




网关
今天,小白的老师让小白写一个网关,小白学艺不精,过来向大头求救了。


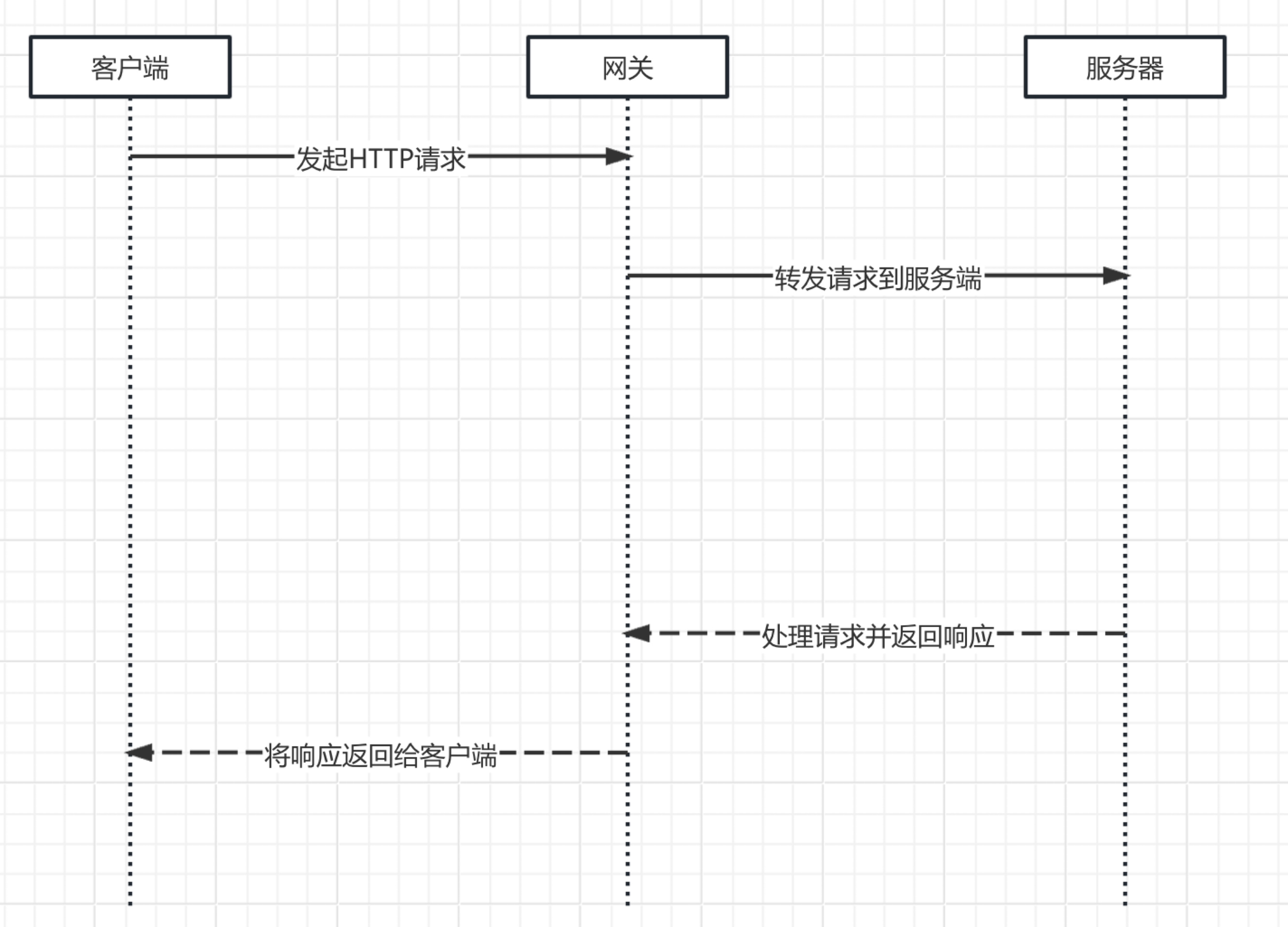
网关是什么?看图说话,很明显,她是介于客户端和服务器之间的一个中间层。
那么为什么要有网关?
