




前言
本人是一名材料行业转行的三流程序员,在学习机器学习过程中遇到了很多问题,很多比较简单的博客都是看了很久才能弄懂,为了加深自己的理解,于是就把自己学习之后的一些理解记了下来。本文主要参考了文刀煮月的这篇博客https://www.cnblogs.com/liuqing910/p/9121736.html,把自己当时看的时候不太容易理解的地方加以了自己的说明,希望能够方便想要学习决策树的跟我一样的小白们,如有误,欢迎指出。
什么是决策树?
顾名思义,就是构建一棵能够帮助我们做出决策的树形结构
什么是树形结构?
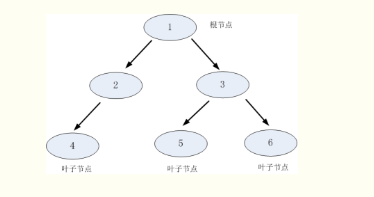
如上图所示,树形结构包含:根节点,父节点,子节点和叶子节点。根节点没有父节点,也就是初始的节点。父节点和子节点是一组相对概念,以图中为例,1是根节点同时又是2,3的父节点,2,3是1的子节点,同时2又是4的父节点,3是5,6的父节点,4是2的子节点,5,6是3的子节点,如果该节点不再向下进行延伸,那么这个节点就是叶子节点,图中的4,5,6就是叶子节点。
怎么通过树形结构来做出决策判断呢?
步骤1:将所有地数据视为一个节点(根节点),进入步骤2
步骤2:根据划分准则从该节点中选择出一个属性也就是一个特征,来对该节点进行划分,生产多个子节点,选择的划分属性中每一类值对应一个节点,(例如选择性别作为划分属性,性别分男女,那么就产生男,女两个子节点)进入步骤3
步骤3:对步骤2生成的n个子节点逐一进行判断,如果子节点满足停止分裂的条件,那么从根节点-子节点这条路线就进入步骤4,否则,回到步骤2
步骤4:设置该节点为叶子节点,它的输出就是该节点中数量占比最大的类别
停止分裂的条件是什么呢?
1.当前节点包含的样本全属于同一类别,无需划分
2.当前属性集为空,或是所有样本在所有属性上取值相同,无法划分
3.当前结点包含的样本集合为空,不能划分
有哪些划分准则呢?(重点)
一般而言,随着划分过程不断进行,我们希望决策树的分支节点所包含的样本尽可能属于同一类别,即节点的"纯度"越来越高。
A.信息增益
要了解信息增益,首先需要了解信息熵的概念
信息熵:假设样本集合D中第k类样本所占的比例为 ρ k ( k = 1 , 2... ∣ y ∣ ) ρ_{k}^{(k=1,2...|y|)} ρk(k=1,2...∣y∣),则样本D的信息熵为:
E n t ( D ) = − ∑ k = 1 ∣ y ∣ ρ k l o g ρ k Ent(D)=-\sum_{k=1}^{|y|}ρ_{k}logρ_{k} Ent(D)=−k=1∑∣y∣ρklogρk
Ent(D)越小,则样本D的纯度越高
举个简单的例子,样本集合D表示一个班的学生手机品牌统计数据,其中有6个iphone,10个华为,4个小米,有三类手机品牌那么y=3, ρ i p h o n e = 6 20 = 0.3 ρ_{iphone}=\frac{6}{20}=0.3 ρiphone=206=0.3, ρ 华 为 = 10 20 = 0.5 ρ_{华为}=\frac{10}{20}=0.5 ρ华为=2010=0.5, ρ 小 米 = 4 20 = 0.2 ρ_{小米}=\frac{4}{20}=0.2 ρ小米=204=0.2,那么:
E n t ( D ) = − ( 0.3 × l o g 0.3 + 0.5 × l o g 0.5 + 0.2 × l o g 0.2 ) ≈ 0.447 Ent(D)=-(0.3\times log0.3+0.5\times log0.5+0.2\times log0.2)\approx0.447 Ent(D)=−(0.3×log0.3+0.5×log0.5+0.2×log0.2)≈0.447
注:
1.约定ρ=0时,ρlogρ=0
ρ=0按照上面的例子就是说我们在统计的时候其实还统计了锤子手机的使用人数,那么y=4,不幸的是锤子手机使用的人数为0
2.当D只含有一类时(纯度最高),此时Ent(D)=0(最小值)
只含有一类,那么 ρ k = 1 ρ_k=1 ρk=1,log1=0,故Ent(D)=0
3.当D中所有类所占比例相同(纯度最低),此时Ent(D)=log|y|(最大值)
为什么D中所有类所占比例相同时Ent(D)=log|y|呢?为什么Ent(D)的最大值是log|y|呢?
这篇博客里面有比较详细的证明过程,感兴趣的朋友可以去看一下:https://blog.youkuaiyun.com/feixi7358/article/details/83861858
信息增益:假设离散属性a有V个不同的取值,若使用a来对样本集D进行划分,则会产生V个分支节点,每个分支节点上的样本在a上的取值都相同,记第V个分支节点上样本为 D v D^v Dv,则可计算 D v D^v Dv的信息熵,然后再根据每个节点上的样本占比给分支节点赋予权重
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+




 到【灌水乐园】发言
到【灌水乐园】发言







