







 本文介绍Netty中的编解码原理及其处理粘包、拆包的方法。详细探讨了ByteToMessageDecoder、ReplayingDecoder、MessageToMessageDecoder等解码器以及MessageToByteEncoder的使用。同时,通过实例演示如何自定义协议解决粘包问题。
本文介绍Netty中的编解码原理及其处理粘包、拆包的方法。详细探讨了ByteToMessageDecoder、ReplayingDecoder、MessageToMessageDecoder等解码器以及MessageToByteEncoder的使用。同时,通过实例演示如何自定义协议解决粘包问题。
文章目录
1. Is What?
编码器操作出站数据,而解码器处理入站数据。在网络中数据以字节流的格式传输。编码器和解码器就是将消息装换为字节格式或者将字节格式数据转换为消息格式。消息格式可能是字符、对象等。
将数据由原本的形式转换为字节流的操作称为编码(encode),将数据由字节转换为它原本的格式或是其他格式的操作称为解码(decode),编码统一称为codec。
- 编码:本质上是一种出栈处理器;因此,编码一定是一种ChannelOutboundHandler。
- 解码:本质上是一种入栈处理器,因此。解码一定是一种ChannelInboundHandler。
2. 解码器
解码器是负责将入站数据从一种格式转换到另一种格式,所以可以理解解码器实现了ChannelInboundHandler。
Netty中常见的解码器有
ByteToMessageDecoderReplayingDecoderMessageToMessageDecoder
既然解码器实现了ChannelInboundHandler,那么它也是一个handler,说白它也是在ChannelPipeline中。
2.1 ByteToMessageDecoder
抽象类ByteToMessageDecoder将字节解码为消息,若要实现解码器,需要实现该抽象类。
public abstract class ByteToMessageDecoder extends ChannelInboundHandlerAdapter
比较常用的方法:
protected abstract void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception;
protected void decodeLast(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
if (in.isReadable()) {
decodeRemovalReentryProtection(ctx, in, out);
}
}
decode():这是你必须实现的唯一抽象方法。decode()方法被调用时将会传入一个包含了传入数据的 ByteBuf,以及一个用来添加解码消息的 List。对这个方法的调用将会重复进行,直到确定没有新的元 素被添加到该 List,或者该 ByteBuf 中没有更多可读取的字节时为止。然后,如果该 List 不为空,那么它的内容将会被传递给ChannelPipeline 中的下一个 ChannelInboundHandler
decodeLast():Netty提供的这个默认实现只是简单地调用了decode()方法。当Channel的状态变为非活动时,这个方法将会被调用一次。可以重写该方法以提供特殊的处理
举个例子:
如果要解码一个包含一个int的字节流,每次从入站 ByteBuf 中读取 4 字节,将其解码为一个 int,然后将它添加到一个 List 中。当没有更多的元素可以被添加到该 List 中时,它的内容将会被发送给下一个ChannelInboundHandler。为了实现这个解码需要继ByteToMessageDecoder。
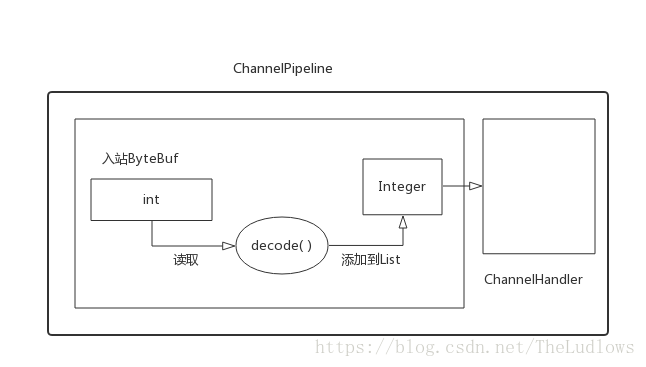
public class MyDecoder extends ByteToMessageDecoder {
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
if(in.readableBytes() >= 4) {
Integer n = in.readInt();
//从入站 ByteBuf 中读取一个 int,并将其添加到解码消息的 List 中
out.add(n);
}
}
}
虽然ByteToMessageDecoder使得可以很简单地完成解码的功能,但是每次都要判断一下是否有足够的数据。显得有些繁琐。ReplayingDecoder扩展了ByteToMessageDecoder类。
public abstract class ReplayingDecoder<S> extends ByteToMessageDecoder
它的使用方法很简单,和上面代码一样,只是不用判断而已。如果没有足够的字节可用,这
个readInt()方法的实现将会抛出一个Error。其将在基类中被捕获并处理。当有更多的数据可
供读取时,该decode()方法将会被再次调用。