- 网关可以承接更多的流量
- 网关可以对流量做减法
- 网关可以添加其他和业务无关的能力,和业务解藕
- 网关可以实现负载均衡
网关可以承接更多的流量
服务器的逻辑通常是来一个请求A,出现一个A线程进行处理。来一个请求B,出现一个B线程进行处理。
而有了网关就变成了
- 请求A -> 网关main线程 -> 网关worker1线程 -> 服务器A线程
- 请求B -> 网关main线程 -> 网关worker2线程 -> 服务器B线程
为什么能承接更多的流量,因为承接流量的线程,实在Main线程上面,而Main线程,仅仅负责分发请求。所以它很快。
网关可以对流量做减法
网关就如同一个漏斗,可以对流量做减法。
比如实现限流、权限检查、缓存处理。那么进来的10个请求,可能只有1个请求到达服务器,减轻了服务器的压力。
请求流程如下:
- 请求A -> 网关main线程 -> 网关worker1线程 -> 网关权限检查不通过,返回错误
- 请求B -> 网关main线程 -> 网关worker2线程 -> 服务器A线程
网关可以添加其他和业务无关的能力,和业务解藕
如同上面说的,网关可以实现一些和业务无关的能力,比如现限流、权限检查、缓存处理。
目前用的最多的网关应该是nginx。nginx可以通过lua来扩展实现一些功能。比如上面说的这些。
还有一些比如像OpenResty这种,也就是基于nginx和lua来进行扩展。
网关可以实现负载均衡
什么是负载均衡?简单来说就是后端有多个服务器,通过负载均衡可以把请求流量转发给不同的服务器去处理。
这个具体后面会实操讲解。
第一版网关实现


第一版网关的基本原理如上面说的,仅仅是实现了服务器端,也就是Main线程和客户端,也就是Worker线程。
执行流程如下:
- 通过Netty实现一个服务器,接收真正客户端的请求
- 然后把请求给Worker线程
- Worker线程启动一个客户端请求真正的服务器。
- Worker线程接收到真正服务器的返回数据。
- Worker线程将数据返回给真正的客户端。
部分代码如下。
// 创建一个netty服务端,接收客户端的请求
EventLoopGroup bossGroup = new NioEventLoopGroup(1);
EventLoopGroup workerGroup = new NioEventLoopGroup(16);
try {
// 一些参数 初始化
ServerBootstrap b = new ServerBootstrap();
b.option(ChannelOption.SO_BACKLOG, 128)
.childOption(ChannelOption.TCP_NODELAY, true)
.childOption(ChannelOption.SO_KEEPALIVE, true)
.childOption(ChannelOption.SO_REUSEADDR, true)
.childOption(ChannelOption.SO_RCVBUF, 32 * 1024)
.childOption(ChannelOption.SO_SNDBUF, 32 * 1024)
.childOption(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT);
b.group(bossGroup, workerGroup).channel(NioServerSocketChannel.class)
.handler(new LoggingHandler(LogLevel.DEBUG))
.childHandler(new HttpInboundInitializer(this.proxyServers));
Channel ch = b.bind(port).sync().channel();
System.out.println("开启netty http服务器,监听地址和端口为 http://127.0.0.1:" + port + '/');
