



这篇论文提出并详细阐述了一种名为 EchoMimicV2 的新型人工智能方法,其核心目标是利用简化的控制条件,生成高质量、富有表现力的半身人像动画。
以下是其研究内容的核心概括:
1. 研究动机(要解决什么问题?)
现有的人像动画方法存在两大主要局限:
-
区域限制:大多只专注于驱动头部(说话头)动画,忽略了肩部以下身体(尤其是手势)与音频的同步。
-
条件复杂:为了生成逼真动画,通常需要引入多种控制条件(如音频、全身姿态、运动图等)和复杂的注入模块,导致训练不稳定、推理速度慢,且实用性差。
核心研究问题:能否在简化控制条件(减少对复杂姿态图的依赖)的同时,实现惊艳的、涵盖半身(头部+手部)的音频驱动动画?
2. 核心解决方案(EchoMimicV2框架)
为了解决上述问题,论文提出了一个端到端的框架,主要包括三个创新点:
a) 音频-姿态动态协调策略
-
核心思想:像“华尔兹舞步”一样,动态协调音频和姿态两种条件的作用范围。
-
姿态采样:在训练中逐步减少姿态条件的作用范围(从全身→去掉嘴唇→去掉头部→仅保留手部),降低对完整姿态图的依赖,简化条件。
-
音频扩散:随着姿态条件的后撤,逐步扩大音频条件的作用范围(从仅控制嘴唇→控制整个面部→关联全身),让音频不仅能驱动口型,还能影响面部表情和身体韵律。
-
最终效果:推理时,只需音频和手部姿态序列(而非复杂的全身姿态图)即可驱动半身动画,实现了条件的极大简化。
b) 头部局部注意力数据增强
-
问题:高质量的半身说话视频数据稀缺。
-
解决:在训练音频控制面部的阶段,利用 “头部局部注意力” 机制,将丰富的头部特写数据(通过填充处理)无缝引入训练中,专门用于增强模型的面部表情生成能力,而无需增加额外的网络模块。这是一种高效的“免费午餐”式数据增强。
c) 阶段特异性去噪损失
-
问题:在简化姿态条件后,如何保证生成视频的运动准确性、细节清晰度和画面质量?
-
解决:将扩散模型去噪过程分为三个阶段,并为每个阶段设计针对性的辅助损失函数:
-
早期(姿态主导):使用姿态损失,确保人体轮廓和主要运动正确。
-
中期(细节主导):使用基于边缘的细节损失,优化人物特定细节。
-
后期(质量主导):使用图像质量损失,提升色彩、纹理等低层视觉质量。
-
-
优势:替代了原本需要完整姿态图来指导的复杂多任务学习,训练更高效、稳定。
3. 主要贡献总结
-
提出新框架:EchoMimicV2,首个旨在用简化条件(音频+手部姿态)实现高质量半身动画的端到端方法。
-
提出新策略:APDH策略,创新性地通过动态协调来简化和增强音频与姿态条件。
-
提出新技巧:HPA数据增强法,低成本利用头部数据提升半身动画的面部表现。
-
提出新损失函数:PhD损失,分阶段优化去噪过程,保障简化条件后的生成质量。
-
建立新基准:发布了首个针对音频驱动半身人像动画的评估数据集EMTD,便于未来研究比较。
-
验证有效性:通过大量实验证明,该方法在定性和定量指标上均超越了现有的最先进方法,特别是在手部生成质量和身份一致性方面表现突出。
这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

官方项目主页地址在这里,如下所示:

