







 OpenRichpedia是由东南大学开发的多模态开放知识图谱,旨在整合文本和视觉数据,构建丰富的结构化知识。它包含了大量城市、景点和人物的图像实体及其关系,提供了多模态语义关系的抽取方法。OpenRichpedia网站提供了查询、SPARQL、实体链接和关系抽取等功能,为多模态知识图谱的研究和应用提供了资源和平台。
OpenRichpedia是由东南大学开发的多模态开放知识图谱,旨在整合文本和视觉数据,构建丰富的结构化知识。它包含了大量城市、景点和人物的图像实体及其关系,提供了多模态语义关系的抽取方法。OpenRichpedia网站提供了查询、SPARQL、实体链接和关系抽取等功能,为多模态知识图谱的研究和应用提供了资源和平台。
OpenKG地址:http://openkg.cn/dataset/richpeida
GitHub地址:https://github.com/OpenKG-ORG/OpenRichpedia
Gitee地址:https://gitee.com/openkg/richpedia
官网地址:http://richpedia.cn(提供Dump)
开放许可协议:CC BY 4.0
贡献者:东南大学(漆桂林,王萌,郑秋硕,郑健雄,柏超宇,王硕)

提出背景
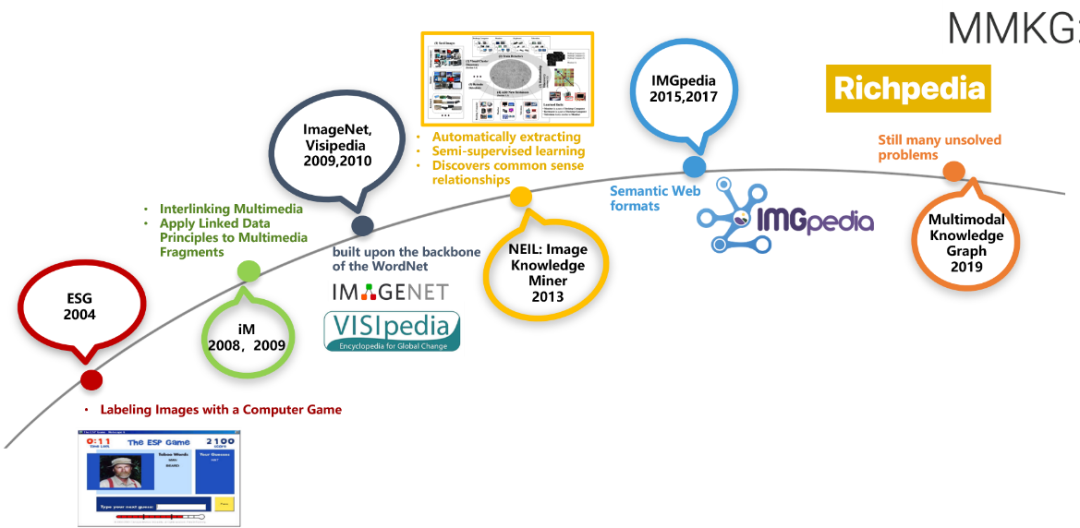
知识图谱技术已经被广泛用于处理结构化数据(采用本体+D2R技术)和文本数据(采用文本信息抽取技术),但是还有一类非结构化数据,即视觉数据,则相对关注度较低,而且缺乏有效的技术手段来从这些数据中提取结构化知识。最近几年,虽然有一些多模态视觉技术提出,这些技术主要还是为了提升图像分类、图像生成、图像问答的效果,不能很好地支撑多模态知识图谱的构建。视觉数据库通常是图像或视频数据的丰富来源,并提供关于知识图谱中实体的充分视觉信息。显然,如果可以在在更大范围内进行链接预测和实体对齐,进而进行实体关系抽取,可以使现有的模型在综合考虑文本和视觉特征时获得更好的性能,这也是我们研究多模态知识图谱(multi-modal knowledge graph)的意义所在。
目前,已经有很多开放知识图谱(见https://lod-cloud.net/和openkg),而且不少企业也有自己的企业知识图谱。然而,这些知识图谱很少有可视化的数据资源。
多模态知识图谱与传统知识图谱的主要区别是,传统知识图谱主要集中研究文本和数据库的实体和关系,而多模态知识图谱则在传统知识图谱的基础上,构建了多种模态(例如视觉模态)下的实体,以及多种模态实体间的多模态语义关系。例如在OpenRichpedia中,首先构建了图像模态伦敦眼图像与文本模态知识图谱实体(DBpedia实体:London eye)之间的多模态语义关系(rpo:imageof),之后还构建了图像模态实体伦敦眼与图像模态实体大本钟之间的多模态语义关系(rpo:nextTo)。
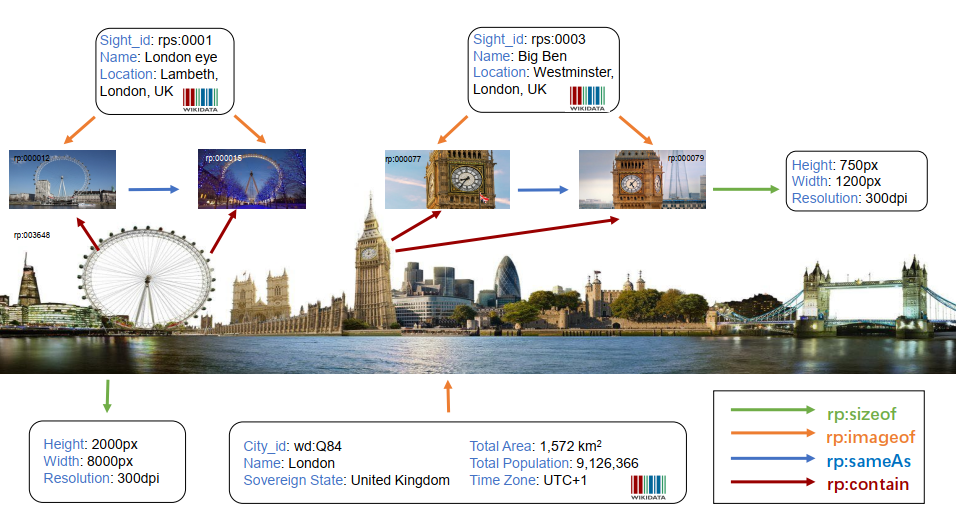

基于百科的多模态知识图谱OpenRichpedia
尽管已有一些研
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









