




 本文深入探讨Transformer模型,解释其如何克服RNN/LSTM的长期依赖和并行学习问题,通过自注意力机制计算单词间的依赖关系。同时,介绍BERT在预训练embedding中的创新,特别是CLS在分类任务中的应用。
本文深入探讨Transformer模型,解释其如何克服RNN/LSTM的长期依赖和并行学习问题,通过自注意力机制计算单词间的依赖关系。同时,介绍BERT在预训练embedding中的创新,特别是CLS在分类任务中的应用。
Transformer
Transformer不是一个时序的模型,但是可以捕获时序的特点
任何用到LSTM都可以用Transformer来替代
RNN/LSTM的缺陷
1、long-term dependency:虽然加了attention,但是还是会出现长期依赖的问题(很遥远的信息被遗忘)
2、不能是并行的学习:因为本身就是时序的
3、shallow model:从时序的角度看是深度模型,但是从纵向看是一个浅层模型
Transformer可以解决上述RNN的问题

transformer是一个深度学习模型
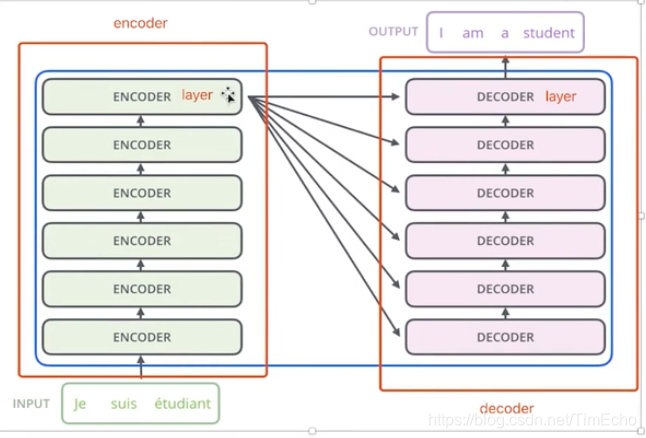
transformer是有一个encoder和一个decoder组成的
每个encoder都是由多个encoder层组成
每个encoder层中包含Feed Forward和self attention两部分
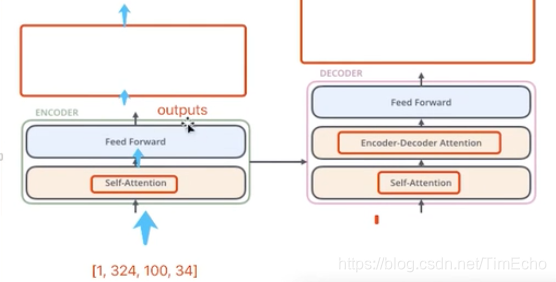
Encoder Block
每个encode层如下结构:
每个单词的embedding,经过self attention后会生成对应的z,然后z再经过feed forward生成r,每个单词对应一个r
如果是第一层,那输入的embedding是一个静态的,当经过第一层后就变成动态的
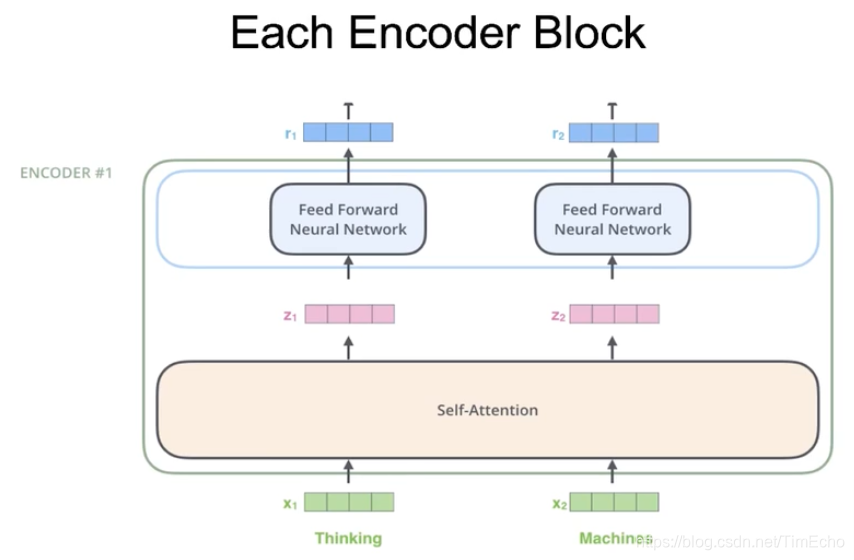

