







 本文提出了一种基于常识知识图谱的对话模型(CCM),利用静态和动态图注意力机制,提高了对话生成的适当性和信息丰富度。通过结合常识知识图谱,模型能更好地理解用户请求,生成更合适的回复,尤其在处理低频词和OOV(Out-of-Vocabulary)问题时表现出色。
本文提出了一种基于常识知识图谱的对话模型(CCM),利用静态和动态图注意力机制,提高了对话生成的适当性和信息丰富度。通过结合常识知识图谱,模型能更好地理解用户请求,生成更合适的回复,尤其在处理低频词和OOV(Out-of-Vocabulary)问题时表现出色。
OpenKG 祝各位读者中秋快乐!

链接:http://coai.cs.tsinghua.edu.cn/hml/media/files/2018_commonsense_ZhouHao_3_TYVQ7Iq.pdf
动机
在以前的工作中,对话生成的信息源是文本与对话记录。但是这样一来,如果遇到 OOV 的词,模型往往难以生成合适的、有信息量的回复,而会产生一些低质的、模棱两可的回复。
为了解决这个问题,有一些利用常识知识图谱生成对话的模型被陆续提出。当使用常识性知识图谱时,由于具备背景知识,模型更加可能理解用户的输入,这样就能生成更加合适的回复。但是,这些结合了文本、对话记录、常识知识图谱的方法,往往只使用了单一三元组,而忽略了一个子图的整体语义,会导致得到的信息不够丰富。
为了解决这些问题,文章提出了一种基于常识知识图谱的对话模型(commonsense knowledge aware conversational model,CCM)来理解对话,并且产生信息丰富且合适的回复。本文提出的方法,利用了大规模的常识性知识图谱。首先是理解用户请求,找到可能相关的知识图谱子图;再利用静态图注意力(static graph attention)机制,结合子图来理解用户请求;最后使用动态图注意力(dynamic graph attention)机制来读取子图,并产生合适的回复。通过这样的方法,本文提出的模型可以生成合适的、有丰富信息的对话,提高对话系统的质量。
贡献
文章的贡献有:
(1)首次尝试使用大规模常识性知识图谱来处理对话生成问题;
(2)对知识图谱子图,提出了静态/动态图注意力机制来吸收常识知识,利于理解用户请求与生成对话;
方法
⒈Encoder-Decoder 模型
经典的Encoder-Decoder模型是基于sequence-to-sequence(seq2seq)的。encoder模型将用户输入(user post)X 用隐状态 H 来表示,而decoder模型使用另一个GRU来循环生成每一个阶段的隐状态
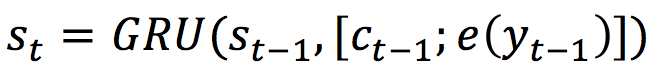 其中 c_t 是上下文向量,通过注意力机制按步生成。最终,decoder模型根据概率分布生成了输出状态,并产生每一步的输出token。
其中 c_t 是上下文向量,通过注意力机制按步生成。最终,decoder模型根据概率分布生成了输出状态,并产生每一步的输出token。
⒉模型框架:如下图1所示为本文提出的CCM模型框架。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 825
825

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









