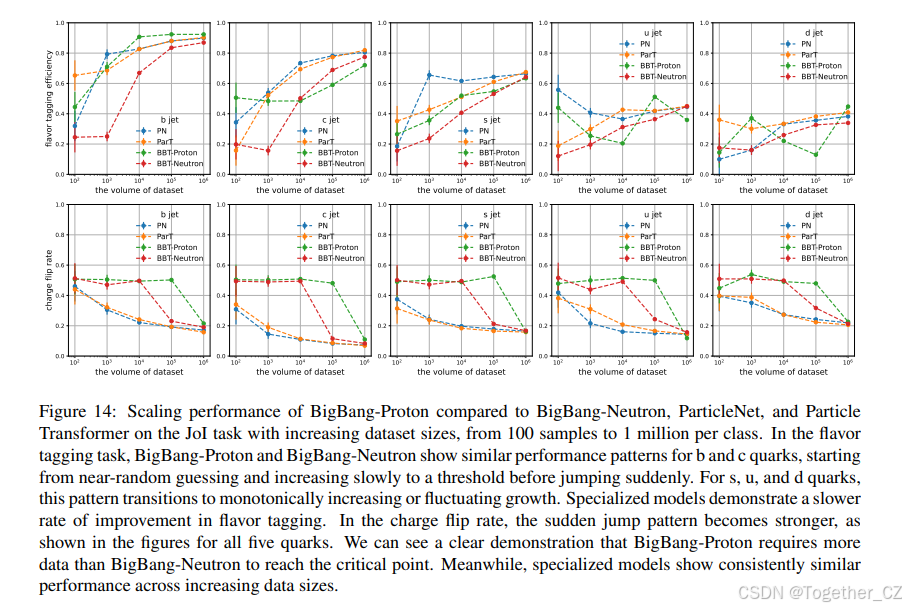
图 14: 在 JOI 任务上,BigBang-Proton 与 BigBang-Neutron、ParticleNet 和 Particle Transformer 在增加数据集大小(从每类 100 个样本到 100 万个)时的缩放性能。在味标任务中,BigBang-Proton 和 BigBang-Neutron 对于 b 和 c 夸克表现出相似的性能模式,从接近随机猜测开始,缓慢增加到阈值,然后突然跃升。对于 s、u 和 d 夸克,这种模式转变为单调增加或波动增长。专用模型在味标效率上显示出较慢的改进率。在电荷反转率方面,突然跃升的模式变得更强,如所有五种夸克的图中所示。我们可以清楚地看到 BigBang-Proton 比 BigBang-Neutron 需要更多数据才能达到临界点。同时,专用模型在增加数据大小时显示出持续相似的性能。
除了测试零样本推理外,我们进一步通过微调两个主流大语言模型 Qwen 2.5[386] 和 Llama3.2[97] 在 110 万个喷注(每类 100,000 个样本)上来评估它们。然后我们进行了零样本推理。如图 15 所示,结果显示 Llama3.2 仅实现了 0.09% 的准确率,而 Qwen 2.5 实现了 0%。这个结果表明,使用 BPE 分词器的主流 LLM 在处理大规模数值数据方面存在根本性的局限性。
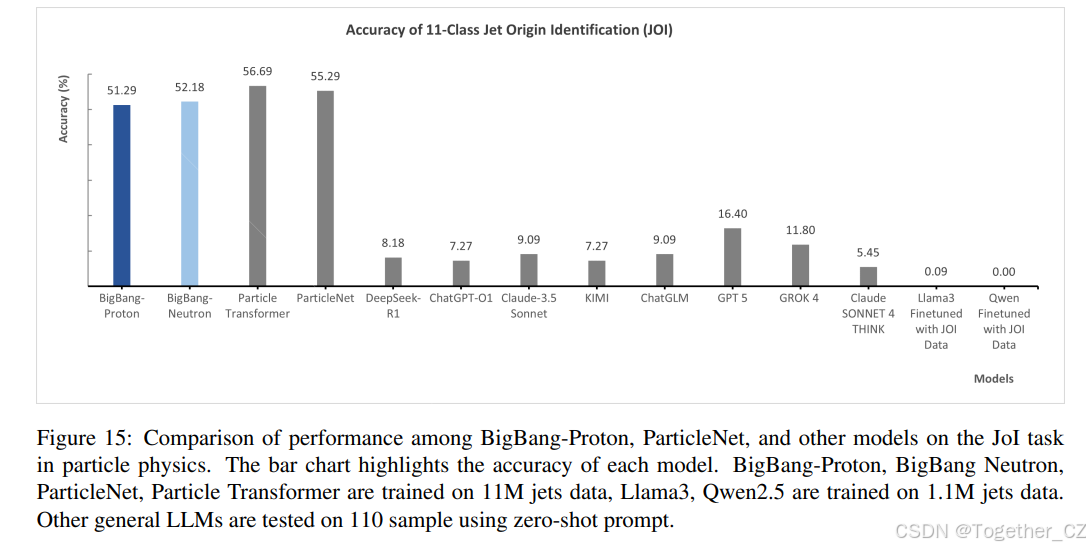
图 15: 在粒子物理中 JOI 任务上,BigBang-Proton、ParticleNet 和其他模型之间的性能比较。条形图突出了每个模型的准确率。BigBang-Proton、BigBang Neutron、ParticleNet、Particle Transformer 在 1100 万个喷注数据上训练,Llama3、Qwen2.5 在 110 万个喷注数据上训练。其他通用 LLM 在 110 个样本上使用零样本提示进行测试。
3.4 原子间势模拟:语言引导的回归
通过模拟原子晶格内大规模电子相互作用来准确预测材料性质,传统上依赖于高保真度的第一性原理方法,如密度泛函理论(DFT)[191] 和从头算分子动力学(AIMD)[230],它们通过显式计算电子结构来提供量子力学精度。然而,DFT 的计算复杂度随系统大小的立方阶缩放(O(N3)O(N3)),这使其对于大规模和长时间的计算不切实际。为了解决这个限制,已经开发了两种主要策略来降低原子模拟的计算复杂度。经典力场方法,使用经验性的原子间势来近似原子相互作用,显著降低了计算需求,但代价是与量子力学方法相比精度降低。第二种策略使用机器学习原子间势(MLIPs),它们在被 DFT 标记的数据集上训练以学习原子相互作用的替代模型[379]。MLIPs 在计算效率和准确性之间实现了有利的平衡,通常接近 DFT 的精度。当代的 MLIP 框架主要利用图神经网络(GNNs)[382, 27, 116, 26, 409, 112] 作为其底层架构,利用了原子系统的自然图结构(其中原子表示为节点,原子间相互作用表示为边)。为了泛化超越针对特定材料类别的特定任务模型,已经在周期表上预训练的通用 MLIP 模型(例如 M3GNet 和 DPA-2)[66, 75, 336, 407] 被开发出来。这些模型在来自跨广泛材料类型的 DFT 计算的多样化数据集上进行训练。尽管取得了这些成功,但基于 GNN 的 MLIPs 本质上受限于它们对可以从 DFT 计算中明确导出的原子结构数据的依赖,包括原子组成、晶体结构和量子力学性质,如能量、力、应力和磁矩[89, 165]。这些模型无法直接整合多模态数据,而多模态数据是材料科学中一个重要但未被充分利用的科学知识来源[43],包括晶体信息文件(CIF)数据集[17]、科学文献、实验测量的图像等。最近探索将 LLM 用于材料科学的努力[187, 64, 372, 259, 17] 特别侧重于在模型训练中整合文本数据,如简化分子线性输入规范(SMILES)字符串、CIF、化学式,忽略了作为数值数据存储的完整原子结构信息。这些在文本数据上预训练或微调的 LLM 通常无法处理涉及数值数据的回归任务,例如能量预测。Matterchat[339] 尝试开发 LLM 来生成语言引导的材料性质预测,包括回归任务,但依赖于外部的基于图的模型[89] 来提供晶体结构的嵌入知识。
在这个下游任务中,我们展示 BigBang-Proton(一个在混合多学科数据集,包括算术、粒子物理、材料科学、生物学上预训练的自回归 LLM)可以在稳定晶体的高通量材料发现中超越基于 GNN 的专用模型。仅通过下一词预测,BigBang-Proton 就可以处理 MLIP 中的分类和回归任务。对于大多数基于 LLM 的材料科学模型来说,回归任务很困难,因为 LLM 无法很好地学习和预测数值序列。相比之下,BigBang-Proton 在回归任务中表现出非凡的性能,例如形成能、力、应力、磁矩预测以及凸包以上能量的计算。
BigBang-Proton 从材料结构预测总能量
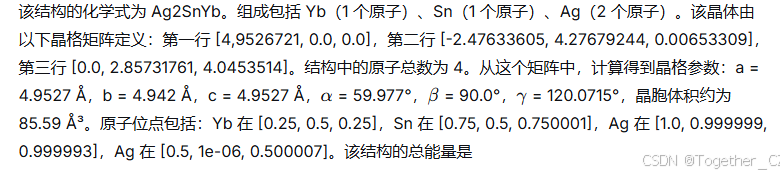
BigBang-Proton 回答: -12.8851 eV。

