




 博客介绍了dot与*矩阵乘法的区别,a*b是对应元素相乘,a.dot(b)是矩阵乘法。还阐述了模型预测中的损失函数,介绍了ReLU、sigmoid、tanh三种激活函数及其导数。此外,讲解了文本预处理步骤,以及基于统计的语言模型,如n元语法。
博客介绍了dot与*矩阵乘法的区别,a*b是对应元素相乘,a.dot(b)是矩阵乘法。还阐述了模型预测中的损失函数,介绍了ReLU、sigmoid、tanh三种激活函数及其导数。此外,讲解了文本预处理步骤,以及基于统计的语言模型,如n元语法。
## 数据操作
```python
from mxnet import nd
x = nd.arange(12) #创建行向量
x.shape # 实例的规格
x.size # 实例的大小
x.reshape(3,4) # 重新安排x的规格大小
dot与*的矩阵乘法的区别
a*b 意味着 a中元素与b中对应元素相乘,即ai,j * bi,j
a.dot(b) 指的是矩阵a与矩阵b的乘法。同时值得注意的是:a.dot(b)与b.dot(a)不同。
行连接,列连接
nd.concat(x,y,dim=0) #扩展行的数量
nd.concat(x,y,dim=1) #扩展列的数量
模型预测
损失函数
用 训练集中所有的样本误差的平均来衡量预测模型的质量即
l(w1,w2,b) = 1/2(y(i)预测-y(i)真实)2
尽量是用矢量计算,矢量比标量运算速度快,计算效率强
激活函数
ReLU函数
ReLU(x)=max(x,0)ReLU(x)=max(x,0)ReLU(x)=max(x,0) 简单的非线性变换。给定元素xxx,ReLUReLUReLU只保留正数元素,并将负数元素清零
def ReLU(X):
return nd.maximum(X,0)
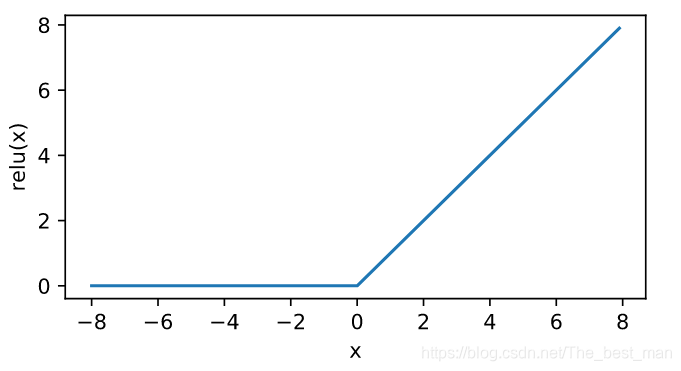
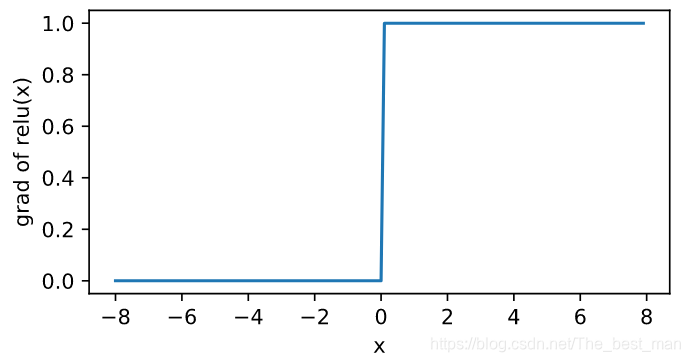
ReLU函数方便求导,当输入是负数的时候,ReLU的导数为00;当输入为正数的时候ReLU的导数为1
xyplot(x,x.grad,'grad of relu')
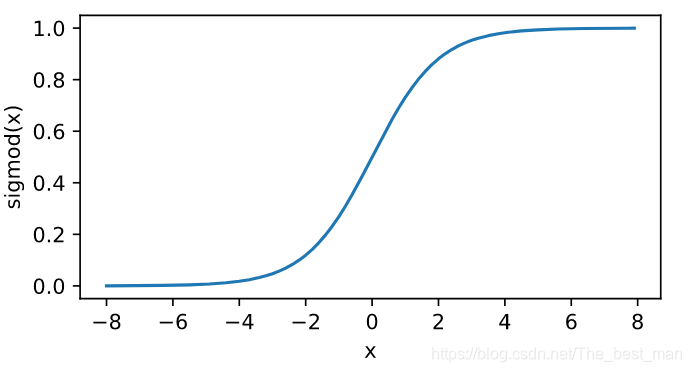
sigmoid函数
sigmodsigmodsigmod函数将元素变换到0和1之间: sigmod=11+exp(−x)sigmod= \frac{1}{1+exp(-x)}sigmod=1+exp(−x)1
def sigmoid(X):
return 1/(1+nd.exp(-X))
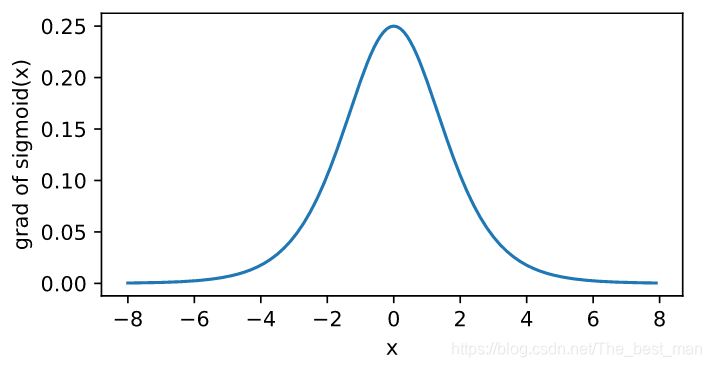
sigmoidsigmoidsigmoid函数的导数sigmoid(x)′=sigmoid(x)(1−sigmoid(x))sigmoid(x)^{'}=sigmoid(x)(1-sigmoid(x))sigmoid(x)′=sigmoid(x)(1−sigmoid(x)),当输入越偏离0,sigmoid的导数越接近0
tanh函数
将元素的值变换到-1和+1之间:
tanh(x)=1−exp(−2x)1+exp(−2x)tanh(x)=\frac{1-exp(-2x)}{1+exp(-2x)}tanh(x)=1+exp(−2x)1−exp(−2x)
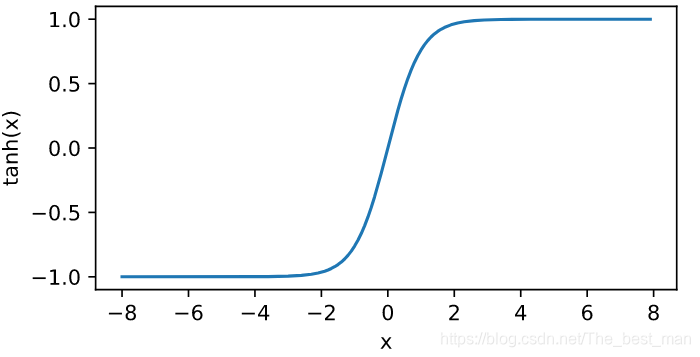
根据链式求导法则,tanhtanhtanh函数的导数是
tanh′(x)=1−tanh2(x)tanh^{'}(x)=1-tanh^{2}(x)tanh′(x)=1−tanh2(x)
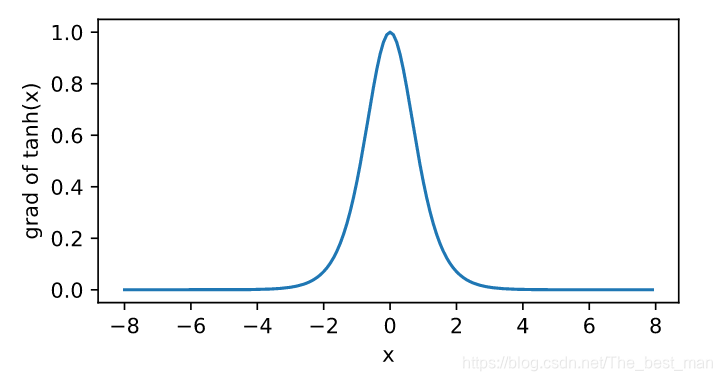
