




目录
Protection Information (PRINFO)
Bits 07:Incompressible(不可压缩标识)——“数据压缩” 的 “免折腾开关”
Bit 06:Sequential Request(顺序请求标识)——“连续读取” 的 “团队协作信号”
Bits 05:04:Access Latency(访问延迟需求)——“数据优先级” 的 “加急标签”
Bits 03:00:Access Frequency(访问频率)——“数据热度” 的 “使用说明书”
各位看官,上回咱们聊了 NVMe 的"快递小哥"Write 命令,今天该说说它的黄金搭档——Read 命令!这位可是数据仓库里的"取件专员",专门负责把 SSD 仓库里的数据包裹准确无误地送到主机老板手上!
一、Read 专员的"员工档案"
在 NVMe 公司里,Read 专员可是个"老员工"了,同属于 I/O Commands。看看它的个人简历:
Read 专员基本信息表
| 属性 | 值 | 说明 |
| 操作码(Opcode) | 02h | 专属工号 |
| 工作类型 | Mandatory | 核心员工,必不可少 |
| 工作范围 | 所有控制器 | 全公司通用 |
| 工作职责 | 数据读出 | 查找数据并返回数据 |
二、Read 专员的"取件送件流程"
Read 命令的 “取件送件流程” 看着简单,实则藏着不少 “讲究”,咱们一步一步拆解它的 “打工日常”:
1. 接单:主机填单下单
当主机需要读取数据时,第一步就是填好 Read 命令的 “任务单”—— 也就是 Submission Queue Entry(提交队列条目),里面得写清楚三个关键信息:
- “货物位置”:其中包含取货仓库(要读取的 Namespace ID(NSID))和货架位置(起始 LBA)。
- “取货数量”:要读取的 LBA 数量(NLB)。
- “送货地址”:数据要送回主机内存的哪个位置 —— 通过 PRP(物理区域页)或 SGL(分散聚集列表)描述,相当于给 Read 命令指 “主机的收货地址”。
举个接地气的例子:你在电脑上双击打开一个 32KB 的文档,主机就会生成一张 Read 命令 “任务单”:NSID=1(系统盘)、起始 LBA=500、NLB=7(32KB÷4KB=8 个 LBA,NLB=7)、PRP 指向主机内存的 0x12340000 地址 —— 意思是 “去 1 号仓库,从 500 号货架取 8 个货位的东西,送到主机 0x12340000 这个地址”。
当主机把 Read 命令的 “任务单”(SQE)填好,然后放进对应的 I/O 提交队列(SQ),接着更新队列的 “尾指针”(Tail Doorbell)。
2. 找货:SSD 控制器解析任务,定位数据
SSD 控制器就像 “仓库调度员”,会不停检查 SQ 里的新任务,一旦看到 Read 命令,就立刻 “接活” 并开始解析:
- 验单:先检查 “任务单” 上的信息是否合法 —— 比如 NSID 对应的仓库是否存在、起始 LBA+NLB 有没有超出仓库的 “货架总数”(如果要读的 LBA 是 1000,但仓库只有 800 个 LBA,就会返回 “地址越界” 错误);
- 查地址映射:SSD 里的数据存在 “逻辑地址(LBA)” 和 “物理地址(NAND Flash 物理块)” 的映射关系,就像仓库的 “虚拟货架号” 和 “实际货架号” 对应表。控制器会查这个 “映射表”,找到要读取的 LBA 实际存在 NAND 的哪个物理块上;
- 判断数据位置:如果要读取的数据正好在 SSD 的 SLC cache(高速临时仓库)里,控制器就能较快地 “找到货”。如果在 TLC 或 QLC,则就要花费更多时间。
举个例子:如果要读的 32KB 文档正好在 SLC 里,控制器可能 2050 us 内就能取到数据;如果在 TLC (普通仓库),就得等 NAND 控制器 “慢悠悠” 地从物理块里把数据读出来,可能是 50200 us。
3. 送货:数据从 SSD 传到主机内存
找到数据后,Read 命令就进入 “送货环节”,这一步要解决两个核心问题:怎么高效传数据、怎么保证数据没传错。
(1)用 PRP/SGL 当 “送货路线图”
控制器会根据 “任务单” 上的 PRP 或 SGL 信息,确定主机内存的 “收货地址”:
- PRP 路线:如果数据要送到主机的连续内存地址(比如 0x12340000~0x12347FFF),PRP 就像 “直达路线图”,直接指一个连续地址段,控制器按地址把数据 “一口气送过去”;
- SGL 路线:如果数据要送到主机的多个分散内存地址(比如一部分送 0x12340000,一部分送 0x56780000),SGL 就像 “多站路线图”,把每个分散地址段列出来,控制器按顺序逐个送达。
这里要注意:NVMe over Fabrics 场景下,Read 命令必须用 SGL—— 因为网络传输的内存地址往往是分散的,PRP 搞不定 “跨网络的分散送货”。
(2)用 ECC 当 “送货安检”
数据在传输过程中可能因为电磁干扰、链路波动出现 “传错”(比如把 0 变成 1),所以控制器会给数据加一层 ECC(错误纠正码)—— 相当于给数据贴了 “安检标签”。
具体流程是:控制器从 NAND 读数据时,会同时读出对应的 ECC 码;传输到主机前,先检查 ECC 码是否和数据匹配(确认数据没在 SSD 内部传错);数据传到主机后,部分高端 SSD 还会让主机侧再校验一次 ECC,确保 “送货全程零差错”,即端到端保护。
如果 ECC 校验发现数据有错,控制器会先尝试用 ECC 码 “纠错”(比如纠正 1 个 bit 的错误);如果错得太多纠正不了,就会返回 “Unrecovered Read Error”(无法恢复的读取错误),让主机知道 “这趟货送不了,数据可能坏了”。
4. 签收:主机确认数据收到
当数据成功传到主机内存后,控制器会生成一张 “签收单”——Completion Queue Entry(CQE),放进对应的 I/O 完成队列(CQ),然后更新 CQ 的 “头指针”,还可能触发一个 MSI-X 中断(相当于给主机打个电话:“数据送到了,快来签收!”)。
主机收到中断后,会去 CQ 里读 “签收单”:
- 如果 “签收单” 上的状态是 “Successful Completion”(成功),主机就知道数据已经安全送到,可以开始处理(比如打开文档、加载游戏);
- 如果状态是 “Unrecovered Read Error”(读取错误),主机可能会重试 Read 命令,或者从备份数据里读取(比如数据库的备份副本)。
三、Read 专员的“进阶技能”
| 技能名称 | 功能描述 |
| Limited Retry (LR) | 有限重试机制 |
| Force Unit Access (FUA) | 强制单元访问,直接从 NAND 读取数据 |

Limited Retry (LR)
LR 是 Read 命令的 “错误处理调节器”,在 Write 命令中同样拥有该设定,就像给控制器的 “重试权限” 设了个阀门,只有 “开(1)” 和 “关(0)” 两种状态:
- 设为‘1’:有限重试,见好就收
当 LR=1 时,相当于主机跟控制器说:“读取要是出错,别死磕重试,试几次不行就收手!”
这种场景常见于 “对延迟敏感” 的业务 —— 比如游戏加载时,要是某个 LBA 数据读出错,控制器要是反复重试(可能重试几十次,耗时几毫秒),游戏就会卡顿;而有限重试(比如只试 2 次),一旦失败就立刻返回错误,主机可以快速切换到备份数据或提示 “加载失败”,反而能减少用户感知的延迟。
简单说:LR=1 是 “延迟优先”,宁可不成功,也别拖慢节奏。 - 清为‘0’:全力重试,绝不放弃
当 LR=0 时,主机给控制器的指令是:“只要有办法,就把数据救回来!”
控制器会启动 “全套错误恢复流程”—— 先试 ECC 纠错(纠正小范围 bit 错误),再试重新读取 NAND 物理块(可能换个读取电压、调整时序),甚至调用 SSD 内部的 “备用块”(如果数据存在冗余备份),直到成功读回数据,或确认 “数据彻底损坏、无法恢复” 才返回错误。
这种场景适合 “数据安全性优先” 的场景 —— 比如读取数据库的核心交易记录,哪怕多等几毫秒,也要尽力把数据读出来,避免数据丢失。
Force Unit Access (FUA)
FUA 是 Read 命令的 “数据来源控制器”,核心作用是 “强制让控制器从非易失性介质(NAND Flash)读数据,而不是从缓存(SLC 缓存)读”,相当于给数据读取加了个 “源头锁定”:
- 设为‘1’:强制读 NAND,拒绝 “缓存捷径”