ch.closeFuture().sync();
} finally {
bossGroup.shutdownGracefully();
workerGroup.shutdownGracefully();
}
客户端处理代码如下:
private void fetchGet(final FullHttpRequest inbound, final ChannelHandlerContext ctx, final String url) {
final HttpGet httpGet = new HttpGet(url);
httpGet.setHeader(HTTP.CONN_DIRECTIVE, HTTP.CONN_KEEP_ALIVE);
httpclient.execute(httpGet, new FutureCallback<HttpResponse>() {
@Override
public void completed(final HttpResponse endpointResponse) {
try {
handleResponse(inbound, ctx, endpointResponse);
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public void failed(final Exception ex) {
httpGet.abort();
ex.printStackTrace();
}
@Override
public void cancelled() {
httpGet.abort();
}
});
}
private void handleResponse(final FullHttpRequest fullRequest, final ChannelHandlerContext ctx, final HttpResponse endpointResponse) throws Exception {
FullHttpResponse response = null;
try {
byte[] body = EntityUtils.toByteArray(endpointResponse.getEntity());
response = new DefaultFullHttpResponse(HTTP_1_1, OK, Unpooled.wrappedBuffer(body));
response.headers().set("Content-Type", "application/json");
response.headers().setInt("Content-Length", Integer.parseInt(endpointResponse.getFirstHeader("Content-Length").getValue()));
} catch (Exception e) {
e.printStackTrace();
response = new DefaultFullHttpResponse(HTTP_1_1, NO_CONTENT);
exceptionCaught(ctx, e);
} finally {
if (fullRequest != null) {
if (!HttpUtil.isKeepAlive(fullRequest)) {
ctx.write(response).addListener(ChannelFutureListener.CLOSE);
} else {
ctx.write(response);
}
}
ctx.flush();
}
}
来看一下有网关和没网关的服务器请求架构图吧。
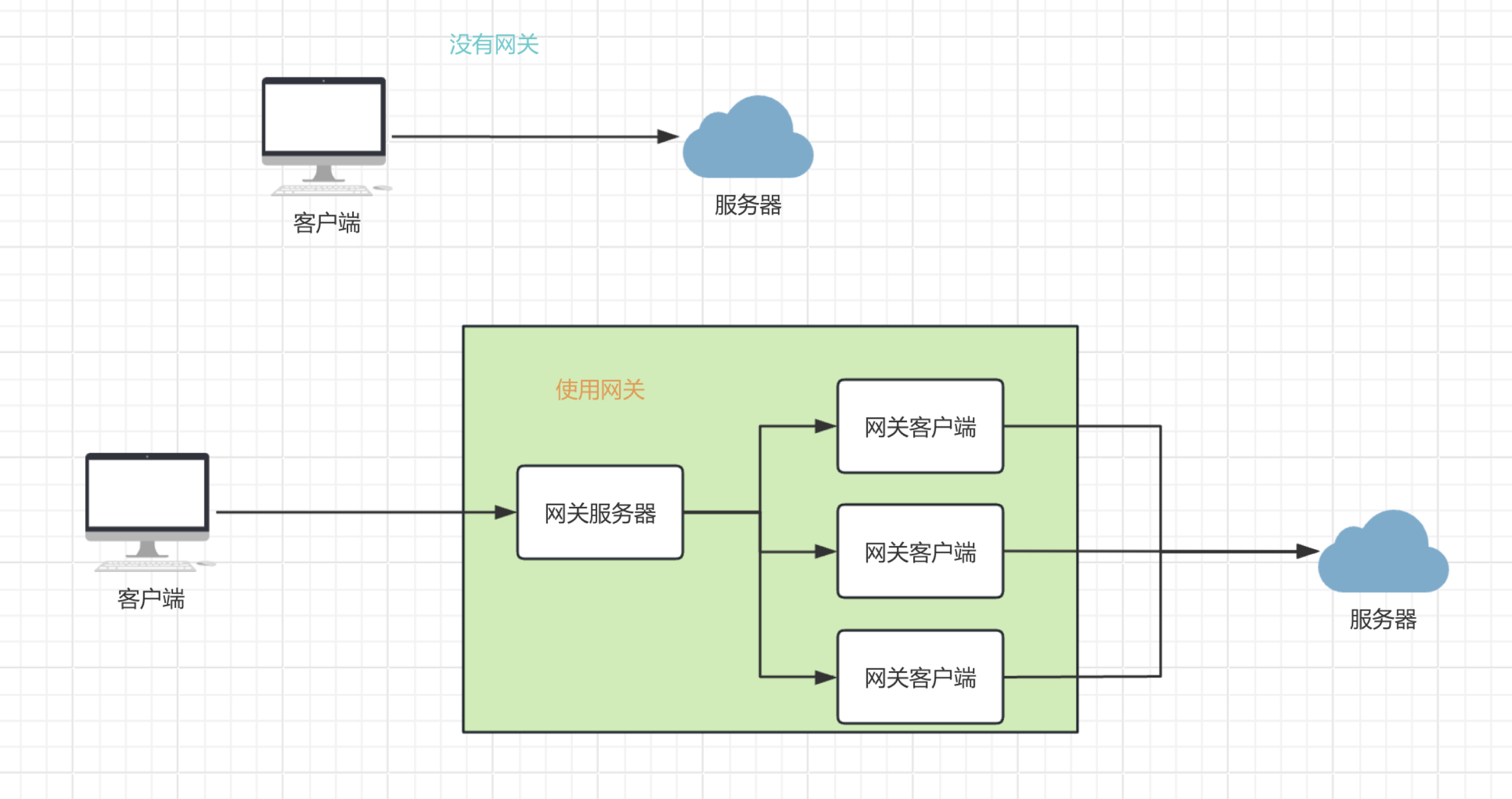
filter
完成以后小白很高兴


接下来再给简陋的网关加点装饰,实现一些业务外的功能,给服务器减减压。