项目地址在这里,如下所示:
模型发布地址在这里,如下所示:
摘要
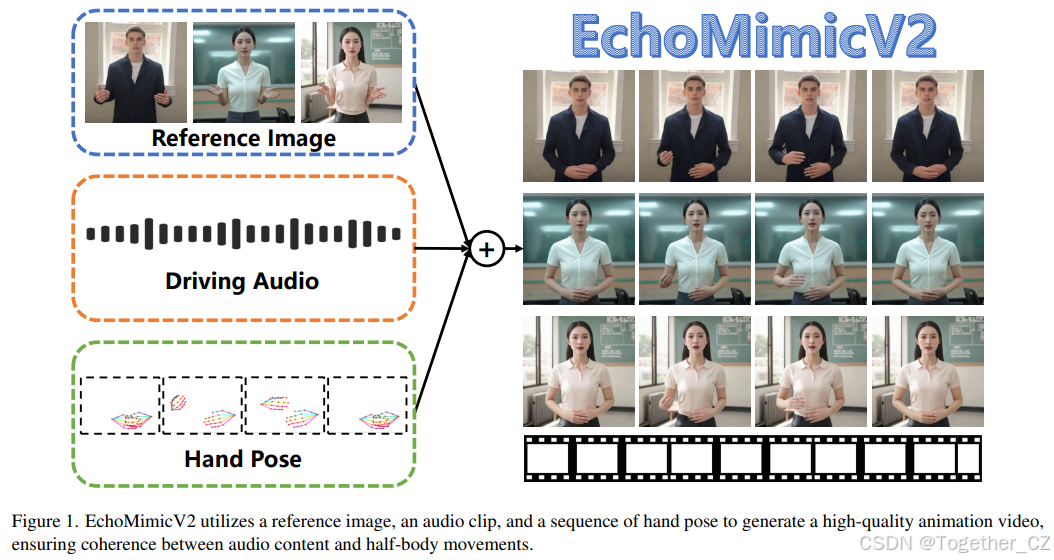
近期关于人像动画的研究通常涉及音频、姿态或运动图等条件,从而实现了生动的动画质量。然而,这些方法往往由于额外的控制条件、繁琐的条件注入模块或仅限于头部区域驱动而面临实际挑战。因此,我们提出疑问:是否可以在简化不必要条件的同时,实现惊艳的半身人像动画?为此,我们提出了一种半身人像动画方法,命名为 EchoMimicV2。该方法利用一种新颖的 音频-姿态动态协调 策略,包括 姿态采样 和 音频扩散,以增强半身细节、面部表情和手势表现力,同时减少条件冗余。为弥补半身数据的稀缺性,我们利用 头部局部注意力 无缝地将头部特写数据纳入我们的训练框架,该模块在推理阶段可以省略,为动画提供“免费午餐”。此外,我们设计了 阶段特异性去噪损失 以分别在特定阶段指导动画的运动、细节和低层次质量。另外,我们还提出了一个新的基准,用于评估半身人像动画的有效性。大量的实验和分析表明,EchoMimicV2 在定量和定性评估中均超越了现有方法。
1. 引言
基于扩散的视频生成技术已取得显著进展[1, 3, 5, 8, 9, 11, 12, 21, 33],推动了人像动画领域的广泛研究。人像动画,作为视频生成领域的一个子集,旨在从参考角色图像中合成自然且真实的以人为中心的视频序列。
当前人像动画的研究通常采用预训练的扩散模型作为主干,并涉及相应的条件注入模块来引入控制条件[6, 14, 17, 26, 30, 31, 37, 38],从而能够生成逼真的动画。然而,学术研究与工业需求之间仍存在差距:1) 头部区域限制;2) 条件注入复杂性。1) 头部区域限制。一方面,先前的人像动画工作[6, 30, 31, 37] 主要专注于生成头部区域视频,忽略了音频与肩部以下身体的同步。最近的工作[17]通过引入音频驱动模块之外的辅助条件和注入模块,改进了半身动画。2) 条件注入复杂性。另一方面,常用的控制条件(例如文本、音频、姿态、光流、运动图)可以为逼真动画提供坚实的基础。然而,当前研究工作集中于聚合补充条件,这导致了因多条件不协调而产生的不稳定训练,以及因复杂条件注入模块而增加的推理延迟。
对于第一个挑战,存在一个简单的基线方法,即累积与肩部以下身体相关的条件,例如半身关键点图。然而,我们发现这种方法仍然不可行,因为它增加了条件的复杂性(对应第二个挑战)。
在本文中,为弥补上述问题,我们在人像动画方法EchoMimic [6]的基础上,提出了一种新颖的端到端方法——EchoMimicV2。我们提出的EchoMimicV2力求在简化条件的同时,达到惊艳的半身动画质量。
为此,EchoMimicV2利用音频-姿态动态协调训练策略来调节音频和姿态条件,同时减少姿态条件的冗余。此外,它利用一个稳定的训练目标函数,称为阶段特异性损失,来增强运动、细节和低层次质量,从而替代冗余条件的指导。
具体而言,APDH 的灵感来源于华尔兹舞步,其中音频和姿态条件如同同步的舞伴。当姿态优雅地后退一步时,音频无缝地前进一步,完美填补空间,创造出和谐的旋律。因此,通过音频扩散,音频条件的控制范围从嘴巴扩展到全身;同时,通过姿态采样,姿态条件的控制范围从全身缩小到手部。鉴于负责音频表达的主要区域位于嘴唇,我们从嘴唇部分开始进行音频条件扩散。此外,由于手势交流和言语交流的互补性,我们保留了手部姿态条件以支持手势动画,从而克服了头部区域限制的挑战,扩展到半身区域动画。
在这个过程中,我们找到了一种数据增强的“免费午餐”。当音频条件仅通过头部局部注意力控制头部区域时,我们可以无缝地整合填充后的头部特写数据来增强面部表情,而无需像[17]那样需要额外的插件。我们在表1中列出了我们提出的EchoMimicV2的优势。