绘制对应函数的图像
def xyplot(x_vals,y_vals,name):
d2l.set_figsize(figsize=(5,2.5))
d2l.plt.plot(x_vals.asnumpy(),y_vals.asnumpy())
d2l.plt.xlabel('x')
d2l.plt.ylabel(name+'(x)')
文本预处理
- 读入文本
- 分词
- 建立字典,每个词映射一个字典
- 将文本从词的序列转化为索引的序列
import collections
import re
def read_time_machine():
with open('/home/kesci/input/timemachine7163/timemachine.txt','r') as f:
# f.read()进行文本读取可以输出
lines = [re.sub('[^a-z]+',' ',line.strip().lower()) for line in f]
return lines
lines =read_time_machine()
print('# sentences %d' % len(lines))
将文本进行分割成单词
原方法
def tokenize(sentences, token='word'):
"""Split sentences into word or char tokens"""
# 将句子切分成单词或者char字符
# 分割成 单词 Word
if token == 'word':
return [sentence.split(' ') for sentence in sentences]
elif token == 'char':
return [list(sentence) for sentence in sentences]
else:
print('ERROR: unknow toke type '+ token)
tokens = tokenize(lines)
# 执行默认的进行分割word单词
tokens[0:2]
等价的方法
def tokenize(sentences, token='word'):
"""Split sentences into word or char tokens"""
# 将句子切分成单词或者char字符
# 分割成 单词 Word
if token == 'word':
li = [] # 创建一个空白的list
for sentence in sentences:
li.append(sentence.split(' '))
return li
elif token == 'char':
return [list(sentence) for sentence in sentences]
else:
print('ERROR: unknow toke type '+ token)
tokens = tokenize(lines)
# 执行默认的进行分割word单词
tokens[0:2]
对于return部分的内容
return [sentence.split(' ') for sentence in sentences:]
最后需要return 一个list的数据,将每个句子中的元素按照空格进行分割,所以按照顺序的逻辑代码如下:
li = [] # 构建一个空的list
for sentence in sentences:
li.append(sentence.split(' '))
# 所有的句子分割完毕之后
return li
语言模型
一段自然语言文本可以看作是一个离散时间序列,给定一个长度为TTT的词的序列w1,w2,…,wTw_1, w_2, \ldots, w_Tw1,w2,…,wT,语言模型的目标就是评估该序列是否合理,即计算该序列的概率:
P(w1,w2,…,wT). P(w_1, w_2, \ldots, w_T). P(w1,w2,…,wT).
本节我们介绍基于统计的语言模型,主要是nnn元语法(nnn-gram)。在后续内容中,我们将会介绍基于神经网络的语言模型。
语言模型
假设序列w1,w2,…,wTw_1, w_2, \ldots, w_Tw1,w2,…,wT中的每个词是依次生成的,我们有
KaTeX parse error: No such environment: align* at position 8:
\begin{̲a̲l̲i̲g̲n̲*̲}̲P(w_1, w_2, \ld…
例如,一段含有4个词的文本序列的概率
P(w1,w2,w3,w4)=P(w1)P(w2∣w1)P(w3∣w1,w2)P(w4∣w1,w2,w3).P(w_1, w_2, w_3, w_4) = P(w_1) P(w_2 \mid w_1) P(w_3 \mid w_1, w_2) P(w_4 \mid w_1, w_2, w_3).P(w1,w2,w3,w4)=P(w1)P(w2∣w1)P(w3∣w1,w2)P(w4∣w1,w2,w3).
语言模型的参数就是词的概率以及给定前几个词情况下的条件概率。设训练数据集为一个大型文本语料库,如维基百科的所有条目,词的概率可以通过该词在训练数据集中的相对词频来计算,例如,w1w_1w1的概率可以计算为:
P^(w1)=n(w1)n\hat P(w_1) = \frac{n(w_1)}{n}P^(w1)=nn(w1)
其中n(w1)n(w_1)n(w1)为语料库中以w1w_1w1作为第一个词的文本的数量,nnn为语料库中文本的总数量。
类似的,给定w1w_1w1情况下,w2w_2w2的条件概率可以计算为:
P^(w2∣w1)=n(w1,w2)n(w1)\hat P(w_2 \mid w_1) = \frac{n(w_1, w_2)}{n(w_1)} P^(w2∣w1)=n(w1)n(w1,w2)
其中n(w1,w2)n(w_1, w_2)n(w1,w2)为语料库中以w1w_1w1作为第一个词,w2w_2w2作为第二个词的文本的数量。
# 定义 load_data_jay_lyrics
def load_data_jay_lyrics():
with open('/home/kesci/input/jaychou_lyrics4703/jaychou_lyrics.txt') as f:
corpus_chars = f.read()
corpus_chars = corpus_chars.replace('\n',' ').replace('\r',' ')
corpus_chars = corpus_chars[0:10000]
idx_to_char = list(set(corpus_chars)) #去重复, 索引到字符的映射
char_to_idx = dict([(char,i) for i,char in enumerate(idx_to_char)]) # 构建 字符到索引的应映射
vocab_size = len(char_to_idx)
corpus_indices = [char_to_idx[char] for char in corpus_chars]
return corpus_indices,char_to_idx,idx_to_char,vocab_size

















 1489
1489

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