filter可以做什么,看一下下面filter的架构图。
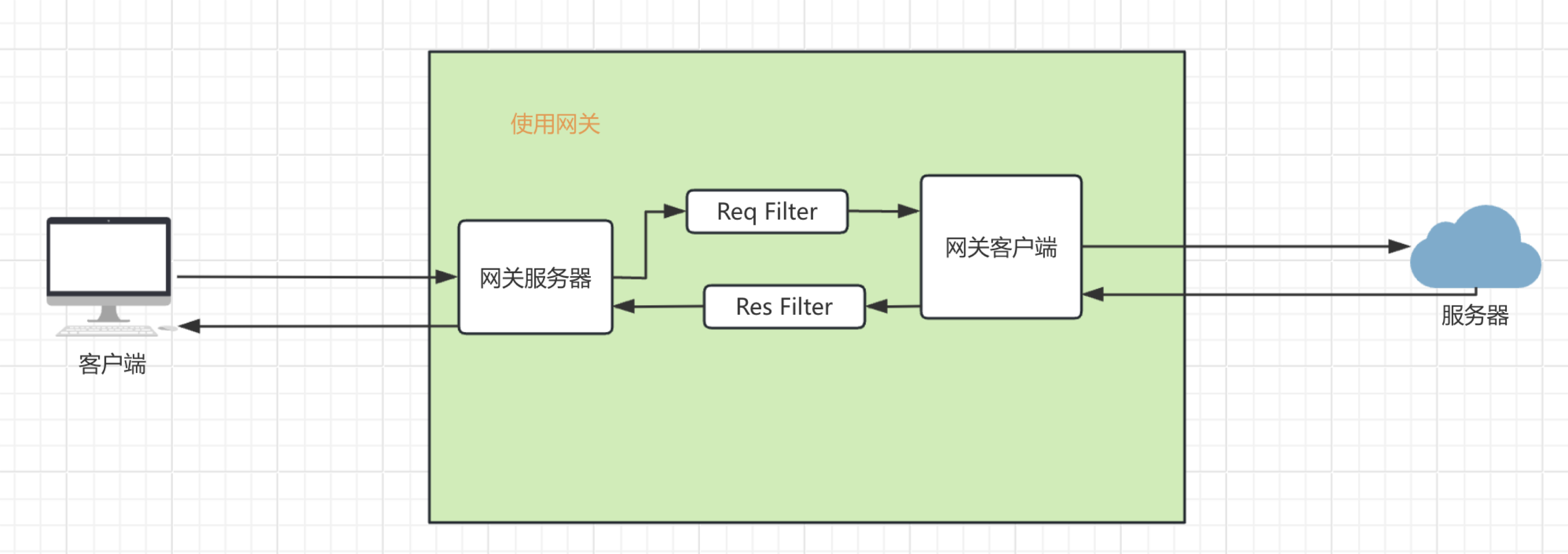
Req Filter在每次请求执行之前运行。那么它能干什么呢?它可以实现权限检查。流程如下
- 请求A -> 网关main线程 -> 网关worker1线程 -> Req Filter: 权限检查不通过,返回错误
- 请求B -> 网关main线程 -> 网关worker2线程 -> Req Filter: 权限检查通过,继续请求 -> 服务器A线程
Filter可以是链式的,也就是可以增加多个Filter.实现不同的功能。比如在权限检查以外还要做跨域支持。
- 请求A -> 网关main线程 -> 网关worker1线程 -> Req Filter1: 跨域检查不通过,返回错误
- 请求B -> 网关main线程 -> 网关worker1线程 -> Req Filter1: 跨域检查通过,继续请求 -> Req Filter2: 权限检查不通过,返回错误
- 请求C -> 网关main线程 -> 网关worker2线程 -> Req Filter1: 跨域检查通过,继续请求 -> Req Filter2: 权限检查通过,继续请求 -> 服务器A线程
Res Filter在每次请求执行之后运行,那么它能干什么呢?它可以配合Req Filter实现缓存处理。
比如每次请求回来以后放入缓存,每次请求之前判断缓存是否存在,有的话直接返回。
处理流程如下:
- 请求A -> 网关main线程 -> 网关worker1线程 -> Req Filter1: 判断缓存不存在,继续请求 -> 服务器A线程 -> Res Filter1: 请求成功,结果放到缓存
- 请求A -> 网关main线程 -> 网关worker1线程 -> Req Filter1: 判断缓存存在,获取缓存并返回。
开始代码改造,增加Req filter
public void handle(final FullHttpRequest fullRequest, final ChannelHandlerContext ctx, HttpRequestFilter filter) {
String backendUrl = this.backendUrls.get(0);
final String url = backendUrl + fullRequest.uri();
// Req filter 请求前执行
filter.filter(fullRequest, ctx);
proxyService.submit(()->fetchGet(fullRequest, ctx, url));
}
继续增加Res Filter
private void handleResponse(final FullHttpRequest fullRequest, final ChannelHandlerContext ctx, final HttpResponse endpointResponse) throws Exception {
FullHttpResponse response = null;
try {
byte[] body = EntityUtils.toByteArray(endpointResponse.getEntity());
response = new DefaultFullHttpResponse(HTTP_1_1, OK, Unpooled.wrappedBuffer(body));
response.headers().set("Content-Type", "application/json");
response.headers().setInt("Content-Length", Integer.parseInt(endpointResponse.getFirstHeader("Content-Length").getValue()));