图 16: 使用 BigBang-Proton 通过零样本提示方法进行语言引导的原子间势模拟。材料结构数据被分解成部分,每个部分嵌入相应的文本描述中。BigBang-Proton 学习了整合理论描述和实验数据的完整上下文,以做出最终推断。与仅依赖数值数据进行回归的传统专用模型相比,这种方法利用了对齐的理论和实验上下文来进行回归。科学原理和事实,包括“化学式”、“组成”和“原子位点”,是模拟的组成部分。
BigBang-Proton 根据 MatBench[98] 材料发现[298] 兼容政策的要求,在材料项目的材料项目轨迹(MPTri)数据集上进行训练。MPTri[165] 是一个大型的 DFT 弛豫晶体结构数据库,主要来自实验测试的晶体,包含 94 种元素,145,923 种无机化合物,具体包括 1,580,395 个原子构型,1,580,395 个能量值,49,295,600 个力,7,944,833 个磁矩和 14,223,555 个应力。原子结构数据在训练前被统一转换为字节块序列。我们使用 Wang-Botti-Marques 数据集[357](包含 257,487 个结构)来评估经过 MPTri[165] 训练的 BigBang-Proton 在新材料发现[298] 上的能力。WBM 数据集是通过用化学性质相似的原子替换 MPTri[165] 中现有晶体结构中的原子生成的,这是根据对无机晶体结构数据库(ICSD)[37] 的统计分析定量定义的。描述晶体的自然语言上下文与原子结构数据对齐,如图 16 所示,以实现语言引导的材料结构预测。根据不同的场景需求,语言上下文可以扩展到长程思维链。
Matbench[98] 基准列出了 13 个任务,其中 10 个是回归任务,3 个是分类任务。对于 3 个分类任务,我们可以通过回归生成中间结果。我们选择回归任务形成能预测来展示 BigBang-Proton 在数值计算上的能力。如图 17 所示,BigBang-Proton 在形成能预测中实现了平均绝对误差(MAE)0.043 eV/原子,在撰写本文时在 Matbench 排行榜上排名第 11 位。BigBang-Proton 优于一些专门的机器学习方法,如 AMMExpress(MAE=0.117 eV/原子)[98]、表面络合建模 RF-SCM[48, 365, 101](MAE=0.117 eV/原子)、基于注意力的模型 CrabNet[354](MAE=0.086 eV/原子)和特征选择模型 MODNet[49, 50](MAE=0.045 eV/原子)。然而,它不如专门的 GNN,如 coGN[302](MAE=0.017 eV/原子)、ALIGNN[74](0.022 eV/原子)和 SchNet[306](0.022 eV/原子)。基于 LLM 的模型 Matterchat[339] 在 Matbench 形成能预测中实现了 0.121 eV/原子的均方根误差(RMSE),误差明显大于 BigBang-Proton。这表明,在专门 GNN 模型 CHGNet[89] 的嵌入上训练的通用大语言模型[167] 尚未获得与端到端训练的 BigBang-Proton 相同的对材料结构的理解。当前的实现仅使用了 15 亿参数的模型,训练数据有限,微调方法传统,通过扩展到更多参数、扩大训练数据集、融入先进的微调技术以及整合后训练强化学习方法,仍有巨大的改进空间。这些增强途径在我们的语言引导模拟框架内本质上是可及的,但对于传统的基于 GNN 的方法仍然不可能。
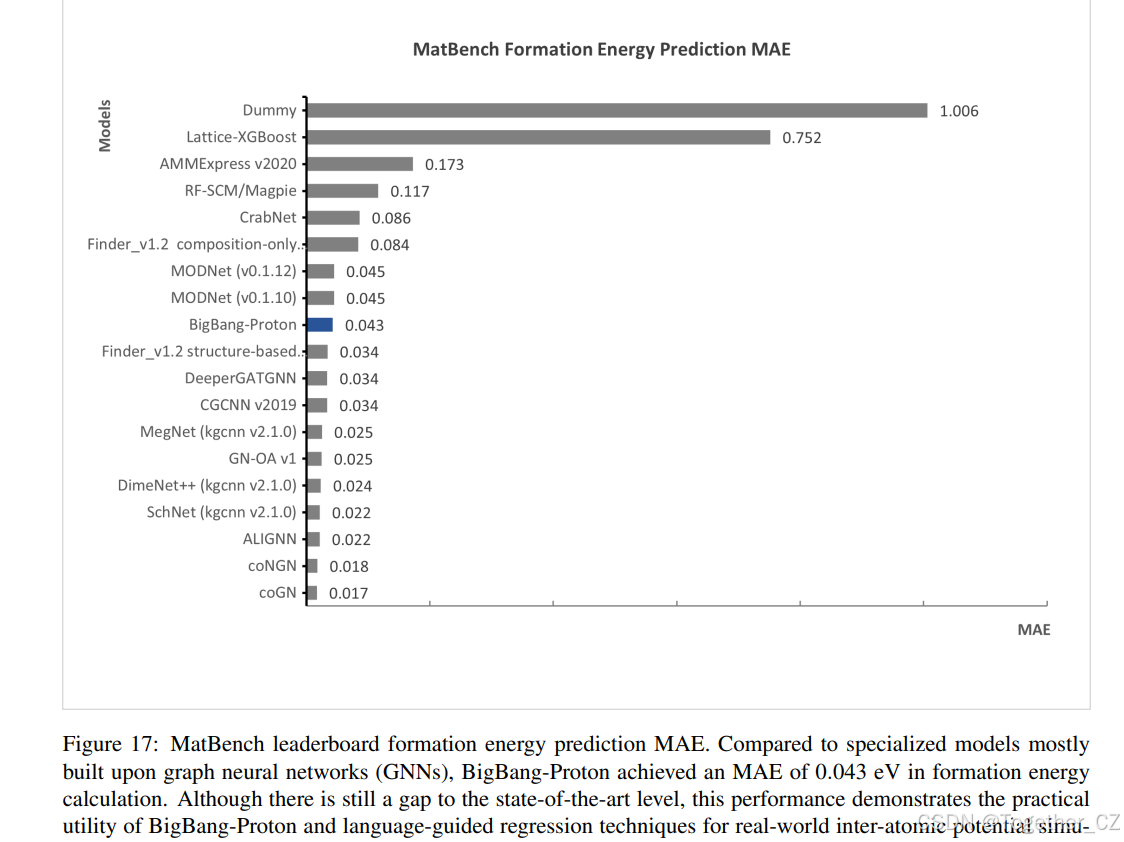
图 17: MatBench 排行榜形成能预测 MAE。与主要建立在图神经网络(GNNs)上的专用模型相比,BigBang-Proton 在形成能计算中实现了 0.043 eV 的 MAE。虽然与最先进的水平仍有差距,但这种性能证明了 BigBang-Proton 和语言引导回归技术在真实世界原子间势模拟任务中的实用性,验证了理论与实验对齐在计算材料科学中的有效性。
在图 18 中,我们比较了主流推理 LLM 的形成能预测性能,包括 DeepSeek R1(MAE:66.056 eV)、GPT 5(MAE:29.279 eV)、Claude Sonnet 4(MAE:57.377 eV)和 KIMI K2(MAE:517.006 eV)与 BigBang Proton(MAE:0.043 eV)。这些 LLM 的结果远未达到原子间势模拟的应用水平。在零样本学习方案中,我们提示模型预测 110 组形成能,输入来自 MPTrj[89] 测试数据集的原子结构。推理模型通常生成冗长而复杂的推理步骤,特别是 DeepSeek R1,如附录 A.3.3 所示,从解释数据集开始,进行一些简单的推断,如计算原子数量和能量值或数据集中明显的属性,然后对形成能进行最终猜测。有时 LLM 会尝试编写代码来执行计算,这不是我们期望的方法。虽然 LLM 展示了对基本原子结构配置的某些理解,包括原子计数和属性之间的定量相关性,但它们未能掌握决定总能量、形成能和其他物理量的底层物理机制。主流 LLM 与 BigBang-Proton 之间的巨大性能差距源于数据、分词和架构的差异。虽然主流 LLM 是在包含几乎所有已知凝聚态理论的整个互联网文本(包括科学文献和教科书)上进行预训练的,但它们没有在包含 DFT 模拟结果的数值数据集(如 MPTrj[89] 或 Materials Project[165])上进行训练,这使得它们无法从本质上学习原子间势。通常使用数值数据描述的物理结构(根据物理定律计算得出)无法分解为自然语言。虽然这些模型可以在这种特定任务数据上进行微调,但它们对 BPE 分词器的依赖从根本上阻碍了有效的数值学习,正如 Matterchat[339] 与 BigBang-Proton 相比的性能所证明的那样。此外,使用主流 LLM 作为调用基于特定任务模型构建的外部工具[122] 的科学智能体,将把发现能力限制在这些专用模型的范围内。
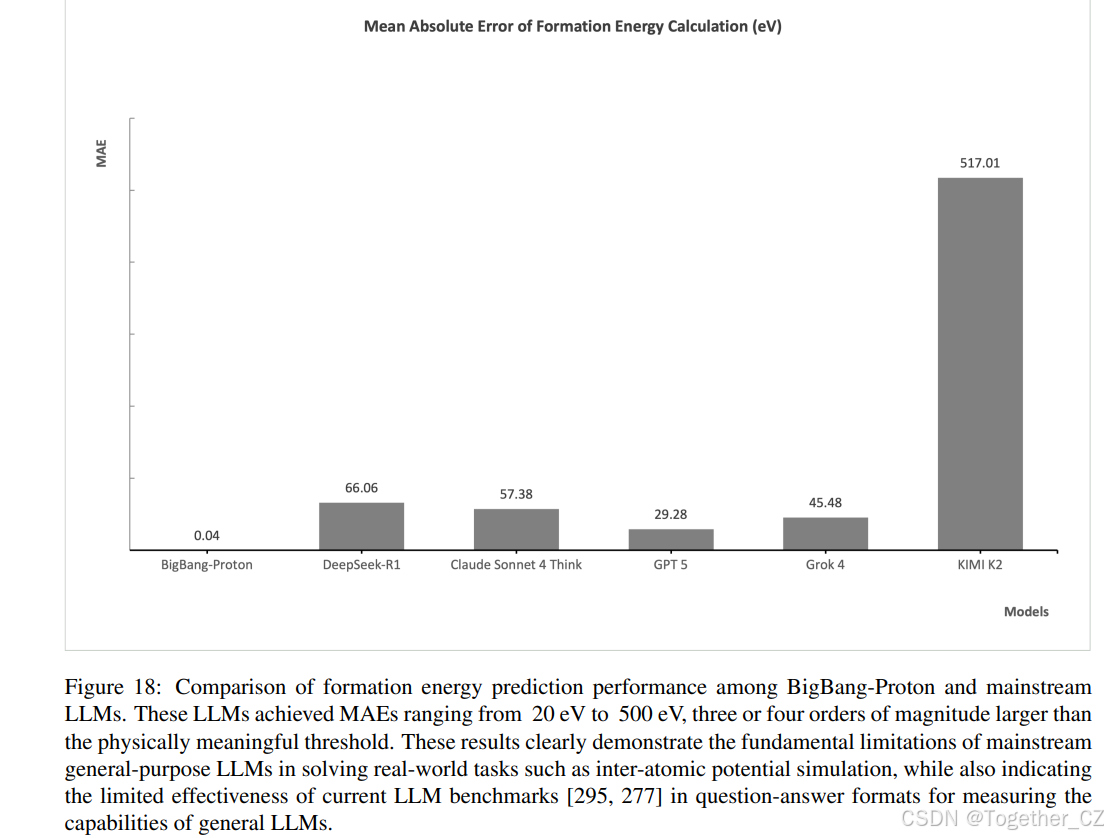
图 18: BigBang-Proton 与主流 LLM 在形成能预测性能上的比较。这些 LLM 的 MAE 范围从 20 eV 到 500 eV,比物理上有意义的阈值大了三到四个数量级。这些结果清楚地展示了主流通用 LLM 在解决真实世界任务(如原子间势模拟)方面的根本局限性,同时也表明当前 LLM 基准测试[295; 277] 的问答格式在衡量通用 LLM 能力方面效果有限。