当 FUA=1 时,不管要读的数据是否在 SLC 缓存里,控制器都必须 “绕开缓存,直接去 NAND 里读”,而且有两个硬性要求:
-
- 先确保数据在 NAND 里 “落盘”:如果要读的数据还在缓存里没写进 NAND(比如刚写入的热数据),控制器得先把缓存里的数据 “刷到 NAND”,再从 NAND 读出来;
- 返回的必须是 NAND 里的原始数据:不能返回缓存里可能被临时修改过的数据,保证读取到的是 “永久存储的真实数据”。
这个参数常用在 “数据一致性要求高” 的场景 —— 比如金融系统读取交易日志,必须确认读的是 “已经落盘的最终版本”,而不是缓存里可能还没提交的临时数据,避免出现 “读错版本” 的问题。
- 清为‘0’:缓存优先,怎么快怎么来
当 FUA=0 时,控制器会开启 “缓存优化模式”—— 如果数据在 SLC 缓存里,就直接从缓存读(速度比 NAND 快 5~10 倍);如果不在缓存,再去 NAND 读,读完后还会把数据 “缓存到 SLC”,方便下次读取。
这是日常使用的默认模式 —— 比如打开文档、浏览图片,优先读缓存能让操作更流畅,没人会在意 “读的是缓存还是 NAND”,只要快就行。
四、Read 专员的“高级技能”
| 高级技能 | 技术原理 | 应用场景 |
| Protection Information (PRINFO) | 数据保护信息,安全校验 | 企业级应用 |
| Dataset Management | 数据属性标记,智能优化 | 冷热数据分离 |
Protection Information (PRINFO)
端到端数据保护的核心配置字段,本文不做过多介绍。后续可能单篇介绍。
Dataset Management 字段
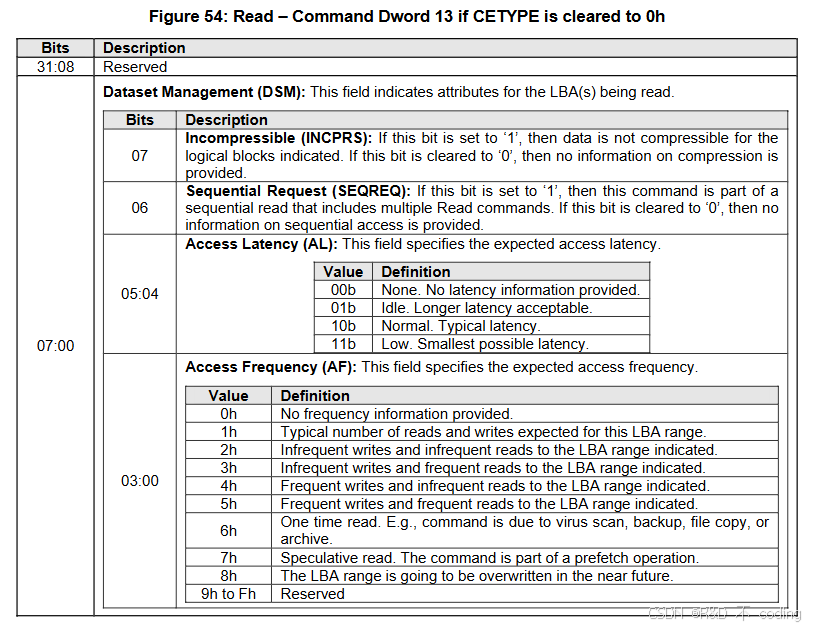
在 NVMe Read 命令的 “参数工具箱” 里,Command Dword 14 是个 “智能导航系统”—— 用 8 个核心比特(Bits 07~00)定义了读取数据的 “压缩特性、顺序属性、延迟需求、访问频率”,还藏着 “一次性读取”“预读取” 等特殊场景标识。它就像给 Read 命令装了 “导航仪”,让 SSD 控制器提前知道 “这数据该怎么读才高效”。今天咱们看它怎么帮 Read 命令 “少走弯路”。
Bits 07:Incompressible(不可压缩标识)——“数据压缩” 的 “免折腾开关”
这是个 “非黑即白” 的单比特开关,核心作用是告诉控制器 “要不要尝试压缩相关优化”,毕竟读取不可压缩的数据时,任何压缩操作都是 “无用功”:
- 设为‘1’:数据不可压缩,跳过压缩优化
当该位为 1 时,相当于主机给控制器递了张 “免压缩说明书”—— 比如读取已压缩的视频文件(MP4、MKV)或加密数据,这些数据本身已经是 “压缩到极限” 或 “无法再压缩” 的状态。控制器看到这个标识,就不会启动 “读取后尝试解压缩”“缓存中压缩存储” 等操作,直接按原始数据格式读取、传输,避免浪费 CPU 资源和延迟。
举个例子:读取一个 4GB 的电影文件,Bit 07=1 会让控制器 “直奔主题” 读原始数据,不用纠结 “能不能再压缩省空间”,反而能提速。 - 清为‘0’:无压缩信息,控制器自由判断
当该位为 0 时,主机没告诉数据是否可压缩,控制器就会 “按经验决策”。
简单说:Bit 07=0 是 “放权模式”,让控制器根据数据类型灵活处理,适合 “不确定数据压缩特性” 的通用场景。
Bit 06:Sequential Request(顺序请求标识)——“连续读取” 的 “团队协作信号”
这个比特专门用于标识 “当前 Read 命令是不是连续读取的‘一员’”,帮助控制器启动 “团队协作优化”:
- 设为‘1’:属于多命令连续读取,提前备货
当 Bit 06=1 时,说明当前 Read 命令是 “连续读取任务组” 的一员 —— 比如加载一个大游戏时,主机需要分 10 次 Read 命令读取 400MB 数据,这 10 个命令都会设 Bit 06=1。控制器看到这个标识,就会启动 “预加载 + 连续物理块读取” 优化:
-
- 提前读取下一个 Read 命令可能需要的 LBA 数据(比如当前读 LBA 100199,提前读 LBA 200299 到缓存);
- 清为‘0’:无顺序信息,按独立读取处理
