




 本文深入解析了一种高性能RPC框架的设计与实现,涵盖RPC结构、协议、序列化、代理及通信传输关键环节。对比JSF框架,该RPC框架在本机测试中展现出4~5倍的TPS性能提升。
本文深入解析了一种高性能RPC框架的设计与实现,涵盖RPC结构、协议、序列化、代理及通信传输关键环节。对比JSF框架,该RPC框架在本机测试中展现出4~5倍的TPS性能提升。
1. RPC 结构拆解
最近造了个轮子RPC框架,核心功能更还算完善,但是性能还不错的。本机测试是TPS是JSF的4~5倍。
下面开始介绍。代码在文章末尾。
RPC主要流程如下图:
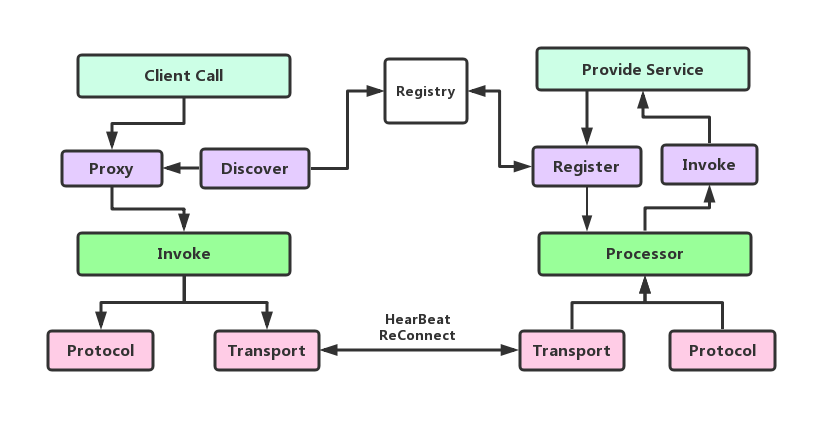
- RPC 服务提供者通过 Service Register 发布到注册中心,同时暴露在本地。消费者通过Service Register拉去服务的列表,并且保存至本地缓存。
- 客户方像调用本地方法一样去调用远程接口方法,RPC 框架提供接口的代理实现,实际的调用将委托给代理Proxy 。
- 代理封装调用信息并将调用转交给 Invoker 去实际执行。在客户端的Invoker 通过 Protocol 对调用信息编码协议消息,通过传输模块传送至服务提供方。
- RPC 服务端接收器接收客户端的调用请求,同样使用 Protocol 执行协议解码。解码后的调用信息传递给 Processor去控制处理调用过程,最后再委托调用给 Invoker 去实际执行并返回调用结果。
2. 协议
传输协议主要是为了解决粘包拆包问题,以及序列化的方式、工具的版本等问题。
/**
* ┌ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ┐
* 2 │ 1 │ 1 │ 4 │
* ├ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ── ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ┤
* │ │ │ │
* │ MAGIC sType mType Body Size Body Content │
* │ │ │ │
* └ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ── ─ ─ ─ ─ ─ ─ ─ ─ ┘
*/
3. 序列化
一般的序列化工具只能将对象序列化入byte数组或者原生ByteBuf中,但是这不利于基于Netty传输,因此我们借鉴ByteBufInputStream,
直接让FastJson/kryo将数据通过自定义的InputStream写入ByteBuf。并且通过ThreadLocal将自定义的InputStream可以复用。
请求消息和响应消息的序列化中,消息头是公共用的,消息体不同。在JSF(我司内部的RPC框架)中,request消息体的定义为:
private String clazzName;
private String methodName;
private String[] argsType;
private transient Class[] argClasses;
private Object[] args;
其中在methodName和argsType可以优化为一个byte类型的数字,即methodId,服务端根据接口中默认的方法顺序,生成Invoer数组,是每一个方法生成一个Invoker的实例。我们在服务端也是用的是Javassit的调用,基于Java或者CGlib的反射调用性能实在是太慢了。
还有一点就是关于消息体的序列化,将整个个消息体序列至ByteBuf中和手工的写入ByteBuf的性能接近相差三倍。
以Request为例:
public ByteBuf toByteBuf(ByteBuf buf) {
buf.writeShort(agg);
buf.writeByte(mType);
buf.writeByte(sType);
int index = buf.writerIndex();
buf.writeInt(1);
int start = buf.writerIndex();
toByteBufImpl(buf);
int length = buf.writerIndex() - start;
buf.setInt(index, length);
return buf;
}
@Override
protected void toByteBufImpl(ByteBuf byteBuf) {
byteBuf.writeLong(requestId);
byteBuf.writeLong(timestamp);
byte[] bytes = serviceName.getBytes();
byteBuf.writeByte(bytes.length);
byteBuf.writeBytes(bytes);
byteBuf.writeByte(methodIndex);
serialize.objectToByteBuf(args, byteBuf);
}
4. Client代理
如何做到对一个接口的调用?显然通过代理的方式,然而在Java中存在多种可以实现代理的方式,JDK提供的动态代理,CGlib动态代理,以及Javassist实现代理。
鉴于调用性能的考虑,默认采用的是使用Javassist的代理方式。说白了其实就是在内存中构建出了实现接口的实现类,在实现类中调用了ProxyInvoke的invoke方法。
参考了Dubbo的方式,对Invoke进行增加了InvokeChain,在InvokeChain中对调用增加逻辑上的处理。比如数据的统计,流量控制等。
invoke方法如下:
public Object invoke(String serviceName, Object[] params,int methodId) throws NoAliveProviderException {
// recycle
Request request = MessageUtil.getRequest();
request.setServiceName(serviceName)
.setArgs(params)
.setMethodIndex((byte)methodId);
return filterChain.invoke(request, loadBalance.next())
}
methodId是在Javassist生成代理类的时已经写入到它的实例对象中了。
关于异步:提供服务的借口必须以CompleteableFuture为返回值,所有的RPC调用都是异步的。当上面的invoke方法执行完毕,其实是在本地JVM中构建
了一个CompleteableFuture对象,别且将它置入等待池子中,如果收到响应消息,则将它从池子中移除,并且将CompleteableFuture置为完成。
这里有一个计划线程,如果某一个Future超时,则提前将它以异常结束。
5. 通信传输
关于通信不必多言,Netty已成为Java通信领域的首选框架。
不足
Robin load balance中的AtomicInteger 可以有跟好的解决方式(已升级为FastLong)
RequestId需求是每次获取的int只需要唯一即可,不需要递增。(已升级为FastLong)
invokeFuturepool的处理可以使用队列异步处理,当数量太多会影响IO线程的的效率
高效的bytebuf写入方式,参考Protocol Buffer Varint
batch send 批量的发送消息
server 超时控制 服务端的服务的时间控制。
Channel的个数,目前client和server端只有一条连接,但是这不是最优(更改为4,轮训使用)


















 995
995

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