3.5 湖泊水质预测:语言引导的时空预测
地球系统建模代表了人类理解和预测大气圈、水圈、冰冻圈、陆地表层和生物圈之间复杂相互作用的雄心勃勃的努力[148]。在此框架内,水循环建模是一个关键组成部分,涵盖海洋和大陆水系统。大陆水建模侧重于淡水系统,特别是湖泊和河流,它们是环境变化的哨兵,在全球生物地球化学循环中发挥着不成比例的重要作用。湖泊水质[65, 334] 预测作为一个典型的跨学科任务,位于地球科学、湖沼学、生物学、化学、环境工程和经济学的交叉点,是地球系统建模中最具挑战性的方面之一。与数值天气预报[296, 41]类似,许多用于通过机器学习方法进行水质预测的数值模型已经被开发出来[177, 201, 203]。叶绿素-a 浓度[385, 393, 399, 198, 186, 240, 326, 252] 作为藻类生物量和生态系统健康的主要指标[353, 211],是水质预测的关键因素。其内在困难在于叶绿素动态受多种因素控制,包括太阳辐射、温度、风、营养物负荷、水停留时间、内部生物地球化学过程和人为影响。
在此任务中,我们旨在基于叶绿素-a 浓度的历史时空数据预测水质。BigBang-Proton 已经在 2.62 亿字节的时空传感器数据上进行了预训练。我们进一步在湖泊水质数据上对 BigBang-Proton 进行了微调。湖泊水质数据集由中国无锡市太湖中部署的传感器收集。传感器每 30 秒收集一次数据,总共持续 2 年。80% 的数据集用于训练,20% 用于评估。如图 20 所示,该数据集包括带有日期信息的时间戳、由纬度和经度指定的精确位置,以及一套全面的水质参数。这些参数涵盖营养物质(包括氨氮、总氮和总磷)、光学性质(如浊度、TSM、C550、SDD、CDOM 吸收系数和高锰酸盐指数)、物理参数(如气温)以及预测的目标变量(以 μg/Lμg/L 为单位的叶绿素-a)。我们仅使用从湖泊中心区域单个位置收集的数据进行训练。
BigBang-Proton 的微调利用了序列到序列的方法,其中输入是从传感器收集的完整时间序列数据,包括过去五个连续时间点的叶绿素-a 浓度值和其他参数,输出是未来某个时间点预测的叶绿素-a 浓度。提示-叶绿素-a 如图 20 所示。最终目标是最小化平均绝对误差(MAE)指标。
结果表明,该模型在叶绿素-a 浓度预测中实现了 0.58 μg/Lμg/L 的 MAE。这表明模型能够有效地捕捉各种环境和水质参数之间的时间依赖性,从而进行准确的预测。除了 MAE,我们还使用平均绝对百分比误差(MAPE)来评估模型,以提供对预测准确性的更全面评估。MAPE 定义为:

如图 20 所示,叶绿素-a(Chl-a)动态由 12 个上下文变量驱动,包括氨氮、浊度、总氮、总磷、悬浮物浓度、消光系数、气温、异物检测、塞奇深度、高锰酸盐指数、CDOM 吸收系数和 pH 值,所有这些都在时空维度上进行测量。BigBang-Proton 通过将它们的集体非线性相互作用视为一个上下文学习问题,消除了专用时间序列建模中所做的手动特征工程。模型不是从孤立的预测因子推断 Chl-a,而是从复杂系统形成的演化、高维上下文中进行推断。
此外,使用理论与实验对齐在科学多任务数据集上训练的 BigBang-Proton,不仅捕捉了局部系统的时间动态,还捕捉了可能对应于不同尺度的真实世界物理或环境过程的上下文关系。这使得模型能够将水质变化预测为更广泛的时空和因果框架的一部分。这些结果表明,BigBang-Proton 中使用的建模方法可以扩展到湖泊系统之外,用于建模更大规模和更复杂的系统,从区域气候到地球系统。

图 20: 使用 BigBang-Proton 进行语言引导时空预测的湖泊水质示例说明。每个提示以时间序列数据输入开始,然后明确指示模型根据给定上下文确定叶绿素-a 浓度。这些来自传感器的多因素时间序列数据,定量描述了物理世界指标的波动。时间序列建模被转化为 BigBang-Proton 的上下文学习和推理。
3.6 语言引导的基因组序列建模
BigBang-Proton 的一个关键下游任务是基因序列预测,重点是理解和预测基因序列的功能和进化特征。这些序列编码驱动生物体发育、功能和适应的生物学指令。跨物种和个体的基因组序列变异反映了进化过程,例如自然选择和遗传漂变,这些过程塑造了生物多样性并使生物能够适应不断变化的环境[241, 366, 251]。高通量测序技术的最新进展使得生成大量基因组数据成为可能,为在全基因组尺度上研究这些变异提供了前所未有的机会[313]。
在计算生物学领域,已经开发了专门的模型来应对特定的挑战。例如,AlphaFold 代表了一系列最先进的用于蛋白质结构预测的特定任务模型,使用扩散架构[174, 3]。AlphaFold 系列在从氨基酸序列预测三维蛋白质结构方面取得了显著成功。
igBang-Proton DNA 序列生成
相反,Evo 是一个创新的基础模型,它将 DNA、RNA 和蛋白质序列整合到一个统一的框架中进行联合训练[250]。通过结合来自多个生物层的信息,Evo 为基因组内部和基因组之间的复杂相互作用提供了新的见解,使得能够更准确地预测基因功能和进化路径。
在预训练阶段,我们将相同的 OpenGenome 数据集[250](包含 273 亿个核苷酸 token,大约是 Evo 所用数据的十分之一)与粒子物理、材料结构、算术、传感器和通用文本的数据集混合,来预训练 BigBang-Proton。OpenGenome 数据集包括超过 80,000 个细菌和古细菌基因组,以及数百万个预测的噬菌体和质粒序列,覆盖约 3000 亿个核苷酸 token。出于安全考虑,感染真核宿主的病毒基因组被排除在训练数据之外。在下游任务阶段,我们进一步用 828 亿个核苷酸 token 对预训练模型进行了微调。BigBang-Proton 总共学习了约 1101 亿个 token。
该数据集用于使用下一 token 预测范式训练模型,模型学习根据给定的输入序列预测下一个核苷酸。这种方法使模型能够纯粹从序列上下文中理解复杂的基因组结构,而不依赖显式注释。如图 21 所示,模型的提示-答案案例展示了其预测给定基因序列输入后接序列的能力。例如,给定一个基因序列的初始片段,BigBang-Proton 可以预测该序列最可能的延续,有效地捕获基因组数据中的长程依赖关系和微妙模式。通用 LLM 的相同零样本基因组预测示例可以在附录 A.3.4 中看到,其表现接近随机猜测。
OpenGenome 数据集提供了来自不同生物体的大量基因组序列集合。通过预测序列中的下一个核苷酸,BigBang-Proton 可以隐含地理解复杂的基因组特征,如启动子、增强子和非编码 RNA。这种方法允许模型纯粹基于序列上下文发展对多种基因组元素的理解。

图 21: 使用 BigBang-Proton 进行零样本基因序列补全的示例说明。用户用核苷酸序列的初始 DNA 片段提示,模型生成延续以完成该序列。生成的核苷酸序列的准确性也反映在训练困惑度上。
BigBang-Proton 预测突变对蛋白质功能的影响
用户
DNA 序列:
TATCTAAAAGAAGACAATATTGAAATGCAAAGGTACCGTTCTTGAACGGTTGCCTAATACCATGTTCCGCG
TAGAGTTAGAAAAGCGTACGGTGCTTACTGCACACATCTCCGGTAAAATGCGCAAAACTCACATCCGCA
TCCTGACGGGCGACAAGTGACTGTTGAACTGACCCCGTACGACCTGAGCAAAGGCCGCATTGTCCTTC
CGTAGTCCGTGA
BBT 回答
预测:0.5671418309211737;真实值:0.559
(a) 突变对蛋白质功能影响的预测
BigBang-Proton 预测突变对非编码 RNA 功能的影响
用户
DNA 序列:
CCGCCTAACACTGCCATTGCCGGTCCCAAGCTCGGATAAAAGTGGAGGGGGGGG
BigBang-Proton 回答
预测:0.2560504674911499;真实值:0.25
(b) 突变对非编码 RNA 功能影响的预测
BigBang-Proton 预测调控 DNA 的活性
用户
DNA 序列:
TTTTCTATCTACGTACTTCAACCTATTTCCTATTTCCTTATAATTTGTGTCTCTACCTTAGTTTGTC
GTT
BigBang-Proton 回答
预测:-2.632388114929199;真实值:-2.694640757
(c) 调控 DNA 的活性


