




数据类型
- 简单数据类型
- 整数:
<class 'int'>(二进制、八进制、十进制、十六进制)[精确] - 浮点数:
<class 'float'>(12300=1.23e4 0.00911=9.11e-3)[存在误差] - 布尔值:
<class 'bool'>(True/False)[可用 not/or/and 进行运算]
- 整数:
- 容器数据类型
- 字符串:
<class 'str'>(’ ’ 或 " ") - 列表:
<class 'list'>,符号为[ ] - 元组:
<class 'tuple'>,符号为( ) - 字典:
<class 'dict'>,符号为{ } - 集合:
<class 'str'>,符号为( [ ] )
- 字符串:
整数
整数与数学中的整数定义一致,在 Python 中可以精确表示且取值范围没有限制
此外,我们需要了解一下常用的进制:
- 十进制:911
- 二进制:以0b或0B开头,0b1110001111
- 八进制:以0o或0O开头,0o1617
- 十六进制:以0x或0X开头,0x38f
浮点数
浮点数与数学中的小数定义一致,在 Python 及其他程序设计语言都存在浮点数无法精确表示的情况。(计算机内部采用二进制,而二进制有时无法精确表示某些小数),且取值范围有所限制,约为 (-10)307 至 10308,精度数量级为10-16。

附:浮点数间比较常用 round 函数。round(x,d) #对x四舍五入,d为小数位数
不确定尾数基本发生在10-16位左右,因此 round 函数十分有效。但是round函数并不是完全的四舍五入,在 .5这个数上出于“平等价值”的考虑,存在奇进偶不进的情况.但若5后面还存在其他小数,即并非对称情况时,即采取四舍五入方法,前提仍是小数位数小于16位。如下图所示:

附:科学计数法 9.11e-3 == 0.00911 9.11e3 == 9110.0
复数
复数与数学中的复数定义一致,在 python 中虚数单位为 j,值得注意的是复数的实部和虚部都是浮点数。
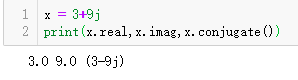
布尔类型
- Python把0,空字符串’ ’ 和 None看成 False,其他数值和非空字符集都看成 True
a = True
print(a and 'a=T' or 'a=F')
#输出为 'a=T'
- 短路计算:又称惰性求值,可以理解为在问题的结果可以提前判定后,不需要观察问题剩余的部分。
- 逻辑计算:逻辑计算有三种基本类型:与(and)、或(or)、非(not)。其运算优先级依次为not、and、or。
if True or False and False:
print("yes")
else:
print("no")
# 输出yes
a = 'python'
print('hello,', a or 'world')
#a已确定or运算为真,输出 'hello python'
b = ''
print('hello,', b or 'world')
#b为false,不能判定or运算的结果,输出'hello world'
a = 'python'
print('hello,', a and 'world')
#仅凭a不能判定and运算的结果,输出 'hello world'
b = ''
print('hello,', b and 'world')
#and运算结果为False,输出'hello'
容器(组合)数据类型
序列类型
序列类型是一维元素向量,因为元素之间存在先后关系,可通过序号访问。所以称为序列类型。典型代表有字符串类型、列表类型和元组类型。其操作函数大致如下所示:
x in s:如果x是s的元素,返回True;否则返回Falsex not in s:如果x不是s的元素,返回True;否则返回Falses + t:连接s和ts*n或n*s:将序列s复制n次s[i]:索引,返回序列的第i个元素s[i:j]:切片,返回包含序列s第i到j个元素的子序列(不包含第j个元素)s[i:j:k]:步骤切片,返回包含序列s第i到j个元素以k为步长的子序列len(s):序列s的长度(元素个数)min(s):序列s的最小元素max(s):序列s的最大元素s.index(x):序列s中第一次出现元素x的位置s.count(x):序列s中出现x的总次数sum(iterable[,start=0]):返回序列iterable与可选参数start的总和sorted(iterable,key=None,reverse=False):对所有可迭代对象进行排序操作zip(iter1[,iter2[...]])- 用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的对象,这样做的好处是节约了不少的内存
- 可以使用
list()转换来输出列表 - 如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用
*号操作符,可以将元组解压为列表
字符串类型
字符串是指由0或多个字符组成的有序字符序列。
-
单行字符串用 ’ ’ 或 “ ” 表示
-
多行字符串用 ‘’’ ‘’'表示
-
如果字符串含有 ’ ’ ,可用 " " 表示;含有 " ",可用 ’ ’ 表示;如果同时包含 " " 和 ’ ’ ,则用 ‘’’ ‘’’ 表示(也可用转义符 \ 表示)。