此外,我们提出了一个稳定的训练目标函数——阶段特异性损失,其目标有二:1)利用不完整的姿态增强运动表示;2)改善不受音频控制的细节和低层次视觉质量。虽然直观的方法是采用一个集成了姿态、细节和低层次视觉目标函数的多损失机制,但这种方法通常需要额外的模型,包括姿态编码器和VAE解码器。鉴于基于ReferenceNet的主干已经需要大量的计算资源[14],实现多损失训练变得不切实际。通过实验分析,我们将去噪过程划分为三个不同的阶段,每个阶段有其主要关注点:1) 姿态主导阶段,最初学习运动姿态和人体轮廓;2) 细节主导阶段,细化角色特异性细节;3) 质量主导阶段,模型增强颜色和其他低层次视觉质量。因此,提出的PhD损失是针对每个特定的去噪阶段量身定制以优化模型的,即早期阶段使用姿态主导损失,中期阶段使用细节主导损失,最终阶段使用低层次损失,确保更高效和稳定的训练过程。
另外,为了便于社区对半身人像动画进行定量评估,我们整理了一个测试基准,命名为EMTD,包含从互联网收集的半身人像视频。我们进行了广泛的定性和定量实验及分析,证明了我们的方法达到了最先进的水平。总之,我们的贡献如下:
-
我们提出了EchoMimicV2,一个端到端的音频驱动框架,能够在简化条件下生成惊艳的半身人像动画;
-
我们提出了APDH策略,精心调节音频和姿态条件,并减少姿态条件冗余;
-
我们提出了HPA,一种无缝的数据增强方法,用于增强半身动画中的面部表情,无需额外模块;
-
我们提出了PhD损失,一种新颖的目标函数,用于增强运动表示、外观细节和低层次视觉质量,替代了完整姿态条件的指导;
-
我们为半身人像动画提供了一个新的评估基准。
-
进行了大量实验和分析,以验证我们提出框架的有效性,该框架超越了其他最先进的方法。
表1:我们提出的EchoMimicV2的简化性。
| EchoMimicV2 | CyberHost[17] |
|---|---|
| 音频+参考图像 | 音频+参考图像 |
| + 手部姿态序列 | + 身体运动序列 |
| - | + 面部裁剪注入模块 |
| - | + 手部裁剪注入模块 |
| - | + 全身姿态指导 |
2. 相关工作
2.1 姿态驱动的人像动画
许多人像动画方法专注于姿态驱动设置,使用驱动视频中的姿态序列。姿态驱动的人像视频生成研究通常遵循标准流程,采用各种姿态类型,如骨骼姿态、密集姿态、深度、网格和光流等作为引导模态,以及文本和语音输入。条件生成模型以稳定扩散或稳定视频扩散作为其主干,取得了进展。像MagicPose[4]这样的方法通过ControlNet[36]将姿态特征集成到扩散模型中,而像AnimateAnyone[14]、MimicMotion[38]、MotionFollower[24]和UniAnimate[27]这样的方法则使用DWPose[35]或OpenPose[20]提取骨骼姿态。这些方法使用具有少量卷积层的轻量级神经网络作为姿态引导,在去噪过程中将骨骼姿态与潜空间噪声对齐。相比之下,DreamPose[15]和MagicAnimate[32]使用DensePose[10]提取密集姿态信息,然后与噪声拼接,并通过ControlNet[36]输入到去噪UNet中。Human4DiT[22]受Sora启发,使用SMPL[2]提取3D网格图,并采用扩散变换器进行视频生成。
2.2 音频驱动的人像动画
音频驱动人像动画的目标是从语音音频中生成手势,确保运动在语义、情感和节奏上与音频保持一致。现有工作通常聚焦于说话头部。EMO[23]引入了帧编码模块以确保一致性。AniPortrait[30]将先进的3D面部结构映射到2D姿态以获得连贯的序列。V-Express同步音频与嘴唇运动和表情,细化情感细微差别。Hallo[31]使用扩散模型增强对表情和姿态的控制。Vlogger[39]通过扩散模型从单张图像生成说话视频,实现高质量、可控的输出。MegActor-Σ[34]将音频和视觉信号集成到人像动画中,采用条件扩散变换器。TANGO[18]生成伴随语音的身体手势视频,改善对齐并减少伪影。此外,EchoMimic[6]不仅能够单独通过音频和面部姿态生成人像视频,还能通过音频和选定面部姿态的组合来生成。CyberHost[17]支持来自多种模态的联合控制信号,包括音频、全身关键点图、2D手部姿态序列和身体运动图。
3. 方法
3.1 预备知识