// res filter 请求结束执行
filter.filter(response);
} catch (Exception e) {
e.printStackTrace();
response = new DefaultFullHttpResponse(HTTP_1_1, NO_CONTENT);
exceptionCaught(ctx, e);
} finally {
if (fullRequest != null) {
if (!HttpUtil.isKeepAlive(fullRequest)) {
ctx.write(response).addListener(ChannelFutureListener.CLOSE);
} else {
ctx.write(response);
}
}
ctx.flush();
}
}
Filter的具体实现,应该先有两个接口
- Req Filter
- Res Filter
在有具体的实现类,可以通过配置文件,配置使用不同的Filter。
比如实现一个权限检查的Req Filter
public class CacheRequestFilter implements HttpRequestFilter {
@Override
public void filter(FullHttpRequest fullRequest, ChannelHandlerContext ctx) {
// 获取token
String token = fullRequest.headers().get("token");
// 处理token
if (!jwt.check(token)) {
// 返回错误
byte[] body;
FullHttpResponse response = new DefaultFullHttpResponse(HttpResponseStatus.HTTP_1_1, HttpResponseStatus.FORBIDDEN, Unpooled.wrappedBuffer(body));
response.headers().set("Content-Type", "application/json");
response.headers().setInt("Content-Length", 0);
ctx.write(response);
ctx.flush();
}
}
}
负载均衡


负载均衡(Load Balancing)是一种计算机技术,用于在多个计算资源(如服务器、网络链路等)之间分配工作负载,以提高系统的整体性能、可靠性和可扩展性。
负载均衡的基本原理
- 资源分配:将用户的请求按照一定的算法和规则,均匀地分配到多个后端服务器上。这样可以避免单点服务器因承受过多请求而过载,同时充分利用所有可用服务器的资源。
- 健康检查:负载均衡器会定期检查后端服务器的健康状态。例如,通过发送心跳包或尝试建立连接等方式,来确定服务器是否正常运行。如果发现某台服务器出现故障,负载均衡器会自动停止将请求分配到该服务器,直到其恢复正常。
利用软件程序来实现负载均衡。软件负载均衡器可以安装在通用的服务器上,通过软件代码来处理请求的分发。这种方式相对硬件负载均衡成本较低,并且具有更好的灵活性,方便进行定制化和扩展。
看一下Nginx的实现吧。
Nginx:这是一个非常流行的开源软件负载均衡器。它可以作为反向代理服务器,将客户端请求转发到后端服务器。Nginx 支持多种负载均衡算法,如轮询(Round - Robin)、加权轮询(Weighted Round - Robin)、IP 哈希(IP - Hash)等。例如,在轮询算法中,Nginx 会按照顺序依次将请求分配到后端服务器列表中的每一台服务器上。假设后端有服务器 A、服务器 B 和服务器 C,第一个请求会被发送到服务器 A,第二个请求发送到服务器 B,第三个请求发送到服务器 C,然后再从服务器 A 开始循环。
负载均衡的优势