注:转义符 \ -
转义符表达特定字符本身的含义
-
如果在字符串中既需要出现单引号,又需要出现双引号,可使用转义符。
-
转义符形成一些组合,表达一些不可打印的含义
\b:回退 \n:换行符(光标移动到下行首) \r:光标移动到本行首
\a:响铃 \t:水平制表符(光标向右移动一个制表符位)

-
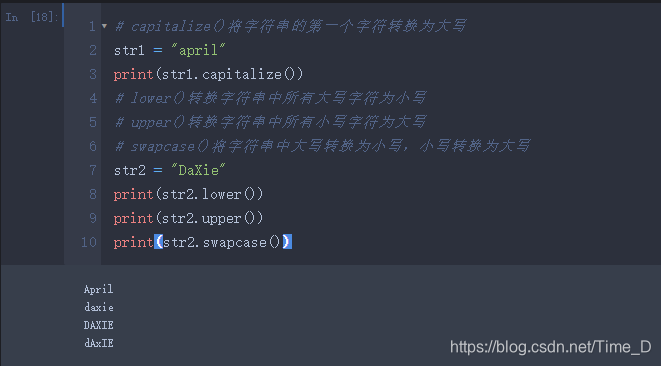
常用内置方法
capitalize()将字符串的第一个字符转换为大写lower()转换字符串中所有大写字符为小写upper()转换字符串中所有小写字符为大写swapcase()将字符串中大写转换为小写,小写转换为大写
count(str,beg=0,end=len(string))返回str在string里面出现的次数,如果beg或者end指定则返回指定范围内str出现的次数endwith(suffix,beg=0,end=len(string))检查字符串是否以指定子字符串suffix结束startwith(substr,beg=0,end=len(string))检查字符串是否以指定子字符串substr开头find(str,beg=0,end=len(string)检测str是否包含在指定字符串中rfind(str,beg=0,end=len(string)类似于find()函数,不过是从右边开始查找isnumeric()检查字符串是否为只包含数字字符ljust(width[,fillchar])返回一个原字符串左对齐,并使用fillchar(默认空格)填充至长度width的新字符串rjust(widh[,fillchar])返回一个原字符串右对齐,并使用fillchar(默认空格)填充至长度widh的新字符串lstrip([chars])截掉字符串左边的空格或指定字符rstrip([chars])截掉字符串右边的空格或指定字符strip([chars])在字符串上执行lstrip()和rstrip()partition(sub)找到子字符串sub,把字符串分为一个三元组(pre_sub,sub,fol_sub),如果字符串中不包含sub则返回('原字符串',' ',' ')rpartition(sub)类似于partition()方法,不过是从右边开始查找replace(old,new,[,max])把字符串中的old替换成new,如果max指定,则替换不超过max次split(str=" ", num)不带参数默认是以空格为分隔符切片字符串,如果num参数有设置,则仅分割num个子字符串,返回切片后的子字符串拼接的列表splitlines([keepends])按照行(’\r’,’\r\n’,’\n’)分割,返回一个包含各行作为元素的列表,如果参数keepends为False,不包含换行符,如果为True,则保留换行符
-
补充知识:
-
ASCII编码:因为计算机只能处理数字,因此要处理文本必须先将其转化为数字。最早的计算机在设计时采用八个比特(bit)作为一个字节(byte),所以一个字节所能表示的最大的整数是255,0-255被用来表示数字、大小写英文字母和一些符号,这个编码表称为ASCII编码。
-
Unicode编码:因为中日韩等国家的语言无法用一个字节表示,因此为了统一所有文字的编码,Unicode编码应运而生,用两个字节来表示一个字符,高字节全部填为0。
-
普通字符串如“Python”是用ASCII编码,而中文则用Unicode编码,字符串前加 u 表示用Unicode编码。如果中文字符串在Python环境下遇到 UnicodeDecodeError,这是因为.py文件保存的格式有问题。可以在第一行添加注释
# -*- coding: utf-8 -*-
(注意:python3版本已经不用再预先设置)
列表类型
- 列表是包含0个或多个元素的有序序列,可以随时查找、添加、删除和修改其中的元素。列表没有长度限制,不需要预定义长度。
- 列表中的元素是按照顺序排列的,用 [ ] 符号创建,也可以通过 list(x) 函数将集合、字符串类型或字典类型转换成列表类型。
L = ['Adam', 95.5,'Lisa',85,'Bart',59]
print (L)
- 一个元素也没有的list:空列表
empty_list = [ ]或empty_list=list() - 可根据列表中的元素的序号进行引用,即索引:
L[3] #输出为85 - 获得列表的一个片段,即切片:
L[:-2] #输出为['Adam', 95.5, 'Lisa', 85] - 注意:由于list的元素可以是任何对象,因此列表中所保存的是对象的指针。即使保存一个简单的 [1,2,3],也有3个指针和3个整数对象。例如 x = [a]*4 操作中,只是创建4个指向 list 的引用,所以一旦 a 改变,x 中4个 a 也会随之改变。
操作方法
列表类型存在一些操作方法,使用格式为:
<列表变量>.<方法名称>(<方法参数>)
- 列表元素添加
(1)list.append(x):将元素x添加到末尾
(2)list.extend(x):将序列x添加到末尾
(3)list.insert(i,x):将元素x添加到列表第i个位置 - 列表元素删除
(1)list.pop(i):#删除列表第i个位置的元素,默认i=-1
(2)list.remove(x):删除列表中第一个元素x
(3)del list[i:j]:删除列表的多个元素
(4)list.clear():删除列表中所有元素 - 列表元素替换
list[i]=x:将列表i个位置的元素替换成元素x - 列表元素反转
list.reverse():列表元素反转 - 列表元素复制
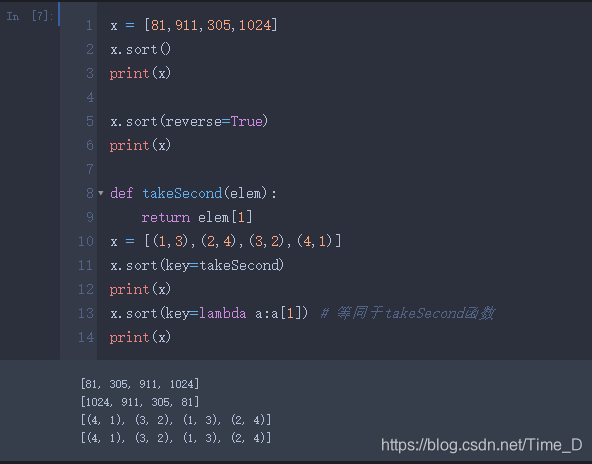
list.copy(ls):生成一个新列表,复制 ls 中所有元素 - 列表元素排序
list.sort(key=None,reverse=False):对原列表进行排序
列表是一个十分灵活的数据结构,具有处理任意长度、混合类型的能力,并提供了丰富的操作手段,因此其在使用组合数据类型管理批量数据时尤为重要。故在此增加一些复杂操作,以便更好地了解和使用列表。
- 列表生成式
例:请利用列表生成式生成列表 [1x2, 3x4, 5x6, 7x8, …, 99x100]
print([x*(x+1) for x in range(1,100,2)])
- 条件过滤式
例:编写一个函数,它接受一个列表,然后把其中的所有字符串变成大写后返回,非字符串元素将被忽略。(注:isinstance(x, str) 可以判断变量 x 是否是字符串)
def toUppers(L):
return [x.upper() for x in L if isinstance(x,str)]
- 多层表达式
例:利用 3 层for循环的列表生成式,找出对称的 3 位数,如101 。
print([a*100+b*10+c for a in range(1,10) for b in range(10) for c in range(10) if a==c])
元组类型
- 元组是特殊的列表,一旦创建,则无法修改。
- 元组创建符号为 ( )
April = ("听从你心","无问西东") - 创建单元素元组:和列表不同,元组中只有一个元素时,会默认符号 ( )此时不表示元组,而是作为括号计算时的优先级,所以单元素元组要后加" , "
April_one = ("无问西东") #输出为 无问西东 ,即字符串形式 April_two = ("无问西东",) #输出为 ('无问西东',) , 即元组形式 - 元组中若含有可变类型的数据,则该数据可以改变,即元组是指向不变
April = ('爱你所爱', '行你所行',['听从你心', '无问西东'])
L = April[2]
L(0) = "一身诗意千寻瀑"
L(1) = "万古人间四月天"
#此时 April 输出为 ('爱你所爱', '行你所行', ['一身诗意千寻瀑', '万古人间四月天'])
- 注意:元组类型操作基本等同于列表操作,故操作符号仍为[]
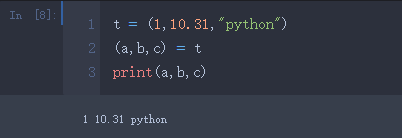
- 解压元组
- 解压(unpack)一维元组(有几个元素左边括号定义几个变量)
- 解压二维元组(按照元组里的元组结构来定义变量)
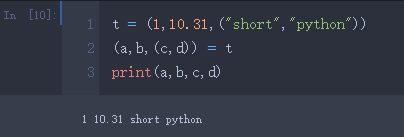
- 解压(unpack)一维元组(有几个元素左边括号定义几个变量)
映射类型
映射类型是“键-值”数据项的组合,每个元素是一个键值对,即元素是(key,value),元素之间是无序的,是序列类型的一种扩展。典型代表是字典类型。
可变类型与不可变类型
- 结论
- 数值、字符串和元组是不可变类型
- 列表、集合和字典是可变类型
- 判定依据
- 麻烦方法:用
id(x)函数,对 x 进行某种操作,比较操作前后的 id,如果不一样,则 x 不可变,如果一样,则 x 可变 - 便捷方法:用
hash(x)函数,只要不报错,证明 x 可被哈希,即不可变;若报错则为可变