3.2 音频-姿态动态协调
在本节中,我们介绍EchoMimicV2的核心训练策略——音频-姿态动态协调。APDH用于逐步降低条件复杂性,并以类似华尔兹舞步的方式调节音频和姿态条件。该策略包含两个主要组成部分:姿态采样和音频扩散。
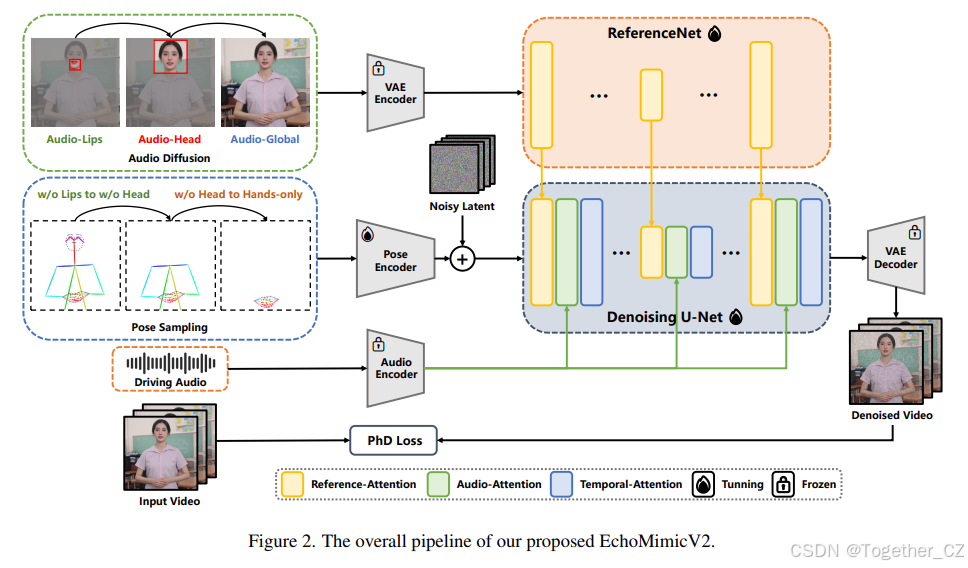
3.2.1 姿态采样

