selector选择器的使用
最新推荐文章于 2025-09-04 12:32:31 发布




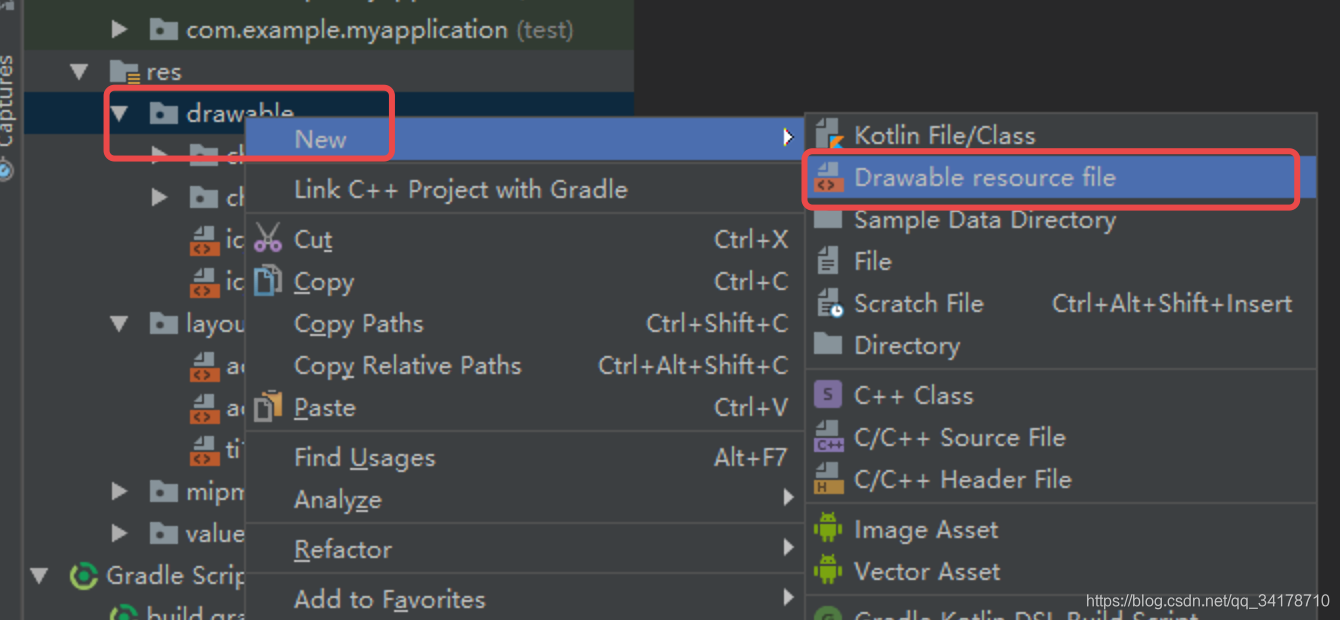
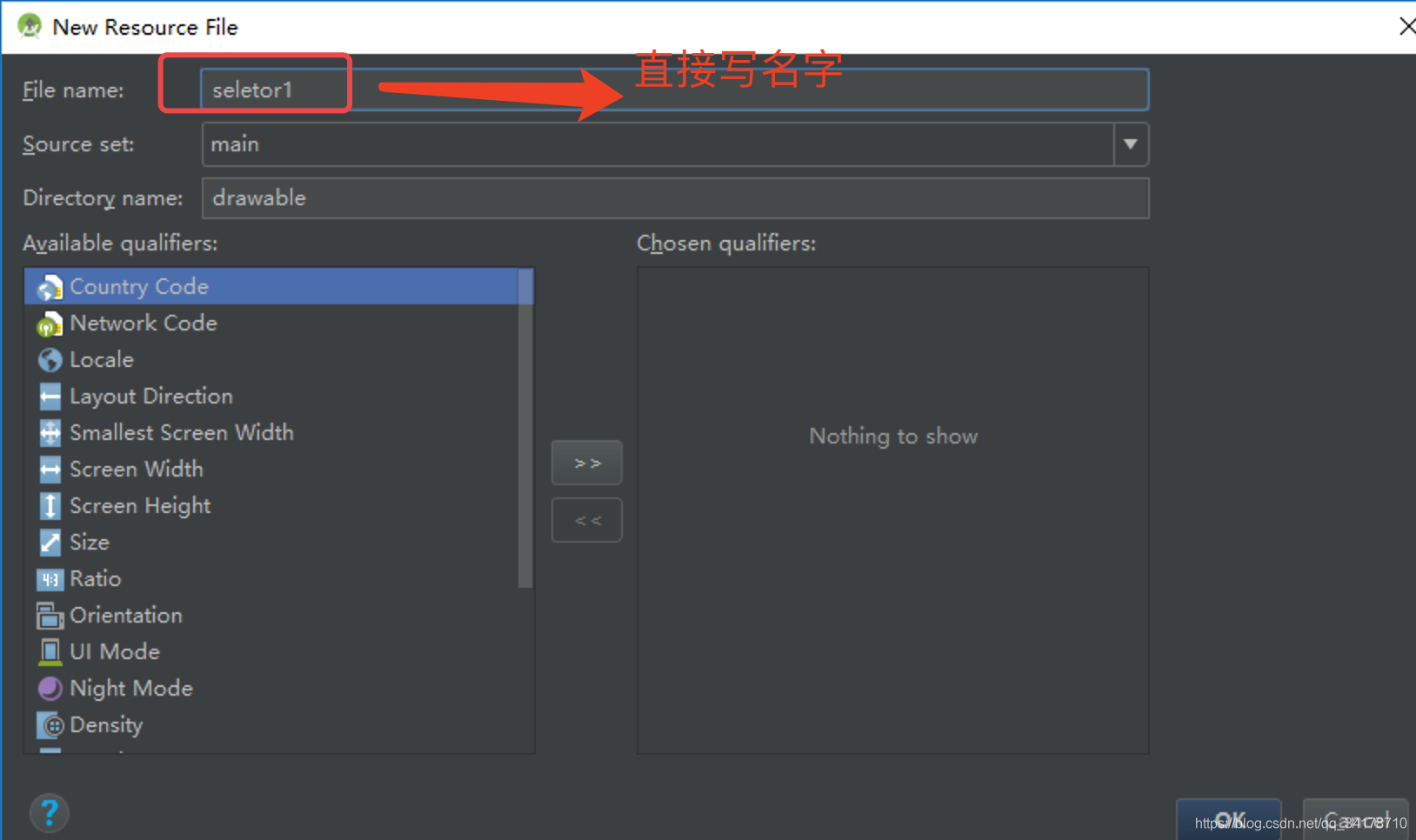
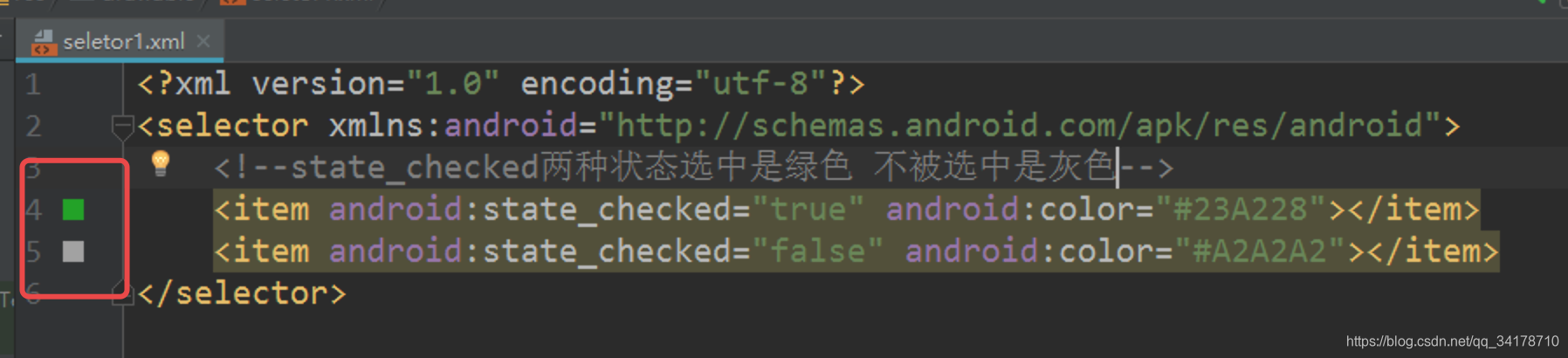