- 麻烦方法:用
字典类型
- “键值对”是组织数据的一种重要方式,广泛应用在当代大型信息系统中,如Web系统。其基本思想是将“值”信息关联一个“键”信息,进而通过键信息查找对应的值信息,这个过程叫映射。
- Python语言中字典类型使用大括号
{}创建,每个元素是一个键值对。
注:特殊地,元组可作为一个键,而列表不能,因为元组是不可变类型 - dict的作用是建立一组 key 和一组 value 的映射关系,dict的key是不能重复的。
如下所示,冒号左边为key,右边为value,dict就是通过key来寻找相应的value。 - 需要注意的是,大括号{}默认生成的是字典类型,其数据类型会根据里面元素性质变化:即嵌入键值对时生成字典类型,嵌入独立元素时生成集合类型
d = {
'A': 95,
'B': 85,
'C': 60
}
操作函数
len(d):字典d中的元素个数min(d):字典d中键的最小值max(d):字典d中键的最大值dict():生成一个空字典
操作方法
字典类型存在一些操作方法,使用语法形式是:
<字典变量>.<方法名称>(<方法参数>)
查找:
d.keys():返回所有的键信息d.values():返回所有的值信息d.items():返回所有的键值对d.get(key,default):键存在则返回相应值,否则返回默认值defaultd.pop(key,default):键存在则返回相应值,同时删除键值对,否则返回默认值defaultd.setdefault(key,default=None):和get()方法类似,如果键不存在于字典中,将会添加键并将值设为默认值
添加
dict.fromkeys(seq[,value]):用于创建一个新字典,以序列 seq 中元素做字典的键, value 为字典所有键对应的初始值b.update(a)#将字典a的内容添加到字典b中
删除
d.popitem():随机从字典中取出一个键值对,以元组(key,value)形式返回,同时将该键值对从字典中删除del d[key]:删除字典给定键 key 所对应的值d.popiem():随机返回并删除字典中的一对键和值,如果字典已经为空,却调用了此方法,就抛出 KeyError 异常d.clear():删除所有的键值对,清空字典
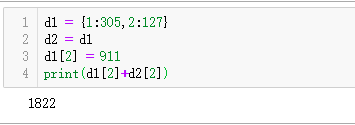
复制
Python 直接赋值、浅拷贝和深拷贝解析
更新
集合类型
- Python的集合类型与数学中的集合概念一致,即包含0个或多个数据项的无序组合。
- set作为集合持有一系列元素,其元素不能重复,且元素是无序的。
- 创建 set 的方式有两种,一是直接使用大括号{ },二是调用
set()工厂函数把列表或元组转换成集合:
s1 = {99,80,75}
s2 = set([99,80,75])
- Python 也提供了不能改变元素的集合的实现版本,即不能增加或删除元素,类型名叫
frozenset。

操作符
- S-T / S.difference(T) :返回差集,即包括在集合S中单不在集合T中的元素
- S&T / S.intersection(T):返回交集,即包括同时在集合S和T中的元素
- S^T / S.symmetric_difference(T):返回集合的异或,即包括集合S和T中非共同元素
- S|T / S.union(T):返回并集,即包括集合S和T中所有元素

操作函数
查询
访问 set中的某个元素实际上就是判断一个元素是否在set中。
利用 in 操作符进行判断。
s = {'A','B','C'}
print('B' in s)
更新
set.add(item):给集合添加元素,如果添加的元素在集合中已存在,则不执行任何操作set.update(set):修改当前集合,可以添加新的元素或集合到当前集合中,如果添加的元素在集合中已存在,则该元素只会出现一次,重复的会忽略set.remove(item):移除集合中的指定元素。如果元素不存在,则会发生错误set.discard(value):移除指定的集合元素。如果元素不存在,也不会发生错误set.pop():随机移除一个元素
例:针对下面的set,给定一个list,对list中的每一个元素,如果在set中,就将其删除,如果不在set中,就添加进去。
s = {'Adam', 'Lisa', 'Paul'}
L = ['Adam', 'Lisa', 'Bart', 'Paul']
for name in L:
if name in s:
s.remove(name)
else:
s.add(name)
print(s)
遍历
s = set([('A', 95), ('B', 85), ('C', 60)])
for x in s:
print(x[0]+':',x[1])

















 3209
3209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









