



 本文详细介绍了红黑树的规则及其添加元素的恢复策略。深入解析了HashSet的特性,包括无序性、唯一性,并探讨了JDK7和JDK8底层实现的区别,强调了hashCode和equals方法在保证元素唯一性中的作用。同时,概述了Map集合的基本使用、遍历方法,重点阐述了HashMap和TreeMap的底层原理,揭示了它们与HashSet的关联及排序特性。
本文详细介绍了红黑树的规则及其添加元素的恢复策略。深入解析了HashSet的特性,包括无序性、唯一性,并探讨了JDK7和JDK8底层实现的区别,强调了hashCode和equals方法在保证元素唯一性中的作用。同时,概述了Map集合的基本使用、遍历方法,重点阐述了HashMap和TreeMap的底层原理,揭示了它们与HashSet的关联及排序特性。
红黑树
红黑树规则:
1.每一个节点都是红色或者黑色
2.如果一个节点没有子节点,就称为叶子节点(Null),叶子节点都是黑色
3.根节点是黑色
4.对于一个红色节点,他的子节点都是黑色
5.对任意的节点,到其叶子节点的简单路径,包含相同的黑色节点数目
红黑树添加元素:元素默认都是红色
如果添加元素破坏了红黑规则,可以如何恢复红黑规则?

HashSet
HashSet是属于Set集合的子类
HashSet集合的特点
1.元素没有顺序
2.元素不能重复(有条件的)
3.元素没有索引
HashSet集合的便利方式
1.迭代器遍历
2.增强for遍历
HashSet的底层原理
HashSet集合底层是哈希表结构,要理解哈希表首先得理解什么是哈希值。
什么是哈希值?
每一个对象都有哈希值,它是通过对象的地址算出来的一个int类型的值
如何获取哈希值?
在Object类中有一个方法叫hashCode(),通过这个方法可以获得哈希值
--同一个对象的hashCode值是一样的
--不同对象的hashCode值是不一样的
Student s1=new Student("张三",20);
Student s2=new Student("张三",20);
一般自己写一个类可以复写hashCode()方法,通过自己的属性值来计算哈希值。
public class Student{
private String name;
private int age;
//get和set,以及构造法自己补上
//alt+insert --> hashCode And equals
@Override
public int hashCode(){
int result = name != null ? name.hashCode() : 0;
result = 31 * result + age;
return result;
}
}
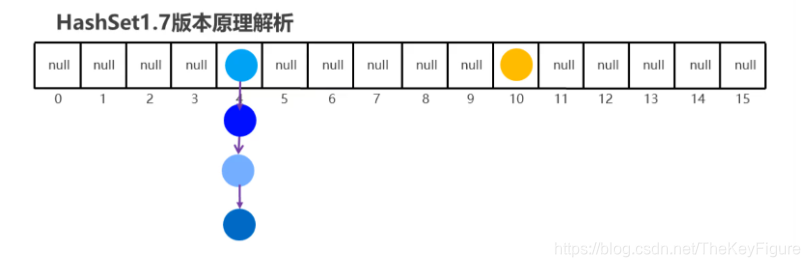
JDK7底层HashSet的原理
JDK7底层HashSet的数据结构(哈希表结构):数组+链表的结构
往HashSet集合中添加元素,底层做的事情
1.计算元素的hashCode值,根据hashCode值来确定在数组中那个索引的位置
2.判断这个位置是否有元素
如果没有元素,直接存储
如果有元素,把添加的元素和集合中已有的元素进行比较,是用equals进行比较
3.如果hashCode和equals比较都相同,就认为元素重复,就不存储
4.如果hashCdoe相同,但是equals比较不同,就以链表的形式存储
JDK8底层HashSet的原理
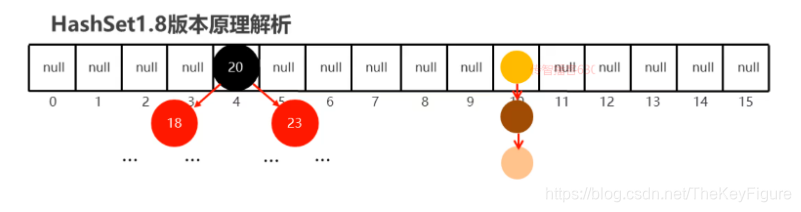
如果同一个hashCode值的位置元素超过八个,就把链表改为红黑树
JDK8底层HashSet的数据结构:数组+链表+红黑树
HashSet如何包装元素唯一
1.复写元素的hashCode方法
2.复写元素的equals方法
Map集合
Map表示的是双列集合,集合中的元素是成对出现的,一对元素包括【键和值】
Map集合中键是不能重复的,但是值是可以重复的
Map集合的继承体系
Map接口
HashMap类
TreeMap类
Map集合的基本使用
//键和值都是String类
Map<String,String> map=new HashMap<>();
//添加元素
map.put("猪八戒","高老庄");
map.put("孙悟空","花果山");
map.put("沙和尚","流沙河");
System.out.println(map);
Map集合的常见方法
public V put(k key,v value):把键和值添加到Map集合中; 如果键重复,新的值会替换旧的值。
把被修改的值返回。
public V get(Object key)
根据键或者值;如果找不到就返回null
public V remove(Object key)
根据键删除【键值对】
返回被删除的值。
public void clear()
清空集合的所有【键值对】
public int size()
获取Map集合中有多少个【键值对】
public boolean containsKey(Object key)
判断是否包含键
public boolean containsValue(Object value)
判断是否包含值
//定义一个字符串, 计算每一个字符出现的次数 h(2) e(2) l(5)...
String str="hellojavahellowrold";
//键:字符,值:字符的个数
HashMap<Character,Integer> map=new HashMap<>();
//获取字符串中的每一个字符
for (int i = 0; i < str.length(); i++) {
char ch=str.charAt(i);
//判断map集合中是否包含ch键
if(map.containsKey(ch)){
//包含,先获取原来的值,再加1重新存回去
int value=map.get(ch);
map.put(ch,value+1);
}else{
//不包含,值就是1
map.put(ch,1);
}
}
System.out.println(map);
Map集合的遍历
通过键获取值的方式遍历Map集合
public Set<K> keySet()
返回Map集合所有键的Set集合
HashMap<String,String> map=new HashMap<>();
map.put("李晨","范冰冰");
map.put("贾乃亮","李小璐");
map.put("王宝强","马蓉");
//获取所有的键组成的Set集合
Set<String> keys = map.keySet();
for (String key : keys) {
//通过键获取值
String value = map.get(key);
System.out.println(key+"...."+value);
}
通过获取【键值对】的方式遍历Map集合
public Set<Map.Entry<K,V>> entrySet()
获取Map集合中所有的Entry对象,一个Entry对象表示一个【键值对】
//获取Entry对象的集合,Entry对象表示【键值对】
Set<Map.Entry<String, String>> entrys = map.entrySet();
//遍历Set集合
for (Map.Entry<String, String> entry : entrys) {
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key+"...."+value);
}
HashMap集合的底层原理
通过查看源代码发现,HashSet集合底层其实就是HashMap集合,所以HashSet的底层原理和HashMap的底层原理是一模一样的。
HashMap集合的特点
1.键不能重复
2.保证键的唯一性通过复写键的hashCode和equals方法
TreeMap集合的底层原理
通过查看源代码发现, TreeSet集合底层其实就是TreeMap集合,所以TreeSet的底层原理和HashMap的底层原理是一模一样的。
TreeMap集合的特点
1.可以对键进行排序
2.键的排序方式,可以使用自然排序Comparable和比较器排序Comparator

















 603
603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