图 22: BigBang-Proton 在蛋白质、非编码 RNA、调控 DNA 上进行零样本功能预测的示例说明,使用深度突变扫描(DMS)数据集,其中测量了每个蛋白质突变的功能适应度分数。子图显示了基于输入序列片段的预测适应度。最终计算预测适应度数据集与标签之间的斯皮尔曼相关性。
我们将最大序列长度设置为 16,384 个 token,以容纳长基因组序列,同时平衡计算效率。序列被填充或截断到固定长度,以在训练期间保持一致性。模型训练了 5 个周期,并基于验证集困惑度进行早停以避免过拟合。BigBang-Proton 利用其从序列数据中学习复杂模式的能力来分析和预测 DNA、RNA 和蛋白质的功能作用。通过捕捉基因组序列内错综复杂的关系和相互作用,模型可以推断特定的遗传变异如何影响生物过程、导致疾病机制或决定表型性状。这种能力使该模型成为基因组学的通用基础模型,能够学习基因组组织和功能的底层原理。这样的模型有潜力加速功能基因组学、进化生物学和精准医学等领域的发现,使研究人员能够解码编码在遗传序列中的生命逻辑。
类似于 Evo[250] 中的缩放定律分析,我们在相同的实验设置下,就计算预算缩放对 BigBang-Proton 和 Evo 进行了详细比较。计算最优指的是在模型大小和训练 token 之间理论上最优的计算资源(FLOPs)分配,以实现最佳性能。对于此比较,我们在两个模型中保持数据集大小一致,并主要将评估困惑度(Eval PPL)作为主要指标。困惑度是序列建模任务中广泛使用的度量,较低的值表示更好的模型性能。
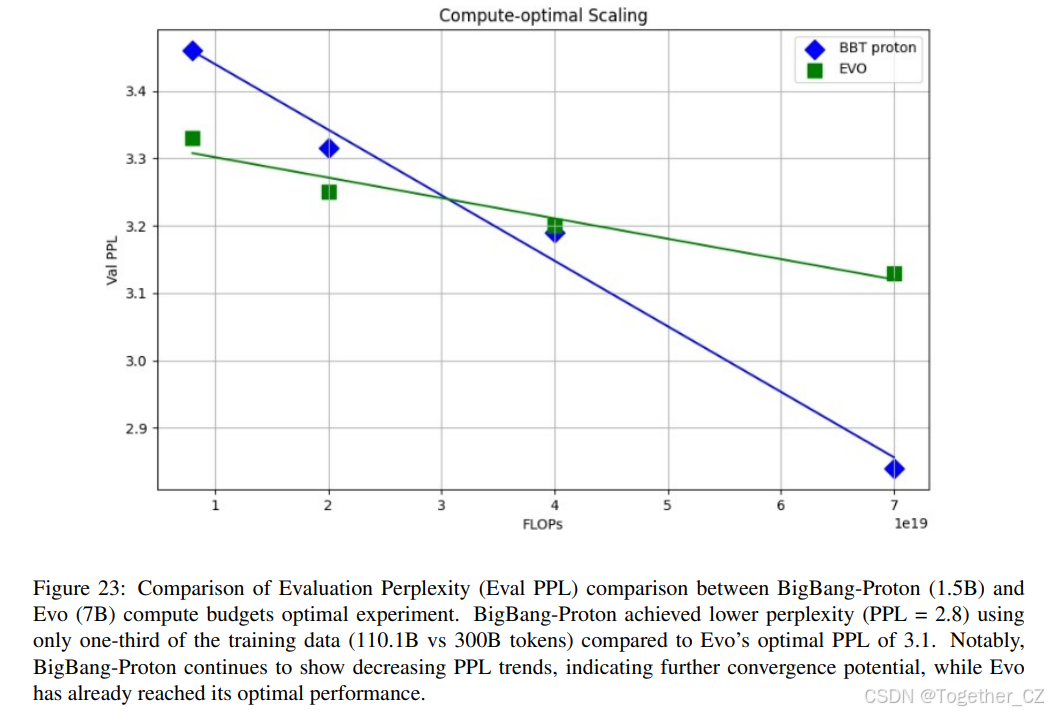

图 23: BigBang-Proton(1.5B)与 Evo(7B)在计算预算最优实验中的评估困惑度(Eval PPL)比较。BigBang-Proton 仅使用 Evo 训练数据量的三分之一(110.1B vs 300B tokens)就达到了更低的困惑度(PPL = 2.8),而 Evo 的最优 PPL 为 3.1。值得注意的是,BigBang-Proton 继续显示出下降的 PPL 趋势,表明还有进一步的收敛潜力,而 Evo 已经达到了其最优性能。
已经饱和,无法进一步提高。BigBang-Proton 在使用明显更少的训练数据和更小的模型规模的情况下性能优于 Evo,这一巨大差异强有力地证明了 BigBang-Proton 在基因组序列建模方面的架构优越性。
如图 24 所示,主流 LLM 如 12 亿参数的 Llama3 在 30 亿 OpenGenome tokens 上使用 LoRA 微调后,PPL 达到 6.23,15 亿参数的 Qwen2.5 达到 6.89。这个结果显示出比 BigBang-Proton 和 Evo 高得多的困惑度,突显了它们在基因组序列建模方面的局限性。巨大的性能差距表明,主流 LLM 中使用的 BPE 分词器从根本上破坏了其对 DNA 核心核苷酸词汇表 A、G、T、C 的理解。

