







 本文详细介绍了正则表达式的概念与基础语法,包括通配符、元字符、字符集等,并深入探讨了Python中re模块的使用,如match、search、findall等函数的应用,以及如何通过编译提高效率。
本文详细介绍了正则表达式的概念与基础语法,包括通配符、元字符、字符集等,并深入探讨了Python中re模块的使用,如match、search、findall等函数的应用,以及如何通过编译提高效率。
前言:
正则表达式是我们创建来过滤文本的模式。一个程序或者脚本使用你所定义的模式来匹配数据,就像数据流过这个程序一样。如果数据匹配这个模式,则接受它并进行处理。如果数据不匹配这个模式,则拒绝接收。正则表达式利用通配符来表示数据流中的一个或多个字符。
1.基础知识:
普通字符,每个普通字符匹配其对应的字符

或关系(|),匹配|两侧任意的表达式即可

匹配单个字符(.),匹配除换行外的任意一个字符

匹配字符集,[字符集],匹配字符集中的任意一个字符

匹配字符集反集,[^字符集],匹配除字符集以外的任意一个字符

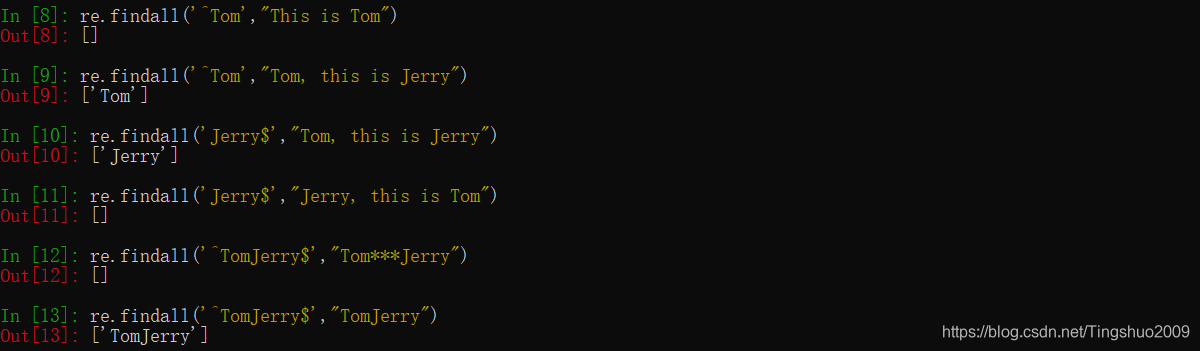
匹配字符串开始/结束位置(锚字符),^匹配目标字符串的开头,$匹配目标字符串的结尾
说明:^和$必然出现在正则表达式的开头和结尾,如果两侧同时出现,意味着中间的部分必须匹配整个目标字符串的全部内容,即绝对匹配
匹配字符重复,
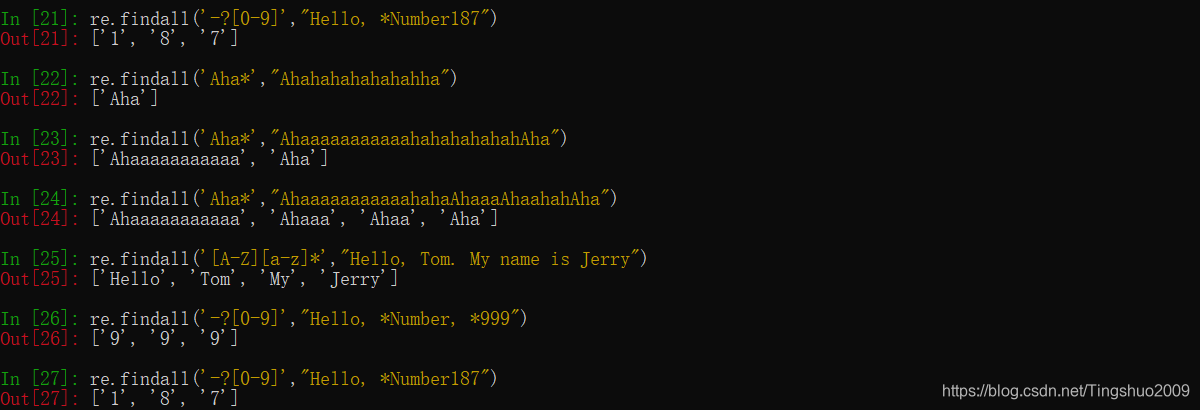
*,匹配前面的字符出现0次或多次
+,匹配前面的字符出现1次或多次
?,匹配前面的字符出现0次或1次
{n},匹配前面的字符出现n次
{m,n},匹配前面的字符出现m-n次

匹配任意(非)数字字符,\d匹配任意数字字符,\D任意非数字字符

匹配任意(非)普通字符,\w匹配普通字符,\W匹配非普通字符
普通字符指:数字,字母,下划线,汉字

匹配任意(非)空字符,\s匹配空字符,\S匹配非空字符
空字符指:空格,\r,\n,\t,\v,\f字符

匹配开头/结尾位置,\A表示开头位置,\Z表示结尾位置
匹配(非)单词的边界位置,\b表示单词边界,\B表示非单词边界
单词边界指:数字字母(汉字)下划线与其他字符的交界位置

在Python中,反斜杠在字符串中也有特殊的意义。要解决这个问题,如果想对特殊字符使用一个反斜杠字符,可以创建一个原始的字符串,使用r命名法。
元字符分类:
| 类别 | 元字符 |
| 匹配字符 | . […] [^…] \d \D \w \W \s \S |
| 匹配重复 | * + ? {n} {m,n} |
| 匹配位置 | ^ $ \A \Z \b \B |
| 其他 | | () \ |
2.在Python中使用正则表达式
re模块中常用的函数描述:
| 函数 | 描述 |
| match | 从字符串开头查找模式 |
| search | 从字符串的任意位置查找模式 |
| findall | 查找所有匹配模式的字串并返回一个列表 |
| finditer | 查找所有匹配模式的字串并返回一个迭代器 |
re模块的函数接收两个参数,第一个参数是正则表达式模式,第二个参数是应用这个模块的文本字符串。
正则表达式函数match()和search()在文本字符串匹配这个模式时返回布尔值True,在不匹配时返回False,这使得他们非常适合用于if-then语句中。

注意:match()函数匹配失败时,只返回一个False值,这在IDLE界面中是没有任何输出的。

findall()函数返回一个可以迭代的对象,可以使用for语句来遍历该结果。
编译正则表达式:如果你发现自己经常在代码中使用相同的正则表达式,可以将这个表达式编译并存储在一个变量中,使用compile()函数,指定作为参数的正则表达式以及存储结果的变量。

使用编译的正则表达式可以指定标志位来控制正则表达式的匹配,标志及控制内容如下:
| 标志 | 缩写 | 描述 |
| DEBUG |
| 显示调试信息 |
| IGNORECASE | I | 执行不区分大小写的匹配 |
| LOCLE | L | 支持来自本地字符集的字符 |
| MLTILINE | M | 从每一行的开始到结尾匹配单独的行 |
| DOTALL | S | 允许匹配换行符 |
| UNICODE | U | 使用Unicode字符 |
| VERBOSE | X | 允许模式中有空白字符 |



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