3.2.2 音频扩散
在初始姿态和交互级别姿态采样阶段,音频交叉注意力块被完全冻结。在空间级别姿态采样阶段,音频条件开始逐步整合。

3.3 用于数据增强的头部局部注意力
在音频-面部同步阶段,我们引入头部特写数据来弥补半身数据的稀缺性并增强面部表情。为此,我们对头部特写数据进行填充,以严格对齐半身图像的空间维度和头部位置(如图2所示)。然后,我们重用头部局部注意力来排除填充部分,如图2所示。值得注意的是,不需要额外的交叉注意力块。为了减轻填充对源数据分布的影响,我们在音频-面部同步阶段引入半身数据之前,先进行此步骤。

3.4 时间模块优化
遵循EchoMimic[6],我们将时间交叉注意力块集成到去噪U-Net中,并使用EchoMimic初始化其权重。在优化时间模块时,我们使用24帧视频剪辑作为输入,并冻结其他模块以确保稳定性。
3.5 阶段特异性去噪损失

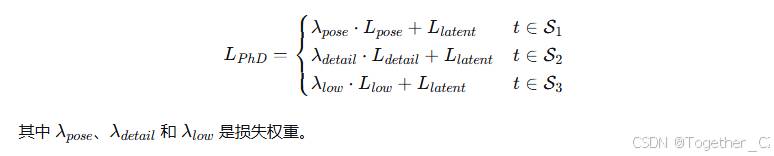
4. 实验
在本节中,我们首先提供实验中的实现细节、训练数据集、评估基准。随后,通过与可比方法的定量和定性比较,评估我们方法的优越性能。接下来,我们还进行了消融研究,以分析我们方法各组成部分的有效性。