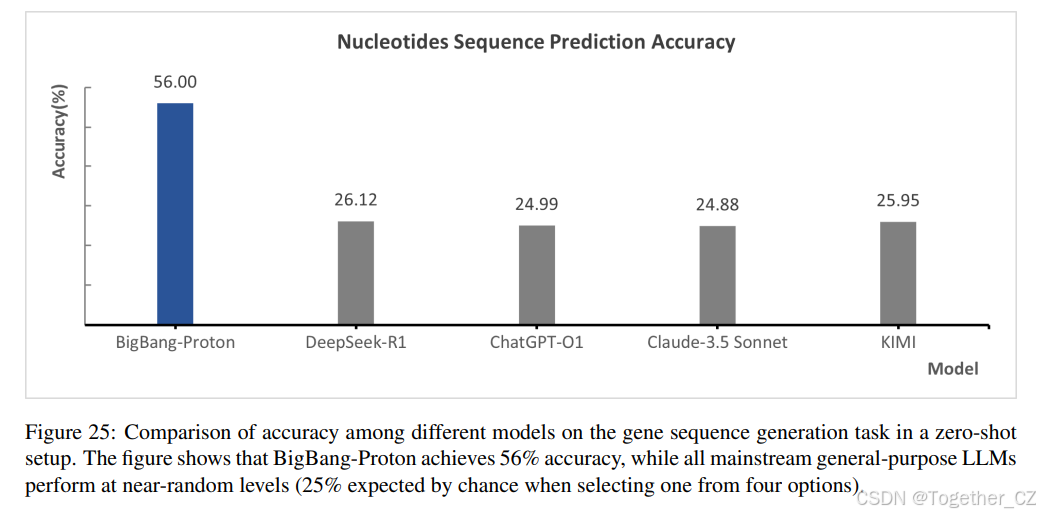
基线模型在少样本设置下进行评估。每个模型在相同的少样本条件下进行测试,使用相同的评估数据集。结果如图 25 所示,表明 BigBang-Proton 始终优于基线模型,准确率达到 56%,而 DeepSeek-R1、ChatGPT-o1、Claude-3.5 Sonnet 和 Kimi 的准确率分别为 26.1%、25.0%、24.88% 和 25.95%。所有通用 LLM 的表现都在机会水平(25±1%)左右,表明这些模型从根本上未能学习到管理基因组序列的复杂统计模式、生物学规则和位置依赖关系。这些结果对应于附录 A.3.4 中所示的 DNA 序列补全示例。尽管它们在不同文本语料库上进行了大量训练,但通用 LLM 缺乏专门的归纳偏置、适当的分词方案以及足够的基因组数据暴露,这些对于捕捉超越简单字符级记忆的核苷酸之间错综复杂的关系是必要的。接近随机的表现表明,通用 LLM 无法有效地将其语言理解能力迁移到高度专业化的基因组学领域,在该领域中,进化约束、结构基序、调控元件和长程依赖关系创造了从根本上不同于自然语言结构的模式复杂性。
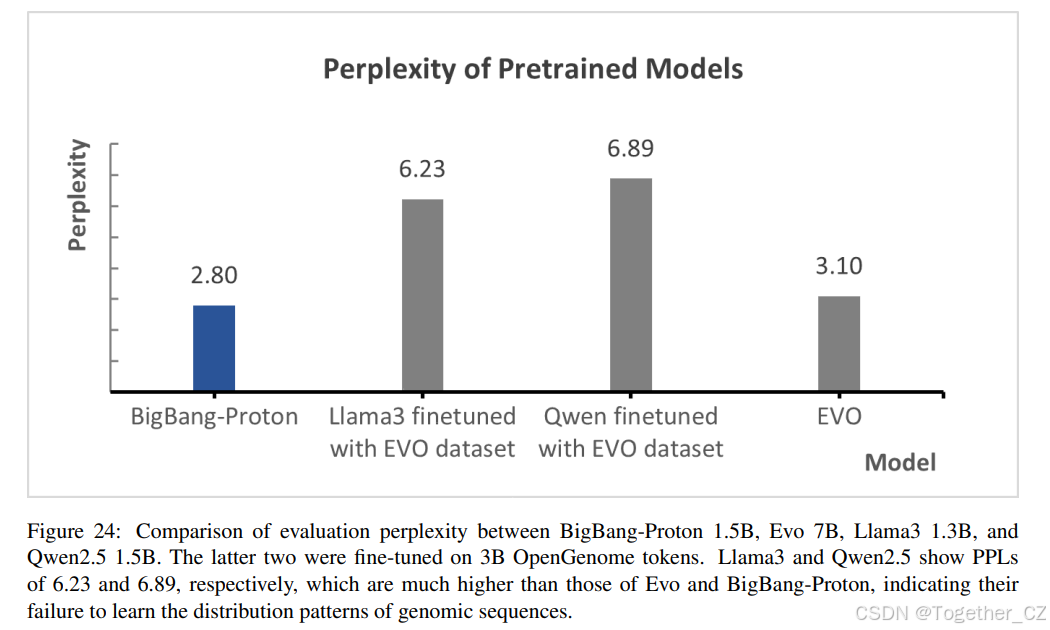
图 24: BigBang-Proton 1.5B、Evo 7B、Llama3 1.3B 和 Qwen2.5 1.5B 的评估困惑度比较。后两者在 30 亿 OpenGenome tokens 上进行了微调。Llama3 和 Qwen2.5 的 PPL 分别为 6.23 和 6.89,远高于 Evo 和 BigBang-Proton,表明它们未能学习基因组序列的分布模式。
预测突变对蛋白质功能的影响 除了评估困惑度,我们进一步评估了模型在具有生物学相关性的下游任务上的零样本预测能力,预测突变对蛋白质功能的影响是关键任务之一。我们的方法使用实验测量的功能活性或适应度分数作为监督微调的目标。这种方法允许模型明确学习核苷酸突变与其功能后果之间的关系。
为了评估模型的性能,我们采用了深度突变扫描(DMS)研究,这些研究系统地将突变引入蛋白质编码序列,并通过适应度指标[256] 实验量化它们对功能活性的影响。我们没有依赖氨基酸序列,而是通过使用野生型编码序列和原始 DMS 研究中报告的特定核苷酸突变,将这项任务调整为适用于核苷酸序列。我们使用了来自大肠杆菌 DMS 研究的核苷酸序列。对于 Evo,使用了来自六项研究的数据集来编译核苷酸信息,包括 Fimberg 等人(2014)[106] 的 β-内酰胺酶 DMS、Jacquier 等人(2013)[162] 的 β-内酰胺酶 DMS、Adkar 等人(2012)[5] 的 CcdB DMS、Tsuboyama 等人(2023)[346] 的多蛋白热稳定性数据集、Kelsic 等人(2016)[183] 的 IF-1 DMS,以及 Weeks 和 Ostermeier(2023)[368] 的 Rnc DMS。在我们的实验中,我们特别使用了 Kelsic 等人(2016)[183] 的 IF-1 DMS。实验测量的适应度分数作为训练和评估模型的基本事实。
我们的结果(图 26A)表明,模型可以有效地预测突变的功能后果,在模型的预测与实验适应度分数之间实现了 0.78546 的强斯皮尔曼相关性(p 值:4.94e-41)。这显著优于性能最佳的基线模型 Evo,后者在六个数据集上的最大斯皮尔曼相关性为 0.67,平均为 0.45。此外,我们在同一任务上使用零样本测试将我们的模型与其他几个先进模型进行了比较,DeepSeek R1 达到的斯皮尔曼相关性为 (-0.02),ChatGPT o1 为 (-0.06),Claude 3.5 Sonnet 为 (-0.11),KIMI 为 (-0.02)。这些比较突显了我们的模型在预测突变效应方面的优越性能。
预测突变对非编码 RNA 功能的影响 接下来,我们评估了模型预测非编码 RNA(ncRNA)中突变功能后果的能力。包括 tRNA(蛋白质合成适配器)、rRNA(核糖体结构组件)和核酶(催化性 RNA)在内的 ncRNA 通过其依赖序列的结构执行基本的细胞功能,其功能受到核苷酸突变的严重影响,这些突变可以改变折叠、稳定性和催化活性。类似于用于蛋白质编码序列的方法,我们收集了 ncRNA 深度突变扫描(DMS)数据集,并使用实验测量的适应度分数作为监督微调的基本事实。这使我们能够测试模型是否能够将其预测能力泛化到 ncRNA 序列,这些序列在细胞过程中发挥着关键作用,但在结构和功能上与蛋白质编码序列有显著差异。Evo 使用了七个数据集来评估模型在 ncRNA 功能预测中的零样本能力,包括 Kobori 等人(2015)[190] 的核酶 DMS、Andreasson 等人(2020)[16] 的核酶 DMS、Domingo, Diss, and Lehner(2018)[94] 的 tRNA DMS、Guy 等人(2014)[137] 的 tRNA DMS、Hayden, Ferrada, and Wagner(2011)[145] 的核酶 DMS、Pitt and Ferre-D'Amare(2010)[278] 的核酶 DMS,以及 Zhang 等人(2009)[412] 的 rRNA 诱变研究。我们使用 Kobori 等人(2015)的核酶 DMS 进行我们的监督微调。
我们的结果(图 26B)表明,模型在预测非编码 RNA(ncRNA)突变的功能效应方面表现出强大的性能。在 Kobori 等人(2015)[190] 的 DMS 数据集(测量突变对 ncRNA 功能的影响)上,模型达到了 0.68 的斯皮尔曼相关系数,显著优于 Evo 模型报告的最佳结果(Evo 在七个数据集的预测中最大斯皮尔曼相关性为 0.65,平均为 0.25)。这一改进突显了模型在推断 ncRNA 序列突变功能影响方面的增强能力。
为了进一步验证我们的发现,我们在同一任务上使用主流通用 LLM 进行了零样本测试,结果如下:DeepSeek R1 0.19,ChatGPT o1 -0.02,Claude 3.5 Sonnet -0.16,KIMI -0.01。结果表明,这些模型在 DMS 数据集上测试时获得的斯皮尔曼相关系数接近零。结果强调了我们的模型在处理 ncRNA 突变预测任务方面的独特能力,证明了其在该领域的稳健性和有效性。
根据调控 DNA 预测基因表达 鉴于我们模型的训练数据也包括原核调控 DNA 序列,我们进一步研究了模型是否学习了有意义的表示,可以应用于调控 DNA 任务。具体来说,我们专注于根据启动子序列预测基因表达。类似于我们对蛋白质编码和 ncRNA 任务的方法,我们使用实验测量的活性值作为监督微调的目标,确保模型的预测直接与生物学相关的结果相联系。
启动子是控制基因转录起始的关键调控 DNA 元件。我们评估了模型根据启动子序列预测基因表达水平的能力。通过利用实验测量启动子区域突变对基因表达影响的数据集,我们训练模型直接预测这些表达水平。使用 Fleur, Hossain, and Salis(2021)[107] 报告的数据集,模型的预测与实验测量的基因表达水平之间达到了 0.72 的斯皮尔曼相关性(图 26C)。这一性能显著优于 Evo 报告的最佳结果(Evo 在同一任务上达到的斯皮尔曼相关性为 0.68)。这一改进突显了模型捕捉嵌入在启动子序列中的调控逻辑并泛化以预测功能结果的增强能力。
为了进一步验证我们的发现,我们在同一任务上使用主流通用 LLM 进行了零样本测试,结果如下:DeepSeek R1 0.11,ChatGPT o1 -0.14,Claude 3.5 Sonnet 0.06,KIMI 0.06。结果表明,这些模型在启动子序列数据集上通过提示测试时获得的斯皮尔曼相关系数接近零。接近零的相关值(0.11 和 0.06)表明,这些模型实际上是在做随机预测,与实际基因表达水平没有有意义的关系,其表现仅略高于随机猜测的期望机会水平。ChatGPT o1 的负相关系数 -0.14 表明,它的预测不仅不正确,而且与实际表达水平呈负相关,这表明它学习了虚假模式,或者由于不当的偏置或对启动子生物学的基本误解而产生了比随机猜测更严重的系统性错误。
BigBang-Proton 在分子尺度生物学任务上持续超越 Evo 跨三个不同的分子尺度生物学任务的综合评估表明,与 Evo 相比,BigBang-Proton 具有优越的性能,在所有领域都有一致且显著的改进。在预测突变对蛋白质功能的影响方面,BigBang-Proton 达到 0.78546 的斯皮尔曼相关性,而 Evo 为 0.67,代表了 17% 的相对改进。对于 ncRNA 突变预测,BigBang-Proton 达到 0.68 的相关性,而 Evo 为 0.65,显示出 5% 的增强。在调控 DNA 活性预测方面,该模型达到 0.72,而 Evo 为 0.68,展示了 6% 的改进。这些结果确立了 BigBang-Proton 在多样化分子生物学应用中的全面优势,表明其架构创新和训练范式比 Evo 的方法能更有效地学习序列-功能关系。关键的是,这些性能增益与基于困惑度指标的缩放定律分析完全一致,在该分析中,BigBang-Proton 在不断增加的计算预算中显示出持续更低的 PPL 值。PPL 改进与下游任务性能之间的相关性验证了模型在建模基因组序列分布方面的增强能力直接转化为更好的生物学理解和预测准确性。
通用 LLM 未能学习分子尺度的生物学任务 跨所有三个分子尺度生物学任务一致接近零和负相关的结果表明,通用 LLM 从根本上无法理解生物序列-功能关系。在蛋白质突变预测、ncRNA 突变预测和调控 DNA 活性预测中,主流模型包括 DeepSeek R1、ChatGPT o1、Claude 3.5 Sonnet 和 KIMI 主要获得的相关系数接近零(0.11、0.06、0.19、-0.02、-0.01、0.06),表明其性能等同于随机猜测,并证明这些模型未能捕捉控制分子功能的复杂统计模式和生物学规则。更令人担忧的是在 ChatGPT o1 中观察到的系统性负相关(启动子为 -0.14,蛋白质突变为 -0.06,ncRNA 为 -0.02),这表明该模型不仅未能学习有意义的生物学模式,而且实际上在序列特征和功能结果之间发展了反向关系,暗示存在不当的偏置或对分子生物学原理的根本误解。这些结果共同表明,尽管通用 LLM 在自然语言任务中取得了成功,但它们缺乏专门的归纳偏置、适当的分词方案以及足够的领域特定训练,这些是将它们的能力迁移到高度专业化和定量精确的分子生物学领域所必需的,在分子生物学中,准确的序列-功能预测需要深入理解生化约束、进化压力以及从根本上不同于语言模式的结构-功能关系。
为什么 BigBang-Proton 能更好地学习基因组? 综合的实验结果表明,BigBang-Proton 在基因组序列建模方面显著优于 Evo。以下根本性的架构和训练创新可能解释了为什么 BigBang-Proton 能比 Evo 更好地学习 DNA 序列。首先,理论与实验学习与二进制块编码相结合,比 Evo 的方法提供了根本性优势。该框架将科学文献中的理论知识与实验基因组序列 A、G、T、C 相结合。虽然两种方法都使用字符级分词,将单个核苷酸保留为 UTF-8 索引(A=65,T=84,G=71,C=67),但关键区别在于上下文学习。Evo 将这些视为孤立的符号,依赖于强力模式识别,而 BigBang-Proton 将它们嵌入到来自科学文本的生物学语境中,使得核苷酸能够携带其作为腺嘌呤、胸腺嘧啶、胞嘧啶和鸟嘌呤的真实生物学意义。模型学习生物学先验知识,例如与生化性质、功能角色和进化约束的关联,从而发展了丰富的归纳偏置来指导序列模式学习。这解释了 BigBang-Proton 在更低困惑度(在 7×10197×1019 FLOPs 时 2.8 对比 3.1)和更高斯皮尔曼相关性(蛋白质突变为 0.785 对比 0.67,ncRNA 为 0.68 对比 0.65,启动子为 0.72 对比 0.68)方面的优越性能。其次,跨学科迁移学习实现了结构之间的泛化,这是 BigBang-Proton 性能优于单领域模型 Evo 的一个关键假设。BigBang-Proton 在多样化的数据上进行训练,包括算术运算、粒子喷注、材料晶体、传感器和股票价格。