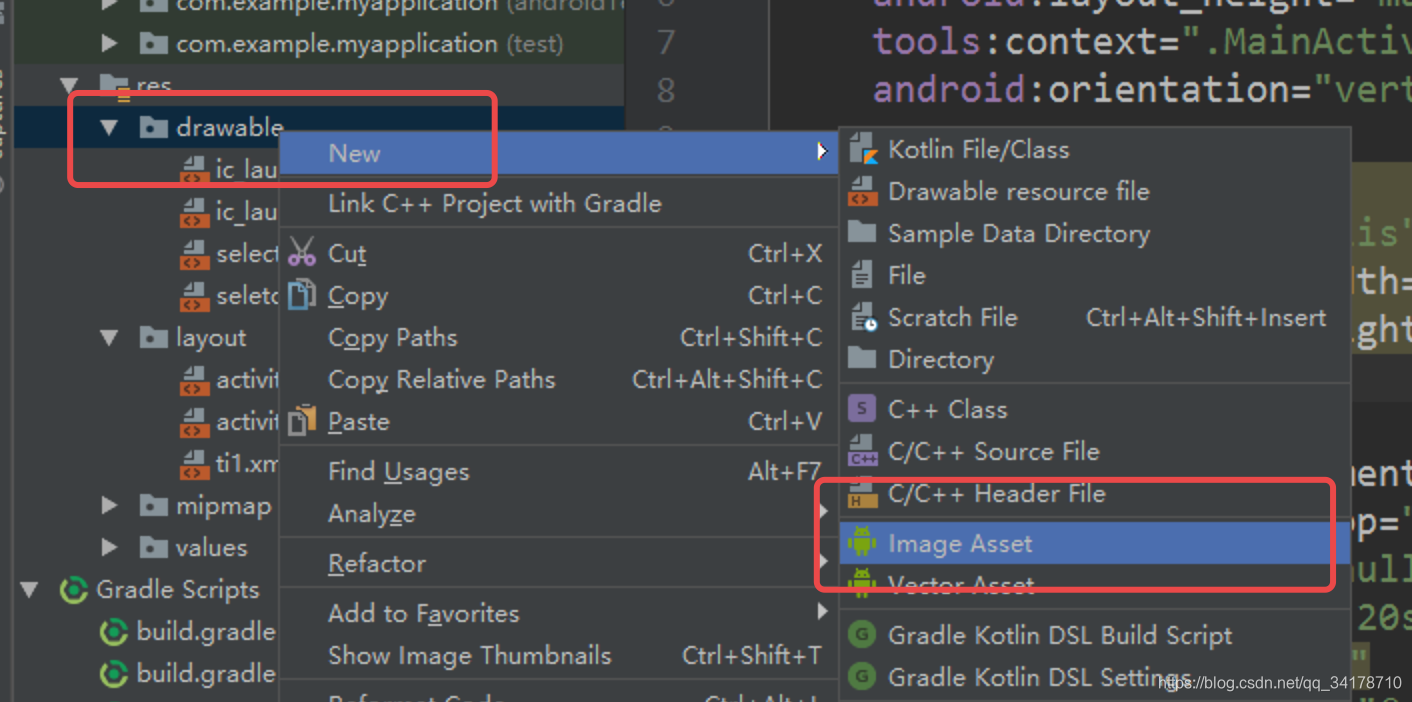
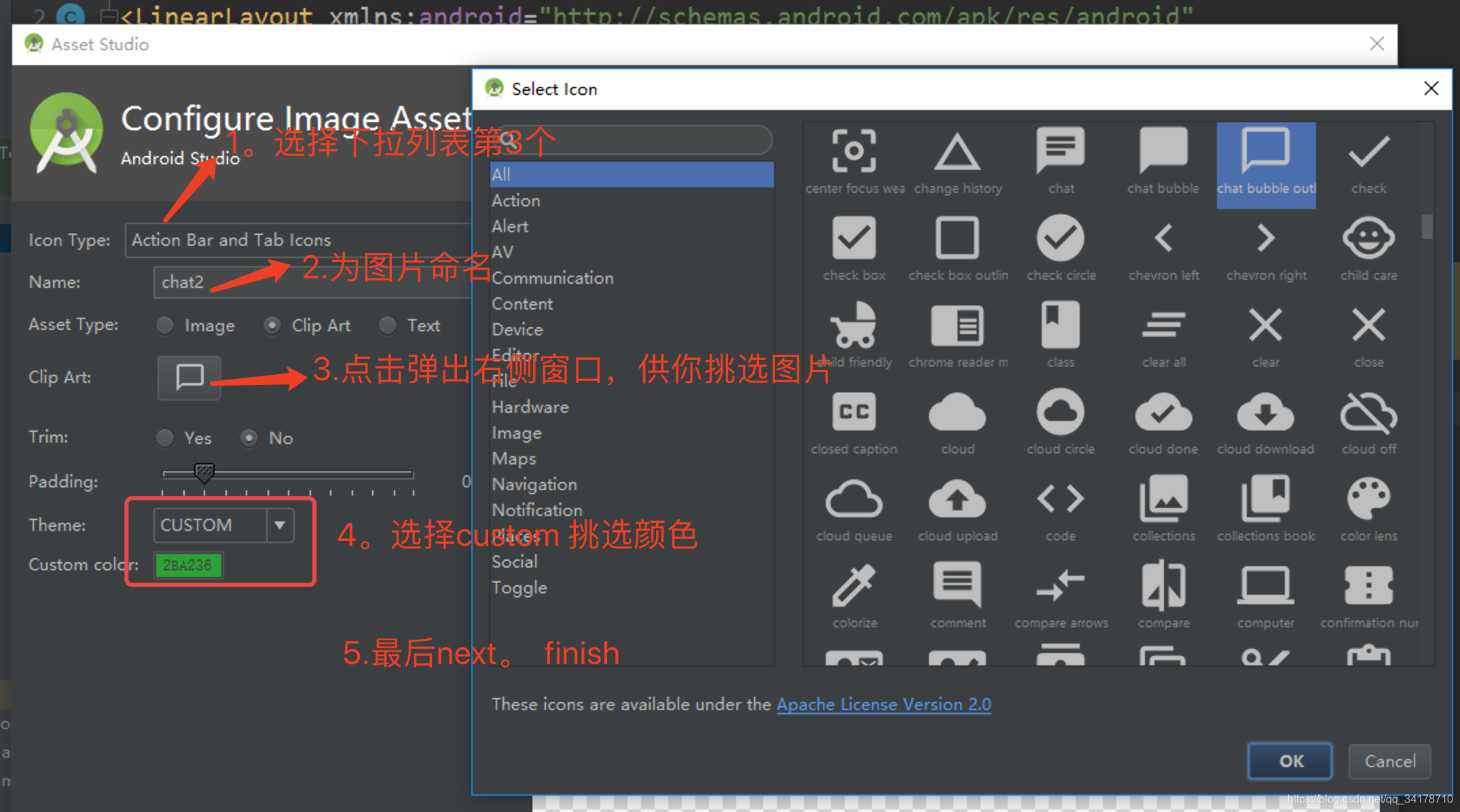
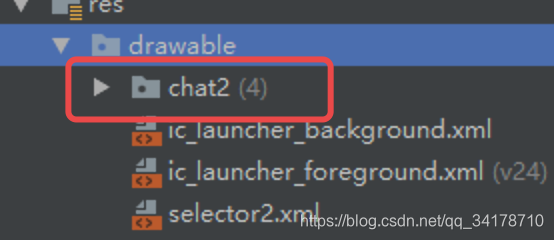
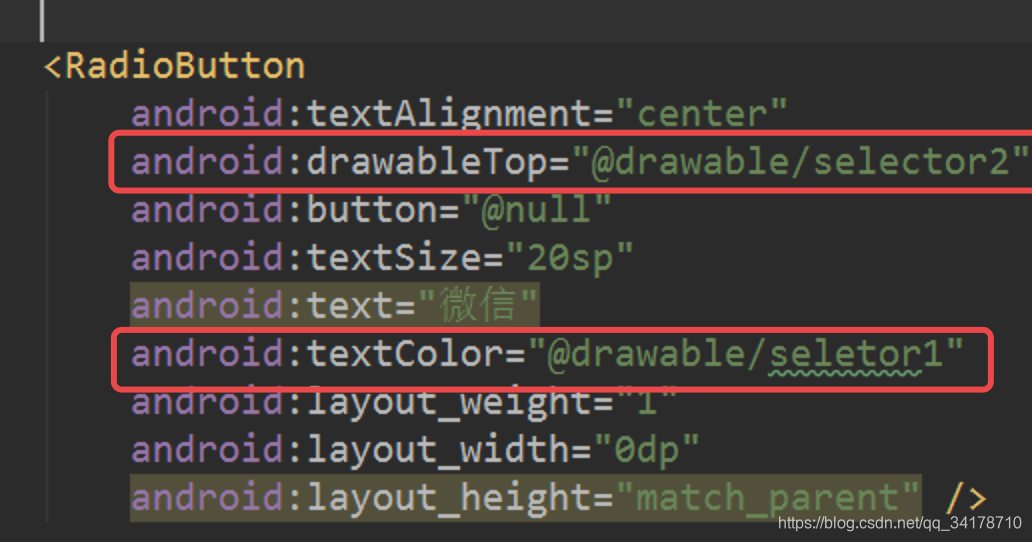
 本文介绍如何在Android中创建和使用Selector选择器,包括文字颜色和图片改变的选择器,通过实例展示点击底部元素时,如何实现图片和颜色的动态切换。
本文介绍如何在Android中创建和使用Selector选择器,包括文字颜色和图片改变的选择器,通过实例展示点击底部元素时,如何实现图片和颜色的动态切换。
本文介绍如何在Android中创建和使用Selector选择器,包括文字颜色和图片改变的选择器,通过实例展示点击底部元素时,如何实现图片和颜色的动态切换。
本文介绍如何在Android中创建和使用Selector选择器,包括文字颜色和图片改变的选择器,通过实例展示点击底部元素时,如何实现图片和颜色的动态切换。
 2681
2681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言