self attention
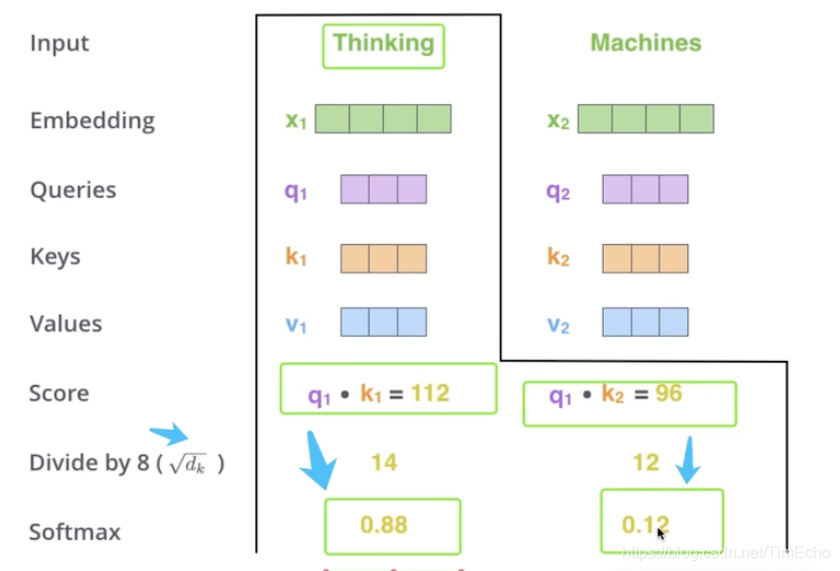
对于Thingking这个单词,首先得到他的embedding,
然后在自注意力机制中,将embedding分成三部分:q k v
计算thinging单词的q和这个句子中其他单词k的乘积。
每个乘积都除以一个经验值8,得到一个关联数
然后通过softmax算出thinking单词对整个句子其他每个单词的一个依赖程度,
接着使用0.88*v1 + 0.12 * v2,
算出thinking这个单词最终的结果z1
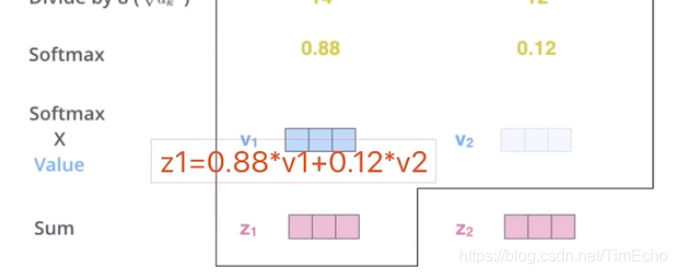
也就是通过self attention这种方式,我以后不使用时序模型,也能计算单词之间的依赖关系
通过非时序模型,解决单词之间的依赖关系。
BERT

在pretraing embedding中
word2vec:有skipgram、Glove
上下文表示法:
学习上下文的embedding中
1、LM/LSTM
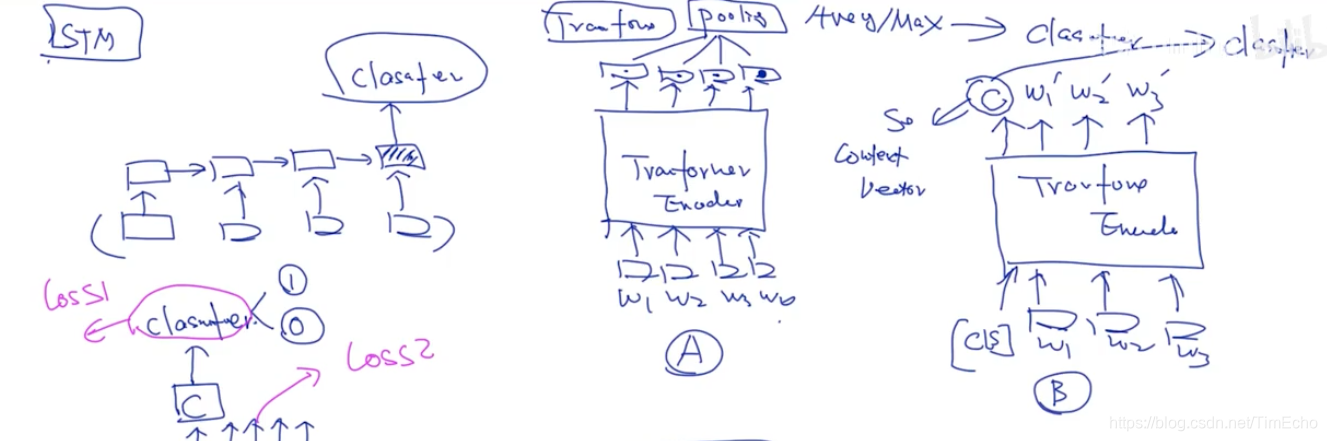
在LSTM中,如果我要做情感分析,那就是加一个分类,得到文本的情感词分类,可以在时序的最后加一个分类器,因为最后一个词的表示是可以代表前边的单词的
但是在transformer中,句子的输入不是时序性的,无法加分类器进去BERT的处理方式就是在句子输入transformer时多了一个CLS的部分,
经过Encoder部分后,CLS的输出为C,它是可以表示整个句子的,所以可以使用C来作为分类器的依据

















 3345
3345

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