2.2 其他解码器
io.netty.handler.codec.LineBasedFrameDecoder—这个类在 Netty 内部也有使
用,它使用了行尾控制字符(\n 或者\r\n)来解析消息数据;io.netty.handler.codec.http.HttpObjectDecoder—一个 HTTP 数据的解码器。
MessageToMessageDecoder
抽象类MessageToMessageDecoder对于两个消息格式之间进行转换,比如对象和对象之间转换可以用MessageToMessageDecoder解码器搞定。
public abstract class MessageToMessageDecoder<I> extends ChannelInboundHandlerAdapter
类型参数 I 指定了 decode()方法的输入参数 msg 的类型
public class MyM2MDecoder extends MessageToMessageDecoder {
@Override
protected void decode(ChannelHandlerContext ctx, Object msg, List out) throws Exception {
out.add(String.valueOf(msg));
}
}
TooLongFrameException
有这么一种情况解码器缓冲大量的数据以至于耗尽可用的内存,为了解除这个常见的顾虑可以用
TooLongFrameException解决。
public class MyDecoder extends ByteToMessageDecoder {
private static final int MAX_FRAME_SIZE = 1024;
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
int readable = in.readableBytes();
if( readable >= MAX_FRAME_SIZE) {
//跳过所有的可读字节,抛出TooLongFrameException并通知ChannelHandler
in.skipBytes(readable);
throw new TooLongFrameException("too long");
}
}
}
异常随后会被 ChannelHandler.exceptionCaught()方法捕获,如何处理该异常则完全取决于我们如何处理。如HTTP可能允许我们返回一个特殊的响应。
3. 编码器
编码器实现了ChannelOutboundHandler,并将出站数据从一种格式转换为另一种格式,和我们方才学习的解码器的功能正好相反。Netty 提供了一组类,用于帮助你编写具有以下功能的编码器:
- 将消息编码为字节
- 将消息编码为消息
3.1 MessageToByteEncoder
该抽象类用来将消息编码为字节。我们看下它的解码方法。
protected abstract void encode(ChannelHandlerContext ctx, I msg, ByteBuf out) throws Exception;
encode()方法是需要实现的唯一抽象方法。它被调用时将会传入要被该类编码为ByteBuf的(类型为 I 的)出站消息。该 ByteBuf 随后将会被转发给ChannelPipeline中的下一个 ChannelOutboundHandler。
这个类只有一个方法,而解码器有两个。原因是解码器通常需要在Channel 关闭之后产生最后一个消息(因此也就有了 decodeLast()方法)。这显然不适用于编码器的场景——在连接被关闭之后仍然产生一个消息是毫无意义的。
public class MyEncoder extends MessageToByteEncoder<Integer>{
@Override
protected void encode(ChannelHandlerContext ctx, Integer msg, ByteBuf out) throws Exception {
//将Integer写入ByteBuf中
out.writeInt(msg);
}
}
抽象类 MessageToMessageEncoder
public class MyM2MEncoder extends MessageToMessageEncoder<Integer> {
@Override
protected void encode(ChannelHandlerContext ctx, Integer msg, List<Object> out) throws Exception {
//将 Integer 转换为 String,并将其添加到 List 中
out.add(String.valueOf(msg));
}
}
4. 粘包/拆包
4.1 从TCP/UDP协议说起
保护消息边界和面向流
保护消息边界,就是指传输协议把数据当作一条独立的消息在网上 传输,接收端只能接收独立的消息.也就是说存在保护消息边界,接收 端一次只能接收发送端发出的一个数据包.