当 Bit 06=0 时,控制器会默认当前 Read 命令是 “独立任务”,不会做预加载或连续块优化 —— 比如随机读取数据库的多条零散记录,每次读取的 LBA 不连续,预加载反而会浪费缓存空间,不如按 “读一个处理一个” 的逻辑来,效率更高。
Bits 05:04:Access Latency(访问延迟需求)——“数据优先级” 的 “加急标签”
这两位组合成 4 种 “延迟需求等级”,相当于给数据贴了 “加急件”“普通件”“慢件” 标签,让控制器按优先级分配资源:
| 取值(二进制) | 延迟等级 | 核心含义 | 适用场景 |
| 00b | None(无需求) | 主机没指定延迟要求,控制器按通用策略处理 | 日常读取不紧急的文件(如旧照片、文档备份) |
| 01b | Idle(可接受长延迟) | 数据是 “冷数据”,晚一点读也没关系 | 读取归档数据、一年以上没打开的备份文件 |
| 10b | Normal(典型延迟) | 常规 “温数据”,按正常速度读取即可 | 打开办公文档、浏览网页缓存 |
| 11b | Low(最小延迟) | 数据是 “热数据”,必须最快响应 | 读取系统核心文件、游戏实时加载资源、数据库高频查询记录 |
Bits 03:00:Access Frequency(访问频率)——“数据热度” 的 “使用说明书”
这四位定义了数据的 “读写频率”,相当于告诉控制器 “这数据会被频繁访问,还是读一次就闲置”,帮助控制器优化缓存和物理存储位置:
- 0h:无频率信息:主机没说数据会被读多少次,控制器按默认策略处理(比如暂存缓存 5 分钟,没再读就清理)。
- 1h:典型频率:数据读写次数中等(比如每周打开几次的工作文档),控制器会平衡缓存占用和读取速度,不常驻缓存但也不轻易清理。
- 2h:低频读写:数据读和写都少(比如归档的财务报表),控制器会把数据存在 TLC/QLC 层(非高速区域),不占用宝贵的 SLC 缓存。
- 3h:低频写、高频读:数据很少修改但经常读(比如系统镜像、常用软件安装包),控制器会让数据 “常驻 SLC 缓存”,确保每次读都快,同时因写入少,不用频繁做磨损均衡。
- 4h:高频写、低频读:数据经常改但很少读(比如临时日志文件、下载临时文件),控制器会优先保证写入速度,读取时不用常驻缓存,避免浪费空间。
- 5h:高频读写:数据是 “核心热数据”(比如数据库实时交易表、游戏存档),控制器会把数据存在最快的 SLC 缓存,同时用 “磨损均衡优化” 分散写入压力,兼顾速度和 SSD 寿命。
- 6h:一次性读取:数据读一次就不用了(比如病毒扫描临时读取的文件、备份时的源文件),控制器读完后直接清理缓存,不占用空间 —— 比如病毒扫描完一个文件,Bit 03:00=6h,控制器读完就删缓存,避免缓存被 “一次性数据” 塞满。
- 7h:推测性读取:当前 Read 命令是 “预加载任务”(比如系统预判你会打开某个文件,提前读取),控制器会把数据暂存缓存,要是后续真的读取,就直接用;要是没读,过一会儿就清理,不浪费资源。
- 8h:近期会被覆盖:数据很快会被新数据覆盖(比如临时编辑的草稿文件),控制器不用做长期存储优化,读完后甚至不写回 NAND,直接在缓存处理,减少 NAND 写入损耗。
- 9h~Fh:保留值:目前 NVMe 规范没定义这些值,控制器遇到会按 “0h(无频率信息)” 处理,避免出错。
五、总结:Read 专员的"职业守则"
看完 Read 专员的 “工作日常”,你会发现:它不是简单的 “读数据 - 传数据”,而是集 “地址映射、缓存调度、错误校验、并行优化” 于一身的 “全能跑腿员”。
三条黄金法则:
- 准确第一 - 数据必须完整无误
- 速度至上 - 响应要快如闪电
- 灵活应变 - 适应各种场景需求
Reference
NVM Express® NVM Command Set Specification, Revision 1.1
NVM Express® Base Specification, Revision 2.0e
NVM ExpressTM Revision 1.4c
各位看官,今天的"戏说 NVMe"就到这里。Read 专员就像数据世界的金牌配送员,默默守护着每一比特数据的准确送达。


















 2769
2769

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