- 提高性能:通过将负载均匀分布在多个服务器上,可以充分利用服务器的资源,避免单点出现性能瓶颈。例如,在一个网站流量高峰期,如果只有一台服务器处理请求,可能会因为 CPU、内存或网络带宽等资源耗尽而导致响应速度变慢。而使用负载均衡将请求分散到多台服务器后,每台服务器处理的请求数量减少,响应时间可以得到有效缩短。
- 增强可靠性:当某一台后端服务器出现故障时,负载均衡器可以将请求自动切换到其他正常的服务器,从而保证服务的连续性。这对于需要高可用性的应用(如电子商务网站、金融服务等)至关重要。例如,一个在线购物网站,如果没有负载均衡和容错机制,当一台服务器宕机时,可能会导致部分用户无法访问商品信息或进行购物操作,而有了负载均衡后,即使一台服务器出现问题,其他服务器仍可以继续处理请求,用户可能只是感觉到短暂的延迟,而不会出现服务完全中断的情况。
- 便于扩展:随着业务的增长,可以方便地添加新的服务器到负载均衡池中,以应对不断增加的请求量。例如,一个新兴的互联网公司,其网站的用户访问量逐月增加。通过负载均衡,公司可以根据流量增长情况逐步添加服务器,而不需要对整个系统架构进行大规模的重新设计。负载均衡器可以自动将新添加的服务器纳入请求分配的范围,实现无缝的系统扩展。
在看一下实现负载均衡以后的网关架构吧。
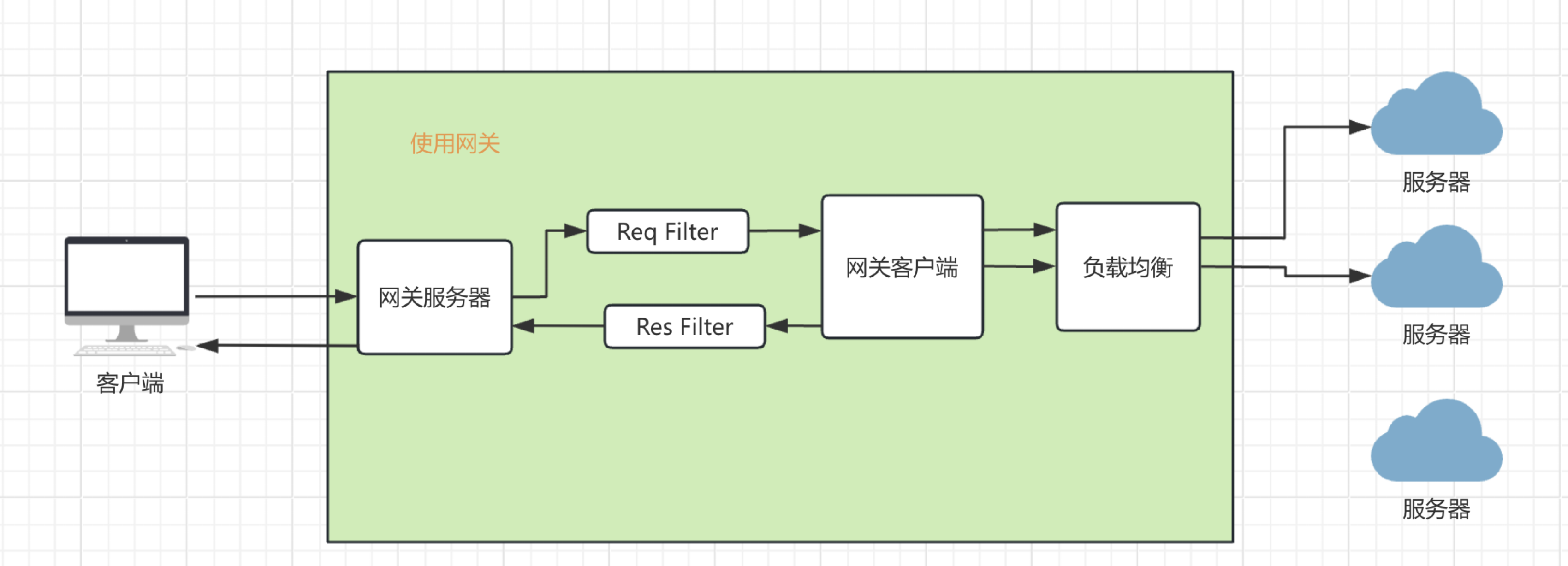
负载均衡的算法
那负载均衡具体是如何实现呢?看大头怎么说。

轮询算法

下面是轮询算法的时序图。
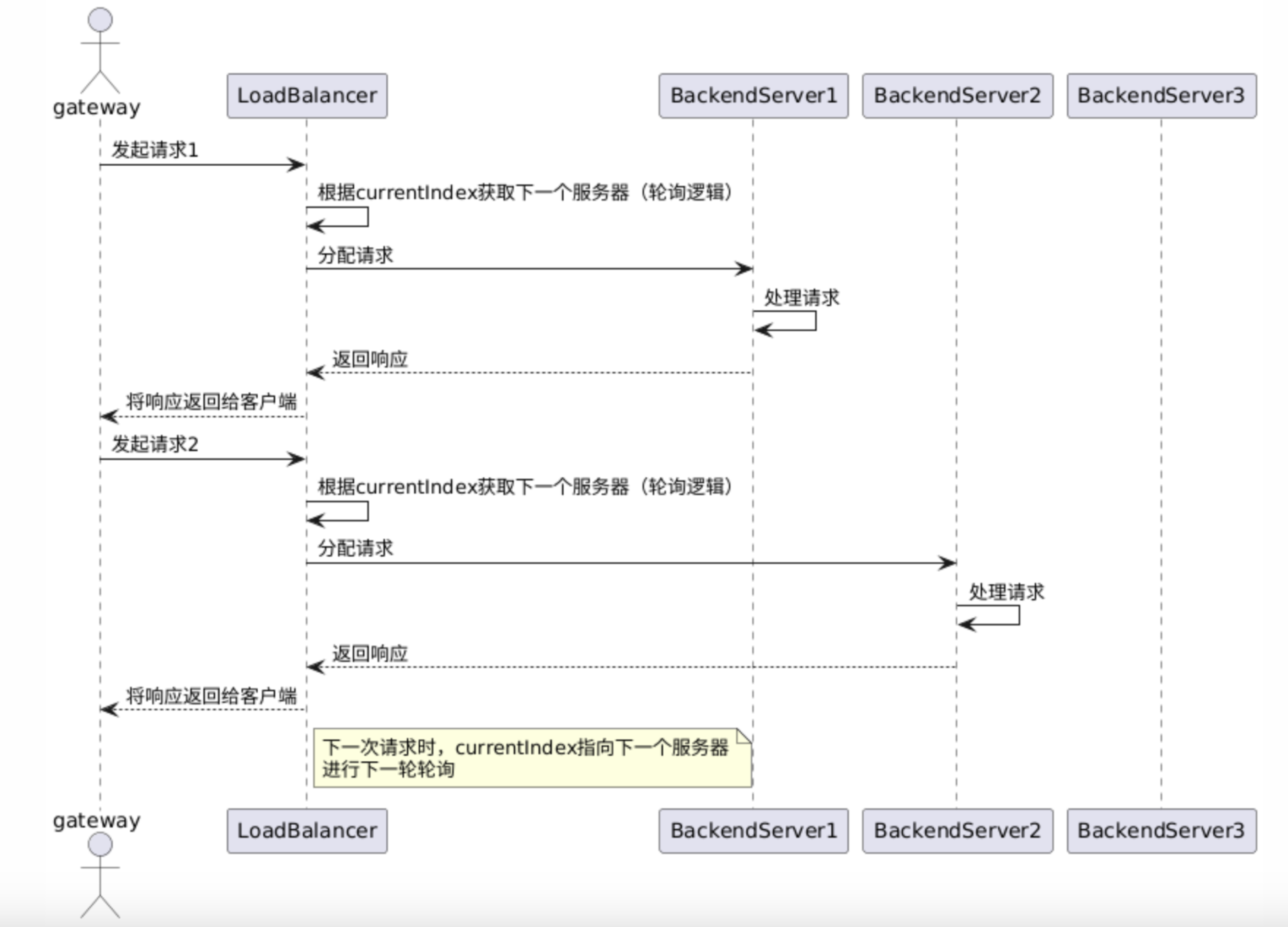
- 原理:按照顺序依次将请求分配到后端服务的各个实例上。例如,有三个后端服务实例 A、B、C,第一个请求被路由到 A,第二个请求路由到 B,第三个请求路由到 C,然后又从 A 开始循环分配。这种算法简单公平,能均匀地分配请求负载。
- 适用场景:适用于后端服务实例性能相近,处理能力相对均衡的情况。例如,多个相同配置的 Web 服务器提供相同的静态网页服务,使用轮询算法可以很好地平衡请求流量。
轮询的基本执行流程如下:
- 请求A -> 网关main线程 -> 网关worker1线程 -> 服务器1
- 请求B -> 网关main线程 -> 网关worker2线程 -> 服务器2
- 请求C -> 网关main线程 -> 网关worker2线程 -> 服务器3
- 请求D -> 网关main线程 -> 网关worker1线程 -> 服务器1
- 请求E -> 网关main线程 -> 网关worker2线程 -> 服务器2
- 请求F -> 网关main线程 -> 网关worker2线程 -> 服务器3
看一段代码
public class RoundRobinRouter implements HttpEndpointRouter {
private Integer current = 0;
@Override
public String route(List<String> urls) {
String url = urls.get(current);
current++;
current = current % urls.size();
return url;
}
}
加权轮询算法

下面是加权轮询算法的时序图。
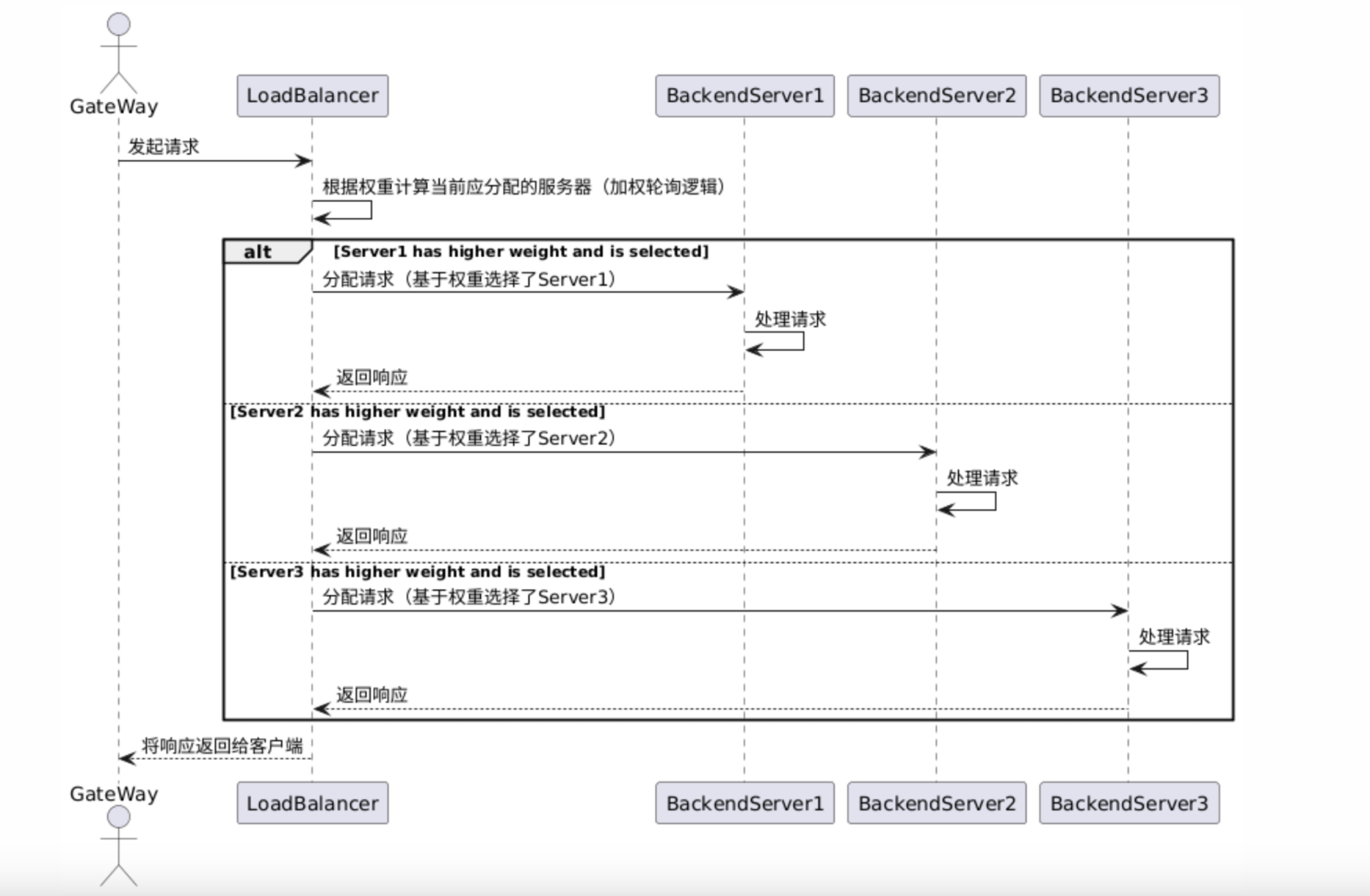
- 原理:为每个后端服务实例分配一个权重值,权重表示该实例相对处理能力的大小。在分配请求时,按照权重比例来分配。例如,服务实例 A 的权重为 5,服务实例 B 的权重为 3,服务实例 C 的权重为 2,那么在总共 10 次请求分配中,A 会被分配 5 次,B 会被分配 3 次,C 会被分配 2 次。
- 适用场景:当后端服务实例的性能不同,比如部分实例配置更高、处理能力更强时,通过加权轮询可以让性能强的实例处理更多的请求。例如,有新老两代服务器,新服务器性能是老服务器的两倍,就可以给新服务器分配更高的权重,让其承担更多的请求负载。
加设3个服务器权重是5,3,2.