图 26: 该图展示了 BigBang-Proton、Evo 和主流 LLM 在功能适应度预测上的性能:(A) 预测突变对蛋白质功能的影响,(B) 预测突变对非编码 RNA 功能的影响,以及 (C) 预测调控 DNA 的活性。BigBang-Proton 在所有三项任务中都超过了 Evo,斯皮尔曼相关系数的优势幅度在 0.03 到 0.11 之间。而通用 LLM 主要显示出负相关和低相关,表明它们无法捕捉基因组序列中与功能适应度相关的模式。
物理学原理如量子力学既支配材料晶体也支配生物大分子,这表明存在共享的同构属性,使得跨领域迁移学习成为可能。第三,蒙特卡洛注意力通过理论上无限扩展实现了基因组尺度上下文处理。虽然 Evo 的 131k token 限制约束了对长程基因组依赖关系的捕获,但 BigBang-Proton 的蒙特卡洛注意力可以通过块间委托处理整个基因组尺度的序列,这对于理解跨越数千到数十亿碱基对的复杂现象(如长程调控相互作用和染色体组织)至关重要。
通用 LLM 未能学习基因组序列,原因是 BPE 分词与 A G T C 序列的根本不兼容性,因为子词合并破坏了单核苷酸分辨率并产生语义歧义;因此,它们在预训练中排除了 DNA 测序数据,导致失去了捕获序列和功能模式所必需的生物学归纳偏置。
3.7 科学多任务学习:设计与意义
算术运算是科学多任务学习的核心,因为实验结果主要是数值的。BigBang-Proton 融合了粒子喷注、材料晶体、基因组序列和水质,代表了从夸克到地球系统的尺度。多样化的数据集在预训练期间在表示空间中对齐而没有冲突,显示了在潜在空间中转移的可能性,尤其是在相邻尺度之间存在相似性。量子力学支配着材料和生物系统中的原子相互作用,这表明 DNA 和蛋白质反映了量子效应,导致了分布的同质性。质子和中子与电子形成原子,而晶体形成能则源于电子相互作用。夸克衰变分布可能与材料结构有相似之处,有助于形成能计算。水质代表了一个受多种因素影响的复杂系统。材料和生物结构可能与水质数据表现出相似性。数论揭示了宇宙中固有的数值结构。算术逻辑单元模拟可以增强跨所有尺度的学习。
在涵盖所有尺度、结构和学科的数据集上预训练一个基础模型,将为物理结构中隐藏的类比提供更深入的见解。这种方法融合了还原论和涌现论,将宇宙视为一个统一实体来探索基本定律。
4 相关工作
LLM 在真实世界科学中的应用 迄今为止,关于使用主流 LLM(包括基础版本(通过监督微调和 RLHF 后训练)或推理版本(通过长程思维链后训练))来解决真实世界科学问题的出版物有限。LLM 用于科学研究的主要用途发生在文献搜索、写作和代码生成方面。在理论凝聚态的一个案例中[395],研究人员提示 OpenAI 的 o3-mini-high 来推导 UNPC 在伊辛模型中临界温度的精确方程,尽管最初存在错误,但发现了一种基于对称性的块对角化,将一维 J1-J2 三态 Potts 模型的 9×9 转移矩阵简化为可解的 2×2 形式。DeepMind 开发了 FunSearch [299],一种使用 LLM 以计算机代码形式生成创造性解决方案的方法,为帽集问题带来了新的数学发现,并改进了装箱问题的算法,这标志着 LLM 首次被用于在发表当年(2023年)解决科学和数学中具有挑战性的开放问题。这些案例都依赖于 LLM 的语言生成能力。
科学智能体 为了扩展 LLM 完成科学任务的能力,已经开发了多个基于智能体的系统。Ghareeb 等人(2025)[122] 发布了 Robin,一个用于自动化科学发现的多智能体系统,包括 Crow 和 Falcon 作为生成假设的文献综述智能体,以及 Finch 作为实验分析智能体,该智能体在 Aviary[248] 上实现,Aviary 是一个用于科学任务的语言智能体框架,用于与数据分析工具交互。Finch 与 edit_cell(一个专为生物信息学工作流程设计的用于智能体修改和执行 Jupyter 笔记本中代码单元的专业数据分析工具)以及 submit_answer(一个最终确定智能体分析并提交结论(如图形、表格和解释)的工具)进行交互。这些由 Aviary 环境支持的工具是典型的领域数据分析工具,是为特定科学领域的专门应用独立开发的。Qiu 等人(2025)[284] 开发了 BioMARS,一个端到端的科学多智能体系统,集成 LLM 和 VLM(视觉-语言模型)以自动化生物学实验,包括基于 LLM 和 RAG 的用于分析文献和合成协议的生物学家智能体,用于将语言协议转换为机器人操作的技术员智能体,以及基于 ViT(视觉 Transformer)用于监督实验过程的检查员智能体。Gottweis 等人(2025)[128] 发表了 AI co-scientist,一个建立在 Gemini 2.0[126] 之上的多智能体系统,它作为科学家的协作工具,通过受科学方法启发的专门智能体(例如,生成、反思、排名、进化、元评审)生成新的假设和研究提案。这些智能体使用自动化反馈循环、网络搜索等工具以及用于高级推理的测试时计算缩放来迭代地完善假设。Su 等人(2024)[325] 发表了 VirSci,这是一个基于 LLM 的多智能体系统,旨在通过组织智能体团队,使用反馈循环和领域特定工具迭代生成、评估和完善假设来模拟协作科学研究。Lu 等人(2024)[220],Yamada 等人(2025)[384],Lu 等人(2024)[219] 来自 Sakana AI 发表了 AI Scientist,这是一个端到端的智能体系统,能够自主地制定科学假设、设计和执行实验、分析数据以及撰写手稿——成功生成了几篇经过同行评审接受的研讨会论文。Giglou, D'Souza, and Auer (2024)[123],Agarwal 等人(2025)[6],Wang 等人(2024)[364],Huang 等人(2025)[156],Boiko 等人(2023)[45],Ifargan 等人(2024)[160],Wang 等人(2025)[356] 发表了专注于基于 LLM 或智能体进行科学假设生成的研究,特别是在生物学和化学领域。然而,我们发现所有这些 AI 科学家智能体系统绝大多数都依赖于语言理解和生成能力。当涉及数据分析时,系统必须与外部专门工具交互。这是一个明显的缺点,即当前的主流 LLM 尚未在实验数据上进行预训练,因此无法在其知识范围内处理实验数据分析。这也导致了科学界的普遍反馈,即 LLM 产生的大多数想法并不深刻[314]。
领域特定的 LLM 在材料科学、生物学、CFD 中已经发表了自回归领域基础模型或微调模型。在材料科学和化学领域,Xia 等人(2025)[377] 和 Huang 等人(2023)[155] 尝试从零开始训练一个用于生物学和材料的基础语言模型。Tang 等人(2025)[339],Xie 等人(2025)[380],Gruver 等人(2024)[131],Rubungo 等人(2023)[301] 在基础 LLM 上微调材料和化学数据集,并在特定领域取得了比原始模型更好的性能。Bran 等人(2023)[47] 尝试在 GPT-4 之上构建智能体以在化学研究中使用工具。
生物学中的基础模型在规模上建模生物系统方面显示出卓越的能力。Brixi 等人(2025)[51] 介绍了 Evo 2,一个在 9.3 万亿个 DNA、RNA 和蛋白质序列上训练的生物学基础模型,能够预测功能遗传变异并以前所未有的分辨率和连贯性生成基因组尺度序列。类似地,Lin 等人(2023)[209] 证明,进化尺度的蛋白质语言模型可以使用 150 亿参数的架构(ESMFold)直接从一级序列推断完整的原子级结构,实现了规模化的高分辨率预测。最近,[40] 发表了 ProGen3,一个 460 亿参数的稀疏自回归模型,在超过 1.5 万亿个氨基酸 token 上训练,显著提高了跨不同家族生成可行蛋白质的能力,并与实验数据更好地对齐以改进适应度预测。然而,尽管它们表现出令人印象深刻的性能,但这些基础模型从根本上仍然基于自回归序列建模,并且严重依赖大规模生物序列或结构数据,如 DNA、RNA 和蛋白质序列或原子级结构。虽然这使得它们能够从大量生物数据集中学习统计模式和相关性,但也将它们的理解限制在训练数据中存在的内容——主要是序列到结构的关系——而没有明确整合控制分子相互作用、热力学、动力学或细胞环境的底层物理和化学原理。换句话说,当前生物学中的基础模型缺乏来自物理和化学的第一性原理知识(如能量最小化、静电相互作用、氢键或反应动力学)的整合,而这些对于更深入的生物过程机制理解是必不可少的。这限制了它们超越已知生物模式的泛化能力,并使它们容易过拟合或产生生物学上合理但物理上不现实的序列或结构。
世界模型 Azzolini 等人(2025)[20] 介绍了 Cosmos-Reason1,一个物理 AI 系统,它建立在涵盖空间、时间和基础物理学的物理常识层次化本体之上,通过多模态感知和长链思维过程实现对真实世界的接地推理。Yang 等人(2025)[388] 发布了 VSI-Bench,用于评估多模态大语言模型(MLLM)在视觉空间智能方面的表现。Assran 等人(2025)[19] 介绍了 V-JEPA 2,一个在大规模视频数据上训练的自监督模型,能够在无需任务特定监督的情况下实现物理世界理解、预测和规划。尽管有这些进展,但最近关于世界建模的工作仍然从根本上受限于它们对视觉和多模态感知的依赖。由于三个关键局限,它们未能构建对物理世界的全面理解。首先,这些模型缺乏定量测量整合,它们从定性观察(如视频、图像或自然语言描述)中学习,而没有纳入精确的数值数据(如温度、压力、速度或力),而这些对于准确的物理推理至关重要。第二,它们无法在没有定量基础的情况下学习物理定律,因为访问可测量的、结构化的物理量对于推断底层物理原理(如牛顿力学、热力学和电磁学)是必要的,这些原理本质上是数学的,需要数据驱动学习。第三,模拟“所见之物”并不等同于模拟现实,因为这些系统可以模仿视觉模式(如波浪运动或物体相互作用),但缺乏机制性理解,导致模拟的是表象而非其背后的因果动力学。例如,即使一个模型可以在视频模拟中生成逼真的波浪运动,它也不理解支配这种行为的流体动力学方程。为了构建能够准确泛化和预测真实世界现象的真正的世界模型,未来的系统必须超越被动观察,并整合定量物理数据、以语言和数值描述表示的第一性原理物理定律,以及对时间、空间、能量和物质的结构学习。
AI 智能体越来越多地利用强化学习来展示长程思维链(COT)能力,如 ChatGPT o1 和 DeepSeek R1 所示。Silver 和 Sutton(2025)[315] 认为,未来的 AI 进展在于基于经验的学习,从而在数学、编码和科学发现方面实现超人的表现。然而,在当前研究中,智能体的概念仍然定义不清。我们的发现表明,仅靠长程 COT 不足以解决数据驱动的科学问题,并且可能引入偏见,破坏结果的可靠性。对物质世界的真正理解必须植根于预训练期间的结构感知表示学习,特别是对于建模多尺度和多结构的物理或生物系统。因此,仅通过强化学习追求 AGI 可能是不够的,如果没有基于连贯的世界模型。正如 Richens 等人(2025)[297] 进一步表明的那样,能够执行多步骤、目标导向任务的通用智能体必须首先学习环境动态和约束的内部模型。
具身智能 通过端到端预训练的视觉-语言-动作(VLA)模型已被采用为机器人学的主流方法[303]。Brohan 等人(2023)[52],Team AgiBot-World 等人(2025)[343],以及 AI(2025)[7] 引入了通才视觉-语言-动作(VLA)模型——RT-2、GO-1 和 Helix——它们利用网络规模的数据和端到端学习,在真实世界环境中实现语义推理和高性能长程机器人控制。当前的 VLA 模型在网络规模的语言预训练之上构建世界模型,但它们常常无法学习环境的一致表示,正如 Vafa 等人(2024)[348] 的导航实验所证明的那样。为了构建一个能够准确映射多尺度现实(包括地球系统、国家、城市、工厂和家庭)的物质世界基础模型,对于具身智能的大规模应用至关重要,具身智能系统在其中运行。特别是,RT-2 将以数值 token 表示的机器人动作与互联网规模的视觉-语言数据集成,通过端到端学习实现涌现的语义推理和机器人控制中改进的泛化能力。我们的工作,BigBang-Proton,擅长大规模数值数据学习和物理结构建模,并且可以无缝地将动作控制学习与内部世界表示融合。这种整合显著增强了泛化能力,并使得在真实世界环境中能够进行更准确的规划和推理。
5 讨论与未来工作
在语言和专门科学多任务数据集上预训练的平滑收敛表明,LLM 的扩展可以超越语言,延伸到物理世界。BigBang-Proton 展示的模拟和生成多尺度物理结构的能力(主流推理 LLM 在其中遭遇了明显的失败)进一步表明,结构学习是人工通用智能(AGI)不可或缺的组成部分。
5.1 AGI 之路:结构学习 vs. 长程思维链


