




 本文探讨了推荐系统中的冷启动问题,包括用户、物品及系统层面的挑战,并提出多种应对策略,如利用用户注册信息、热门物品推荐、内容相似性计算及专家知识整合。
本文探讨了推荐系统中的冷启动问题,包括用户、物品及系统层面的挑战,并提出多种应对策略,如利用用户注册信息、热门物品推荐、内容相似性计算及专家知识整合。
第三章 推荐系统冷启动问题
3.1 推荐系统冷启动问题
推荐系统需要根据用户的历史行为和兴趣预测用户未来的行为和兴直,因此需要大量的用户行为数据,对于已经积累了大量的用户数据的公司来说,这或许根本不是问题,但对于没有用户数据的公司来说,如何做到个性化推荐并且让用户对推荐结果满意呢?
-
冷启动问题简介
冷启动问题主要分为3类:用户冷启动:当新用户到来时,我们没有他的行为数据,所以无法根据他的历史行为预测其兴趣,从而无法借此给他做个性化推荐。
物品冷启动:物品冷启动主要解决如何将新的物品推荐给可能对他感兴趣的用户的问题。
系统冷启动:系统冷启动主要解决如何在一个新开发的网站(还没有用户,也没有用户行为数据,只有一些物品信息)设计个性化推荐系统,从而在网站刚发布的时候就让用户体验到个性化推荐服务这一问题。 -
对于这3种不同的冷启动问题,有不同的解决方案,一般来说,可以参考如下解决方案:
提供非个性化的推荐:如先进行热门推荐,等用户有行为数据时,我们再个性化推荐。
利用用户注册时提供的信息,如年龄、性别等数据,可以做粗粒度的个性化。
利用用户的社交网络账号登录,导入用户的社交网站上的好友信息,然后推荐该好友喜欢的物品。
要求用户在登录时对一些物品进行反馈,收集用户以这些物品的兴趣信息。
对于新加入的物品,可以利用内容信息,将它们推荐给喜欢过和它们类似的物品的的用户。
在系统冷启动时,可以引入专家的知识,通过一定的高效方式迅速建立起物品的相关度表。
3.2 利用用户注册信息
利用用户的注册信息,可以较好的解决用户冷启动问题。
-
用户的注册信息分为3种:
1. 人口统计学信息,包括用户的年龄、性别、职业、民族、学历和居住地。 2. 用户的兴趣的描述,有一些网站会让用户用文字描述他们的兴趣。 3. 从其他网站导入的用户站外行为数据,比如用户通过新浪微博、腾讯的账号登录,就可以在用户同意的情况下获取用户的行为数据和社交网络数据。 -
基于注册信息的个性化推荐流程基本如下:
- 获取用户的注册信息;
- 根据用户的注册信息对用户分类;
- 给用户推荐他所属分类中用户喜欢的物品。
3.3 选择合适的物品启动用户的兴趣
在新用户第一次访问推荐系统时,我们先不立即向其推荐物品,而是提供一些物品,让用户反馈他们对这些物品的兴趣,然后根据用户的反馈提供个性化推荐。选择合适的物品启动用户的兴趣,可以较好的解决系统冷启动问题。
-
一般来说,能够用来启动用户兴趣的物品需要具有以下特点:
1. 比较热门,如果想让用户对一个物品进行反馈,前提是用户知道这个物品是什么东西。 2. 具有代表性和区分性。 3. 启动物品集合需要多样性。因为用户的兴趣可能是多样的。
基于用户注册信息的推荐算法核心问题是计算每种特征的用户喜欢的物品
故定义物品i在具有f的特征的用户中的热门程度:p(f,i)=|N(i)交U(f)|/(N(i)),(ps.除以N(i)是为了避免热门商品有较高的权重)可以理解为喜欢i的用户中具有特征f的比例,为了解决数据稀疏问题(如一个物品只被一个用户喜欢过,而这个用户刚好有特征f,那么p(f,i)=1,这种情况没有统计意义,所以分母有加上一个比较大的数,避免这样的物品产生较大的权重)最终形式为: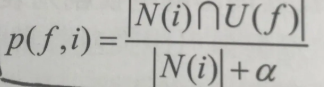
3.4 利用物品的内容信息
利用物品的内容信息,可以在某种程度上解决物品的冷启动问题。
-
向量空间模型
当物品内容比较丰富时,物品的内容可以使用向量空间模型表示,该模型会将物品表示成一个关键词向量。向量空间模型的优点是简单,缺点是丢失了一些信息,比较关键词之间的关系信息。
物品的相似性计算:
- 使用空间向量模型将物品的文字表述或者是关键字转化为空间向量(中文需要经历分词、关键字抽取、重要性排序TF-IDF、关键字向量),空间向量的每个分量都是权值,表示关键字对应的权重。可以使用TF-IDF计算词的权重,避免热门关键词对向量构建的影响。
- 使用余弦相似计算来物品对应的向量两两之间的相似性。考虑到计算的时间复杂度,可以先创建关键字-物品倒排表(和UserCF的原理类似)
- 利用之前的ItemCF的方式,将新物品推荐给用户。
-
话题模型
向量空间模型在内容数据丰富时可以获得比较好的效果。但是,如果关键词很少,向量空间模型就很难计算出准确的相似度,在这种情况下可以考虑使用话题模型。
代表性的话题模型有LDA,LDA作为一种生成模型,对一篇文档产生的过程进行建模。话题模型的基本思想是,一个人在写一篇文档的时候,会首先想这篇文章要讨论哪些话题,然后思考这些话题用什么词描述,从而最终用词写成一篇文章。
如何建立文章、话题和关键词的联系是话题模型研究的重点
在使用LDA计算物品的内容相似度时,我们可以先计算出物品在话题上的分布,然后利用两个物品的话题分布计算物品的相似度。计算分布的相似度可以利用KL散度:
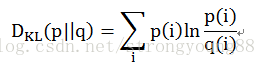
其中,p和q是两个分布,KL散度越大说明分布的相似度越低。
3.5 发挥专家的作用
在很多系统刚建立的时候,既没有用户的行为数据,也没有充足的物品内容信息来计算准确的物品相似度,这个时候,如果想让这个推荐系统在建立的时候就能让用户获得比较好的体验时,可以考虑利用专家进行标注。
行为数据,也没有充足的物品内容信息来计算准确的物品相似度,这个时候,如果想让这个推荐系统在建立的时候就能让用户获得比较好的体验时,可以考虑利用专家进行标注。

















 646
646

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