4.1 实验设置

训练数据集。 我们的训练数据集包括三部分:完全姿态驱动数据集、半身数据集和头部特写数据集。我们使用HumanVid[29]作为完全姿态驱动数据集,其中包含约20,000个带2D姿态标注的高质量以人为中心的视频。半身训练数据集从互联网视频中整理,专注于半身说话场景。该数据集时长160小时,包含超过10,000个不同身份。头部特写数据集源自EchoMimic使用的训练数据集,包含540小时的说话头部视频。
新颖的半身评估基准。 公开数据集通常评估音频驱动的说话头部或姿态驱动的人像动画,但没有专门针对音频驱动半身动画的数据集。为填补这一空白,我们引入了EchoMimicV2测试数据集用于评估半身人像动画。EMTD包含来自YouTube的65个高清TED视频(1080P),包含110个标注清晰、正面朝前的半身演讲片段。开源项目将提供用于下载、切片和处理这些视频以进行评估的脚本。由于授权有限,我们仅提供定性结果,不会展示可视化结果。我们还发布了由FLUX.1-dev生成的用于参考图像的角色。这些资源支持对比实验,并促进进一步的研究和应用。
评估指标。 半身人像动画方法使用FID、FVD[25]、PSNR[13]、SSIM[28]、E-FID[7]等指标进行评估。FID、FVD、SSIM和PSNR是评估低层次视觉质量的指标。E-FID使用Inception网络特征评估图像真实性,通过人脸重建方法提取表情参数并计算其FID分数来衡量表情差异。为评估身份一致性,我们计算参考图像的面部特征与生成视频帧之间的余弦相似度。此外,我们还使用SyncNet[19]计算Sync-C和Sync-D,以验证音频-嘴唇同步准确性。另外,为评估手部动画,采用手部关键点置信度平均值来评估音频驱动场景下的手部质量,并计算手部关键点方差以指示手部运动的丰富度。
4.2 定性结果
为了评估我们提出的EchoMimicV2的定性结果,我们使用FLUX.1-dev生成参考图像,然后基于这些参考图像进行半身动画。我们的方法使用音频信号、参考图像和手部姿态序列生成高分辨率半身人像视频。图3展示了我们方法在合成广泛的视听输出时,对伴随音频实现无缝同步的适应性和鲁棒性。这些结果证实了其在推进音频驱动半身人像视频生成最新技术方面的潜力,并表明我们提出的EchoMimicV2能够很好地泛化到不同角色和复杂手势。
与姿态驱动全身方法的比较。 我们对EchoMimicV2进行了定性评估,并与最先进的姿态驱动方法进行了比较,包括AnimateAnyone[14]和MimicMotion[38],如图5所示。我们可以看到,我们提出的EchoMimicV2在结构完整性和身份一致性方面优于当前最先进的结果,特别是在手部和面部等局部区域。更多视频比较结果可在补充材料中找到。
与音频驱动全身方法的比较。 只有少数工作,如Vlogger[39]和CyberHost[17],支持音频驱动的半身人像动画。遗憾的是,这些方法尚未开源,给直接比较带来了挑战。我们从这两个项目的主页获取了相关实验结果,并使用相同的参考图像进行了实验。如图4所示,我们提出的EchoMimicV2在生成图像质量和运动自然度方面均超越了Vlogger和CyberHost。
4.3 定量结果
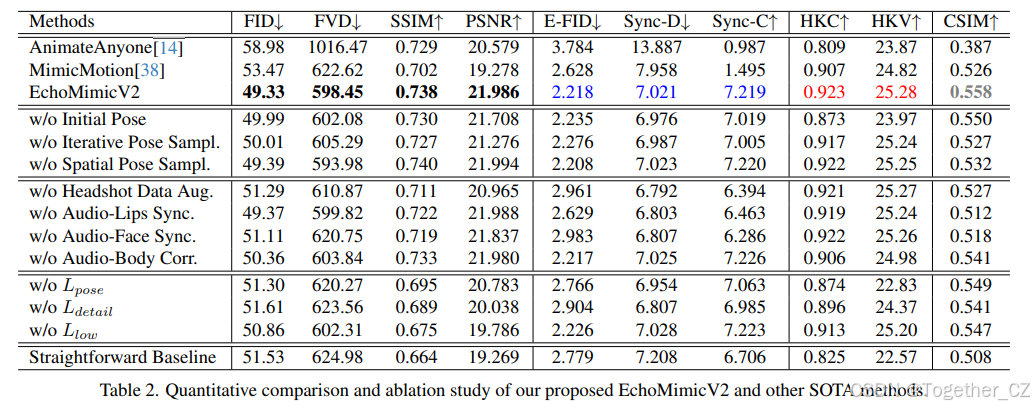
如表2所示,我们将EchoMimicV2与最先进的人像动画方法(包括AnimateAnyone[14]和MimicMotion[38])进行了定量比较。结果表明,EchoMimicV2显著提高了整体性能。具体而言,EchoMimicV2在质量指标(FID、FVD、SSIM和PSNR)上显示出显著提升,在同步指标(Sync-C和Sync-D)上取得了具有竞争力的结果。此外,EchoMimicV2在一致性指标(CSIM)上超越了其他SOTA方法。值得注意的是,EchoMimicV2在手部相关质量指标(HKV、HKC)上达到了新的SOTA水平。