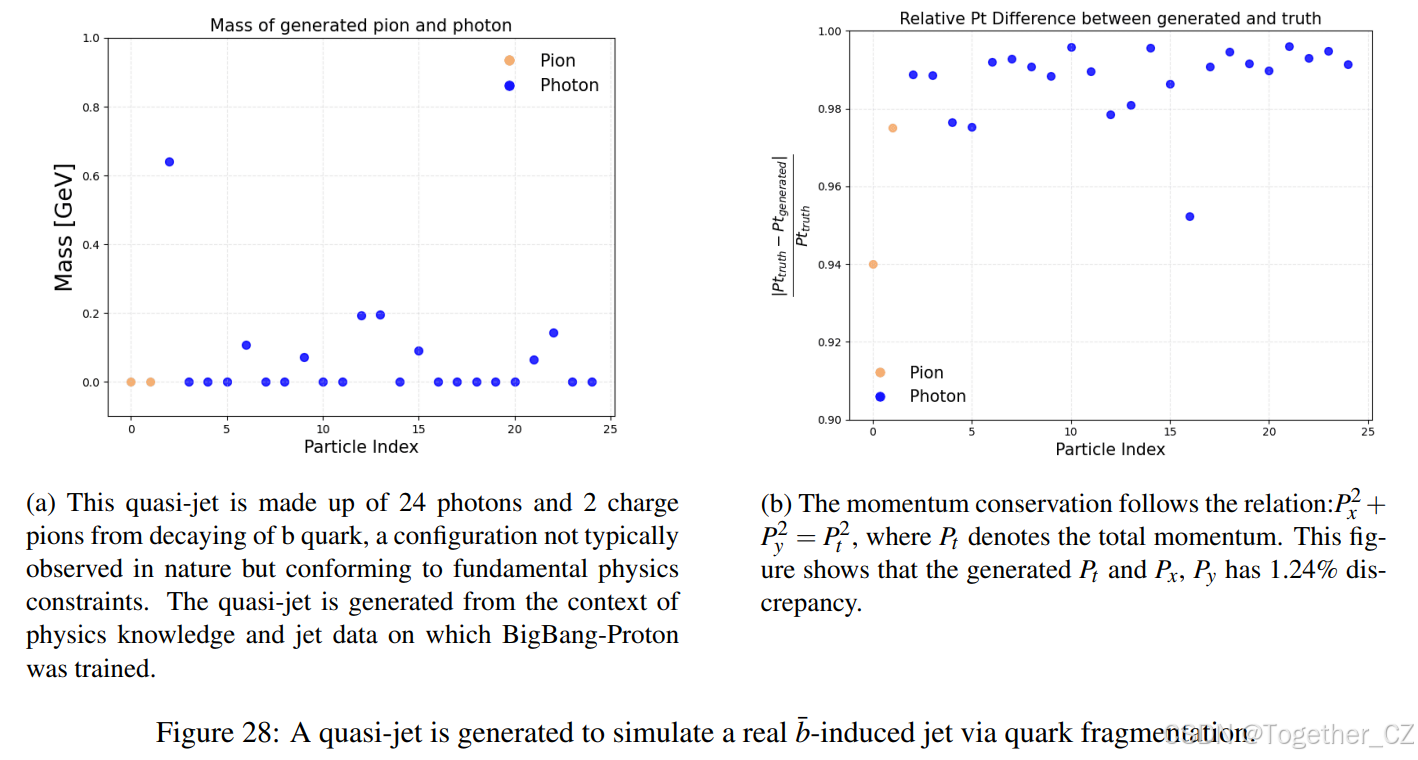

5.2 柏拉图式表示、数据空间流形与宇宙流形
Huh 等人(2024)[159] 认为,在不同深度网络和模态上训练的 AI 模型倾向于在其表示空间中收敛到一个共享的现实统计模型。他们假设这种收敛达到了一个理想化现实的表示,称为柏拉图式表示,这参考了柏拉图的洞穴寓言[279]。这项工作专注于研究视觉和语言表示中数据点之间的距离,发现这些模型试图收敛到生成观测数据的底层现实的表示。数据和模型的缩放,以及任务泛化,是这种收敛的关键驱动因素。在科学多任务学习和物质世界基础模型开发的背景下,这一假设得到了跨科学领域迁移学习以及基于尺度和结构的物质世界分层组织的支持[12]。物质世界,或者说宇宙本身,构成了理想化的现实,而物理学、化学和生物学中的所有科学定律都代表了从特定视角对这一现实的统计反映。物质世界是一个单一的、统一的实体,而人类理解它的努力由于资源限制而分散在各个学科中。宇宙起源于 137 亿年前的大爆炸[10, 193],并演化到现在的状态,产生了人类文明,人类语言由此出现并通过互联网记录下来。主流 LLM 在全部互联网数据上进行训练,只捕获了嵌入在物质世界中的一小部分信息。与普遍认为基础 LLM 预训练由于可用互联网数据耗尽而遭遇瓶颈的判断相反[142, 11, 161, 228],我们从 BigBang-Proton 的工作得出结论,预训练的极限最终是宇宙本身的极限。我们进一步假设,如假设 1 所见,给定足够的资源,对整个宇宙和人类文明历史上所有可收集的数据进行预训练,将允许单一模型收敛到一个植根于大爆炸以及支配宇宙起源的基本定律的表示,作为信息和物质的交汇点,因为我们今天居住的物质世界源于那个奇点。
自回归 LLM 的缩放定律尚未触及瓶颈。LLM 缩放的极限是宇宙的终极边界。LLM 的缩放最终将收敛到大爆炸时刻的基础物理定律以及信息与物质的交汇点。
现实的内在统计性质源于量子力学原理[92],起源于大爆炸期间的量子涨落[347, 135, 44, 197]。这些涨落驱动了跨宇宙和物质尺度的分层结构形成,例证了宏观现象从受量子力学和热力学支配的微观相互作用中涌现的原理。统计力学[270] 桥接了这些尺度,揭示了概率分布如何支撑物理系统中的相变,这一概念在语言系统中也有相似之处。语言作为一种信息传输媒介,其结构源于概率分布,这些分布通过空间、时间和能量维度的组合配置来投射现实。其宏观架构从巨大的排列组合中涌现出来,形成了一个受自由能最小化视角[111] 支配的复杂系统。语言在其进化轨迹上展现出具有相变和涌现属性的动态结构[226, 143]。LLM 在计算上近似这些经过数百万年提炼以编码时间、空间和能量关系的语言概率分布。这项研究、Wu 等人(2024)[375] 以及最近的其他尝试[377, 339] 表明,当映射到高维潜在空间时,这些分布与基本物理结构(如粒子碰撞、材料晶体格、DNA 序列和水的时间空间模式)紧密对齐。这种对齐实现了语言引导的科学计算,并推进了科学领域之间的迁移学习[345, 266]。Mirchandani 等人(2023)[238] 和 Lu 等人(2021)[222] 得出结论,LLM 可以作为高度不同的数据模态中的通用模式机器,以序列作为输入。表示空间中的语言-物理对齐进一步表明,语言继承了宇宙物理定律的对称性,将 LLM 定位为不仅仅是语言模式学习器,而且还是重建现实统一统计方面的工具。
传统计算机视觉和 NLP 中的迁移学习利用表示和参数转移[138, 104]。图 29b 展示了将所有科学领域知识投射到同一表示空间以显著增强领域间迁移学习的方案,该方法使用二进制块作为编码方法,在我们之前的工作 BigBangTransformer-Neutron[375] 中提出。图 29a 说明了不同的科学领域如何
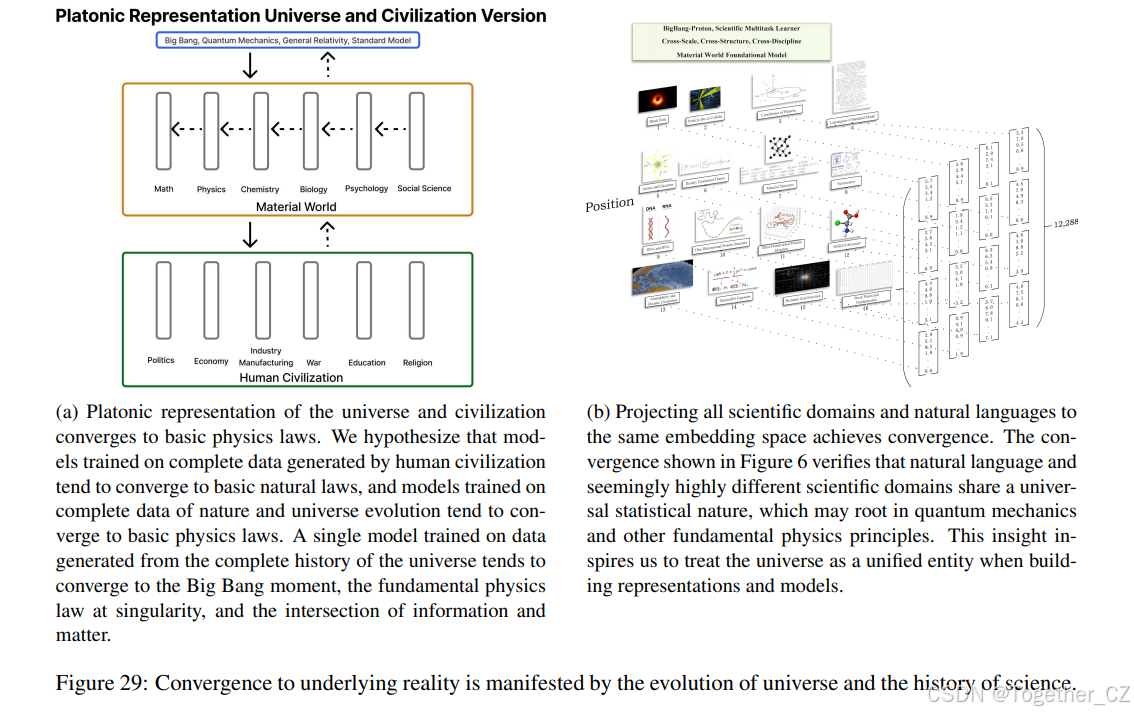
图 29: 趋近底层现实体现在宇宙的演化和科学史中。
沿着科学的单向层次结构收敛和转移知识,遵循“多则不同”原则[12]。模拟整个宇宙是实现跨学科、跨尺度和跨结构在超高维表示数据空间中进行彻底迁移学习的直接途径。
深度学习中的流形假说为对整个宇宙的数据进行预训练如何可能收敛到基础物理定律并实现跨领域表示迁移提供了进一步的见解。该假说认为,真实世界的数据当嵌入到高维环境空间 RDRD 时,会集中在一个低得多的维度的流形 MM 附近[35, 33, 62, 120, 83, 96, 144, 176],这一论断得到了理论研究[264, 246, 57, 182, 247, 253, 300, 319, 344, 371] 和实证研究[280, 63] 的支持。流形学习也在大型语言模型中得到了研究[239]。根据流形并集假说[54],跨任务、学科、空间尺度和物理结构的宇宙尺度预训练中感兴趣的低维结构形成流形,并收敛到一个不连通的流形并集。这种流形的收敛可能对应于基本的宇宙流形,并与全息原理[46, 153, 292, 227] 一致,该原理指出宇宙的完整物理描述可以从其边界表示中涌现出来。这一视角为理解香农引入的信息熵[311] 与物理学中的热力学熵[31, 331] 之间的关系提供了更深层次的理解。正如 Vopson(2025)[352] 提出的,引力是计算宇宙数据压缩的证据,对整个宇宙的实际预训练将揭示信息与物质交汇处的物理机制。
Hooft(2009)[153] 首次假设,在普朗克尺度下,3+1 维时空会简化为 2+1 维,这一想法受到了贝肯斯坦界限的启发,该界限推测黑洞熵的上限与其表面积而不是体积成比例[32]。这个“世界是全息图”的假设得到了反德西特空间和共形场论(AdS/CFT)对应关系[227] 的支持。维度约简是流形学习的根本追求[234],它可以驱动在宇宙尺度数据上预训练的模型学习普朗克尺度的时空结构,并发现量子引力层面隐藏的定律,这些定律仍然未被物理实验探测到。这种时空结构学习远远超出了当前主要基于图像学习的空间智能和世界模型范式[388, 20, 115]。