面向流则是指无保护消息保护边界的,如果发送端连续发送数据, 接收端有可能在一次接收动作中,会接收两个或者更多的数据包.
TCP为了保证可靠传输,尽量减少额外开销(每次发包都要验证),因此采用了流式传输,面向流的传输,
发送端为了将多个发往接收端的包,更有效的发到对方,使用了优化方法(Nagle算法),将多次间隔较小且数据量小的数据,合并成一个大的数据块,然后进行封包。对接收端的程序来讲,如果机器负荷很重,也会在接收缓冲里粘包。就需要接收端额外拆包
UDP,由于面向的是消息传输,它把所有接收到的消息都挂接到缓冲区的接受队列中,采用了链式结构来记录每一个到达的UDP包,因此它对于数据的提取分离就更加方便。
所谓的粘包拆包一定是基于发生于TCP协议
以下几种情况容易发生粘包/拆包:
- 要发送的数据大于TCP发送缓冲区剩余空间大小,将会发生拆包。
- 待发送数据大于MSS(最大报文长度),TCP在传输前将进行拆包。
- 要发送的数据小于TCP发送缓冲区的大小,TCP将多次写入缓冲区的数据一次发送出去,将会发生粘包。
- 接收数据端的应用层没有及时读取接收缓冲区中的数据,将发生粘包。
4.2 复现粘包情况
看下面代码及结果:
// clietn
public void channelActive(ChannelHandlerContext ctx) {
ctx.writeAndFlush(Unpooled.copiedBuffer("Netty 1 ", CharsetUtil.UTF_8));
ctx.writeAndFlush(Unpooled.copiedBuffer("Netty 2 ", CharsetUtil.UTF_8));
ctx.writeAndFlush(Unpooled.copiedBuffer("Netty 3 ", CharsetUtil.UTF_8));
}
// server
public void channelRead(ChannelHandlerContext ctx, Object o) {
ByteBuf in = (ByteBuf) o;
System.out.println("Server Receive:" + in.toString(CharsetUtil.UTF_8));
}
/* 结果:
* Server Receive:Netty 1 Netty 2 Netty 3
*/
预期应该是服务端处理三次,打印三行。这种情况就是上面列举的3,并且没有做拆包处理。
4.3 如何解决
1. 发定长数据
接收方拿固定长度的数据,发送方发送固定长度的数据即可。但是这样的缺点也是显而易见的:如果发送方的数据长度不足,需要补位,浪费空间。
2. 在包尾部增加特殊字符进行分割
发送方发送数据时,增加特殊字符;在接收方以特殊字符为准进行分割
3. 自定义协议
类似于HTTP协议中的HEAD信息,比如我们也可以在HEAD中,告诉接收方数据的元信息(数据类型、数据长度等)
很显然,Netty对这前两种方式都有实现。分别是FixedLengthFrameDecoder、DelimiterBasedFrameDecoder,它们都继承自ByteToMessageDecoder,使用很简单,此处不再介绍。第三种方式需要通过根据具体的逻辑自己实现,当然也需要继承ByteToMessageDecoder。当然Netty提供了HTTP协议的Head和Body类供我们使用。下面我们自己定义一种Message格式
// 省略构造方法、set/get
public class Message {
int version;
int length;
String content;
}
下面看编码和解码器的实现方法:
@Override
protected void encode(ChannelHandlerContext ctx, Object msg, ByteBuf out) throws Exception {
Message message = (Message)msg;
out.writeInt(message.getVersion());
out.writeInt(message.getLength());
out.writeBytes(message.getContent().getBytes(Charset.forName("UTF-8")));
}
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
int version = in.readInt();
int length = in.readInt();
byte[] contentArr = new byte[length];
in.readBytes(contentArr);
String content = new String(contentArr, Charset.forName("UTF-8"));
out.add(new Message(version, length, content));
}
只需将编码器和解码器添加至server/client的pipeline中。注意:client端编码器需要加在业务hanler前面,server端编码器也要加在业务handler前面。具体原因见 https://blog.youkuaiyun.com/TheLudlows/article/details/83997280

















 171
171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