加权轮询的基本执行流程如下:
- 请求A -> 网关main线程 -> 网关worker1线程 -> 服务器权重为5 3 2 因此选择服务器1 PS:当前服务器权重为-5 3 2
- 请求B -> 网关main线程 -> 网关worker2线程 -> 服务器权重为0 6 4 因此选择服务器2 PS:当前服务器权重为0 -4 4
- 请求C -> 网关main线程 -> 网关worker3线程 -> 服务器权重为5 -1 6 因此选择服务器3 PS:当前服务器权重为5 -1 -4
- 请求D -> 网关main线程 -> 网关worker4线程 -> 服务器权重为10 2 -2 因此选择服务器1 PS:当前服务器权重为0 2 -2
- 请求E -> 网关main线程 -> 网关worker1线程 -> 服务器权重为5 5 0 因此选择服务器1 PS:当前服务器权重为-5 5 0
- 请求F -> 网关main线程 -> 网关worker2线程 -> 服务器权重为0 8 2 因此选择服务器2 PS:当前服务器权重为0 -2 2
- 请求A -> 网关main线程 -> 网关worker3线程 -> 服务器权重为5 1 4 因此选择服务器1 PS:当前服务器权重为-5 1 4
- 请求B -> 网关main线程 -> 网关worker4线程 -> 服务器权重为0 4 6 因此选择服务器3 PS:当前服务器权重为0 4 -4
- 请求C -> 网关main线程 -> 网关worker1线程 -> 服务器权重为5 7 -2 因此选择服务器2 PS:当前服务器权重为5 -3 -2
- 请求D -> 网关main线程 -> 网关worker2线程 -> 服务器权重为10 0 0 因此选择服务器1 PS:当前服务器权重为0 0 0
可以看到上面10次请求结果,服务器1分配了5次请求,服务器2分配了3次请求,服务器3分配了2次请求。
看一段代码
public class WeightedRoundRobinRouter implements HttpEndpointRouter {
private Integer current = 0;
@Override
public String route(List<BackendServer> urls) {
int totalWeight = 0;
BackendServer selectedServer;
// 第一步:计算总权重,并更新每个服务器的当前权重
for (BackendServer server : urls) {
totalWeight += server.weight;
server.currentWeight += server.weight;
}
// 第二步:找出当前权重最大的服务器作为本次选择的服务器
for (BackendServer server : urls) {
if (server.currentWeight > selectedServer.currentWeight) {
selectedServer = server;
}
}
// 第三步:将选中的服务器的当前权重减去总权重,用于下一轮的权重计算和比较
selectedServer.currentWeight -= totalWeight;
return selectedServer.url;
}
}
哈希算法

下面是哈希算法的时序图。
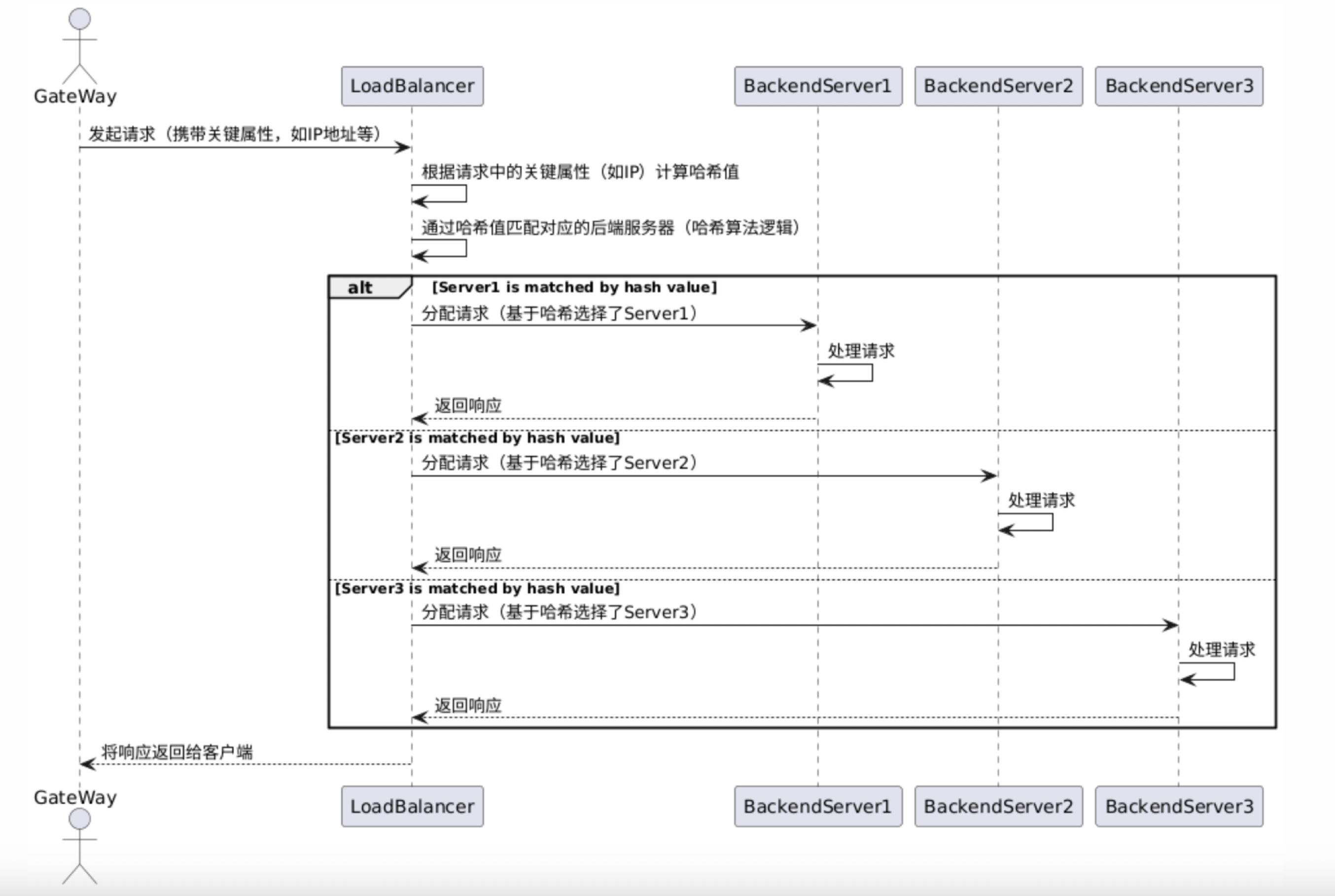
使用IP进行哈希算法
- 原理:根据请求客户端的 IP 地址计算一个哈希值,然后通过这个哈希值来确定将请求路由到后端服务的哪个实例。相同 IP 地址的请求会始终被路由到同一个后端实例,除非后端实例的数量发生变化。
- 适用场景:适用于需要保证特定客户端的请求始终由同一个后端实例处理的场景。例如,在一些有状态的服务中,如需要保持用户会话状态(如购物车信息等),通过 IP 哈希可以确保用户的每次请求都能路由到保存其会话状态的后端服务器。
哈希算法的基本执行流程如下:
- 请求A -> 网关main线程 -> 网关worker1线程 -> hash(ip) % 3 结果是0,因此选择服务器1