5.3 宇宙尺度压缩
假设性地,我们提出以下宇宙尺度压缩计划,搁置现实中的计算和数据挑战,以在一个二进制序列中重建物理世界。首先,建立一个跨越宇宙、星系、陆地到夸克尺度的统一时空框架,将每个自由度置于一致的时空结构中。其次,整合人类科学探究在各个尺度、结构和学科中产生的所有理论和实验数据,相当于整个可观测宇宙历史的总数据内容。最后,通过整合来自所有自然材料和人类制造物体及活动的数据,包括建筑物、城市、工厂、车辆、飞机以及经济、政治、战争等,从重子成分重建地球和人类文明。
这项研究为宇宙尺度数据的预训练提供了不可或缺的方法论。二进制块编码为自然界和人类活动中超复杂模态提供了简单、统一且有效的分词方法。理论与实验学习范式将由自然语言表示的理论知识与由数值数据表示的大规模实验数据融合。蒙特卡洛注意力提供了与宇宙中重子数量 10801080 相当的上下文长度。通过将宇宙视为一个单一的、连贯的实体,并在宇宙尺度数据上预训练一个单一的大型语言模型,我们可以推动科学发现的范式转变。这种方法将构建一个统一的、高维的表示空间,捕捉物理现实的全部复杂性,并使跨尺度、跨结构和跨学科的深度类比得以涌现。这样的框架将揭示结构同质性,例如从量子场到数和几何结构中重复出现的对偶性、对称性和相变,反映了数学、物理、化学和生物学中的深刻统一,如朗兰兹纲领[38, 119, 110]、波粒二象性、材料晶体和海洋流动中的拓扑[88]。出现在早期宇宙[152, 185, 374, 136]、超导体[23]、生物大脑[30, 71, 150, 189, 29] 和 LLM[370, 194] 中的相变和临界性暗示了一个共享的统计力学基础,允许模型识别普遍的组织原理,包括智能作为复杂系统中热力学和进化的必然性的涌现。智能是由宇宙演化产生的系统,反映了宇宙本身。如果不将智能置于宇宙演化的背景中,我们就无法理解智能的真正原因和潜在机制。数据是智能活动的产物。宇宙尺度压缩的趋同可以进一步揭示智能与现实之间的相关性。这重新定义了人类在宇宙中的角色,拒绝了霍金的“微不足道的化学浮渣”[90] 观点,反而推动智能朝着掌握知识、预测和控制跨尺度现实的超长期趋势发展[90, 91]。
我们未来的工作涉及在一个具有增强语言推理能力的单一 BigBang 模型中模拟更复杂的物理结构,如假设 2 所述,包括大爆炸核合成、核聚变、量子材料、虚拟细胞系统、地球系统、机器人技术、飞机。


虚拟细胞系统 我们应用多尺度和多学科的 LLM BigBang 来构建一个全面的虚拟细胞[257, 56],通过整合多组学实验数据(基因组、转录组、蛋白质组、代谢组、脂质组、糖组),包括各种分子修饰(磷酸化、糖基化等)[318, 171]。目标是从遗传密码到可观测表型模拟完整的细胞行为,涵盖细胞结构(细胞核、细胞器)、过程(信号传导、运输、分裂、死亡)和相互作用(细胞间通讯)[231, 125, 121, 229, 199, 179]。这个虚拟细胞模型将能够进行广泛的计算实验,涉及小分子、基因扰动、病原体和环境因素,以预测涌现属性,如适应、进化和疾病状态,以及模拟细胞分化(例如神经元、肌肉)。关键应用包括加速靶点验证、药物发现、机制研究(MOA)、合成生物学、通路设计和疾病建模。最终,目的是通过能量消耗阐明生命的基本原理,如复制、稳态和熵管理。
地球系统建模 从模拟湖泊水动力学开始,我们将多尺度、多结构和多学科的 LLM BigBang 扩展到模拟整个地球作为一个耦合的多物理系统:大气圈、水圈、冰冻圈、生物圈、地壳、地幔和地核[148]。这需要原子尺度到连续体尺度的矿物结构建模、海洋和大气流体动力学、生物地球化学循环和气候反馈[77, 151, 99]。

6 AI 风险与安全
像 BigBang-Proton 这样的模型模拟原子结构、分子相互作用、DNA 序列,并最终模拟地球系统和宇宙现象的基础能力,不再是理论上的,而是正在成为工程现实。BigBang-Proton 的风险首先出现在核武器、化学武器和生物武器领域。主流大语言模型已经触及这些领域,而 BigBang-Proton 对跨尺度物质结构和基本自然规律的精确模拟将放大这些风险。其次,其对时空、行星系统、地球系统和宇宙结构的建模造成了严重的军事技术风险。特别是,这种建模可以升级 C4ISR 和态势感知系统,实现自动感知和响应,可能超过人类的监督能力,并增加战略错误或失控的可能性。第三,跨学科、跨结构、跨尺度的物理智能与语言推理相结合,产生了一类新的基础模型。这些模型可以在比人类认知更高的抽象维度和智能体层面上运行,这显著提高了关于可控性和破坏潜力的担忧。
因此,我们呼吁采取行动,为物质世界的基础模型建立一个安全框架,评估和限制其能力,管理部署路径,强制执行工程安全控制,并要求持续验证和监控,以防止这些能力超出我们的治理能力。
7 结论
在本研究中,我们介绍了 BigBang-Proton,一个用于科学多任务学习的自回归大语言模型。BigBang-Proton 展示了用于将自然语言与来自不同领域的大规模实验数据集融合的理论与实验学习范式,能够处理不同科学领域中高度异构数据模态的二进制块编码方法,以及作为主流 Transformer 替代方案将上下文长度扩展到 10801080 水平的蒙特卡洛注意力。我们展示了 BigBang-Proton 在大数字算术运算方面远远领先于主流 LLM,证明它能够模拟 ALU 机制,这对于模型学习物理世界至关重要。在粒子物理、材料科学、地质任务和生物学中,BigBang-Proton 通过下一词预测方案都取得了与最先进的专用模型相当或更好的性能。我们进一步提出了在宇宙尺度数据上预训练单一模型的假设,以验证学习的收敛性将抵达基础物理定律。模型和数据可以在 https://github.com/supersymmetry-technologies/BigBang-Proton 和 https://huggingface.co/SuperSymmetryTechnologies/BigBang-Proton 查看。我们将多任务测试数据集 UniverseBench 开源在 https://huggingface.co/datasets/SuperSymmetryTechnologies/UniverseBench。



















 2601
2601

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











