



背景
在公司内部牵头AI应用场景的落地,需要用到OCR、ASR、视频切片和AGENT等相关技术。后来选型用了百度飞桨(Paddle)。一开始是看Paddle的库足够丰富,有用来处理自然语言的PaddleNLP,做OCR的PaddleOCR,以及处理Speech2Text,Text2Speesh等语音文字处理的PaddleSpeech等。结果没想到落地过程中困难重重(主要是官方文档指引不清晰+各种版本冲突),遂记录一下落地过程中的一些坑。
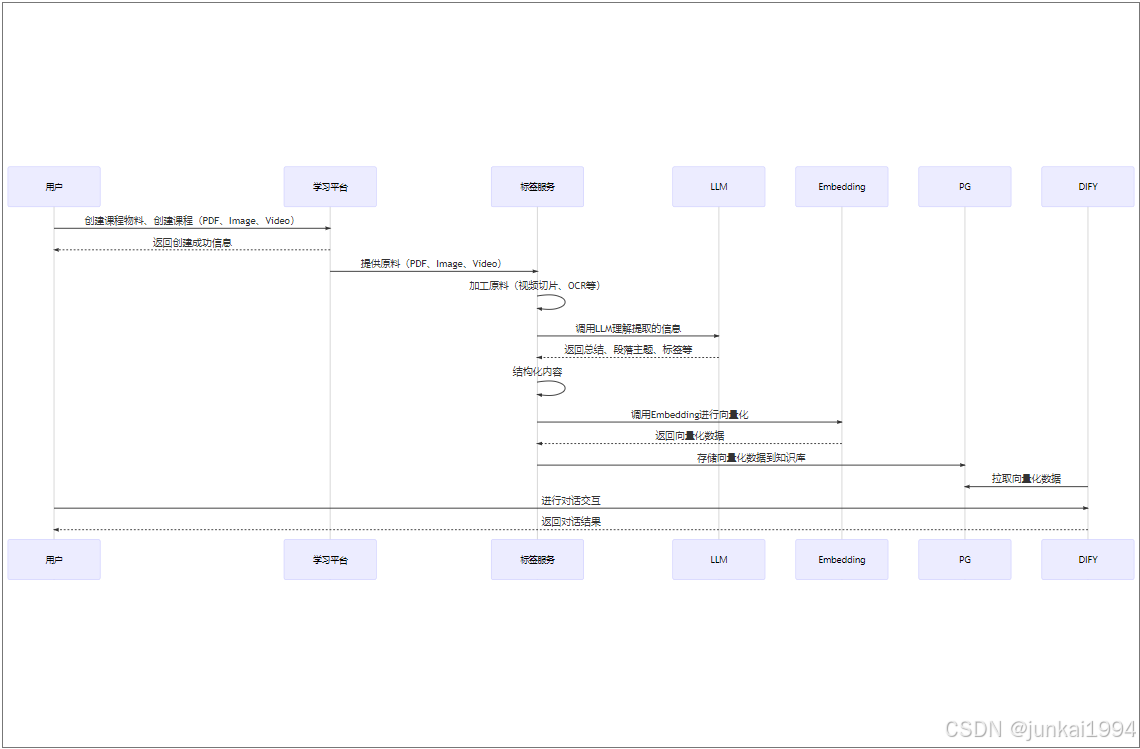
以下是我们公司内部落地AI应用的交互时序图:
声明
强烈不建议使用源码编译或者pip等方式安装paddlespeech!!
强烈不建议使用源码编译或者pip等方式安装paddlespeech!!
强烈不建议使用源码编译或者pip等方式安装paddlespeech!!
原因就是官方缺少明确的PaddlePaddle和PaddleSpeech对应的兼容版本说明!这使得最新版本的PaddleSpeech最多只能兼容到Paddle的2.6.x的版本!!而在我的项目当中,如果使用Paddle2.6.X版本,就会和AutoGen所依赖的Protubuf版本产生冲突!这问题是无解的!
建议的替代方案:将PaddleSpeech单独部署成一个服务,使用官方已经集成好的PaddleSpeech镜像!!镜像地址PaddleSpeech官方镜像
拉取PaddleSpeech镜像
# CPU版本
docker pull paddlecloud/paddlespeech:develop-cpu-fb4d25
# GPU版本
docker pull paddlecloud/paddlespeech:develop-gpu-cuda10.2-cudnn7-fb4d25
注意GPU版本需要注意主机的CUDA的版本,否则会不兼容!
注意
PaddleSpeech的镜像只是给你装好了所需环境和依赖,并没有启动PaddleSpeech Server!!!! 若要启动Server,还需要进入容器内部执行命令:
# 进入paddlespeech目录
cd paddlespeech
# 启动服务!!!
paddlespeech_server start --config_file ./server/conf/application.yaml
然后你就会看到服务启动成功,默认端口是8090:

把这个端口映射出去,就可以访问服务了!!
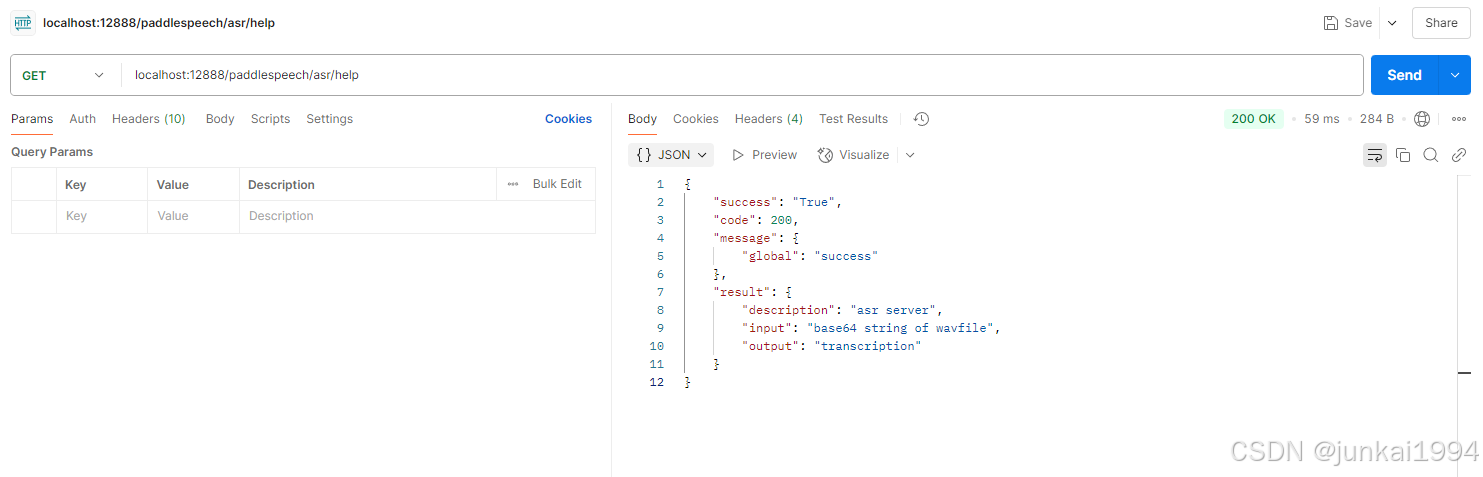
另附上PaddleSpeech Server的API
PaddleSpeech Server Restful API
PaddleSpeech Server Streaming API

















 4741
4741

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