- 请求B -> 网关main线程 -> 网关worker2线程 -> hash(ip) % 3 结果是1,因此选择服务器2
- 请求C -> 网关main线程 -> 网关worker3线程 -> hash(ip) % 3 结果是2,因此选择服务器3
看一段代码
public class HashRouter implements HttpEndpointRouter {
private Integer current = 0;
@Override
public String route(List<String> urls, ip) {
int index = hash(ip) % urls.size();
return urls.get(index);
}
}
随机算法

随机算法的时序图,原理啥的就不放了,因为太简单了,就是取一个(0,2)开区间的一个随机数。是0就服务器1,1就服务器2,2就服务器3.
简单的代码实现。
public class RandomRouter implements HttpEndpointRouter {
@Override
public String route(List<String> urls) {
int size = urls.size();
Random random = new Random(System.currentTimeMillis());
return urls.get(random.nextInt(size));
}
}
接下来只要修改一下获取请求url的代码就可以了。改成从负载均衡获取请求的url,而不是固定取第一个。
public void handle(final FullHttpRequest fullRequest, final ChannelHandlerContext ctx, HttpRequestFilter filter) {
// 这里通过负载均衡的路由获取请求的url
String backendUrl = router.route(this.backendUrls);
final String url = backendUrl + fullRequest.uri();
// Req filter 请求前执行
filter.filter(fullRequest, ctx);
proxyService.submit(()->fetchGet(fullRequest, ctx, url));
}
健康检查
当实现这些以后,小白很高兴。

小白想知道当后端多个服务器,一个挂了怎么办呢?网关又不知道它挂了,把流量请求过去了,结果服务器挂了,那不就请求失败了吗?

我们可以通过健康检查机制来解决,添加Zookeeper作为健康检查机制,服务器向Zookeeper注册服务,如果服务器挂了那么Zookeeper就会知道。网关通过Zookeeper来获取现在的服务器列表,然后再通过负载均衡选择服务器。
一般最常用的就是心跳检测。
什么是心跳检测呢?
就是每隔一段时间,发送一个请求,看是否正常返回,如果是,那么服务器就正常,如果不是,比如超时之类的就认为服务器挂了,那么接下来的请求流量就不分给这个服务器了,从服务器列表中移除,啥时候发送心跳检测,发现服务器正常返回了,那么就再放到服务器列表中。
也可以直接通过Zookeeper这种额外的组件来实现。服务器跟Zookeeper通信,服务器列表通过Zookeeper获取。
具体的时序图如下。

健康检查的代码就不放了,就当作作业了哈哈,有兴趣的小伙伴可以自己实现一个放到评论区哦~
总结
小白又自己实现了一个网关程序,可以开心的回去交差啦。

一个基本的单体网关就实现完成了。
其实还有一些其他的问题,比如网关挂了怎么办?那么可以部署多个网关节点,组成集群。
那么集群的话就需要引入Raft这种分布式共识协议来进行leader节点选择,信息同步。
那么多个网关节点的元信息放在哪里呢?当然也可以放在Zookeeper里面啦~
更多知识下期介绍~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