4.4 消融研究
我们在表2中分析了我们的音频-姿态动态协调策略、条件简化设计和PhD损失的有效性。
姿态采样分析。 我们进行了消融研究,以验证姿态采样每个阶段的有效性。具体而言,我们可以观察到,初始姿态和迭代姿态采样阶段有助于整体性能的提升,这是因为完整身体姿态条件提供了强大的运动先验。另一方面,表2第7行显示,完整的姿态条件(无空间姿态采样)对各指标的影响有限,表明了全身姿态的冗余性,并且我们的APDH策略即使在仅使用手部姿态条件的情况下也能实现稳定的动画。
音频扩散分析。 如表2所示,第9和10行表明音频扩散增强了嘴唇运动和面部表现力。此外,第10行显示音频条件也改善了身体和手部动画,表明EchoMimicV2捕捉到了细粒度的关联,即与音频相关的呼吸节奏和与音频相关的手势。
头部特写数据增强分析。 表2第8行显示,头部特写数据增强对同步指标(Sync-D、Sync-C)有显著影响。
PhD损失分析。 我们还验证了PhD损失中每个组件对EchoMimicV2的影响。如表2第12至14行所示,我们观察到 LposeLpose 对整体指标有显著影响,因为它补偿了姿态条件的不完整性。此外,LdetailLdetail 显著提升了局部质量指标的性能,如Sync-C、Sync-D、E-FID、HKC和HKV。另外,LlowLlow 有助于质量指标(SSIM、PSNR)的性能提升。
简单基线分析。 我们还进行了消融研究,以验证整体APDH训练策略和PhD损失的有效性。我们训练了一个基线模型,该模型主干仅使用半身音频和手部姿态条件,没有采用渐进的APDH策略和PhD损失。如表2最后一行所示,由于两种条件之间的过渡不充分,这个基线模型取得了次优的结果。这些结果表明,APDH和PhD损失对于在简化条件下进行稳定训练非常重要。
手部姿态条件分析。 当前的图像和视频生成方法在生成详细的手部区域方面面临固有挑战。如图6所示,即使是最先进的文生图方法(例如FLUX.1)也在手部合成上存在困难,这个问题在音频驱动生成中被放大,因为音频信号与运动之间的相关性较弱。为解决此问题,EchoMimicV2结合了手部姿态和音频条件,尽管手部像素在半身图像中占比较低,但仍展现出强大的手部修复能力。值得注意的是,即使在参考图像中手部缺失,EchoMimicV2也能生成高保真的手部,如图6所示。通过移除所有姿态条件并保持其他设置,我们得到了一个完全音频驱动的动画模型,该模型能捕捉一般手势,将手部节奏与音频音调关联起来。然而,该模型无法生成特定的手势,如握拳或敬礼。由于篇幅限制,视频结果在补充材料中提供。

5. 局限性
本文在音频驱动的半身人像动画方面取得了显著进展,但承认现有局限性和有待改进的领域也很重要。(1) 音频到手部姿态生成:所提出的方法需要预定义的手部姿态序列,依赖人工输入来获得高质量动画,这限制了实际应用。未来的工作将探索在端到端范式中直接从音频生成手部姿态序列。(2) 非裁剪参考图像的动画:虽然EchoMimicV2在裁剪后的半身图像上表现稳健,但其在非裁剪图像(例如全身图像)上的性能有所下降。
6. 结论
在这项工作中,我们提出了一个有效的EchoMimicV2框架,用于在简化条件下生成惊艳的半身人像动画。通过我们提出的APDH训练策略和特定时间步的PhD损失,我们实现了音频-姿态条件协作和姿态条件简化,同时通过HPA无缝增强了面部表现力。全面的实验证明,EchoMimicV2在定量和定性结果上都超过了当前最先进的技术。此外,我们引入了一个新的基准来评估半身人像动画。为了促进社区发展,我们将我们的源代码和测试数据集开源供使用。



















 1025
1025

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











