




 本文详细探讨了人工智能性能测试中的数据构造策略,包括结构化数据模拟、模拟设备规模、节点规模以及边缘计算场景。重点介绍了如何利用Spark和Kubernetes进行大规模数据生成和模拟,以及如何通过Kubemark进行性能测试以降低成本。
本文详细探讨了人工智能性能测试中的数据构造策略,包括结构化数据模拟、模拟设备规模、节点规模以及边缘计算场景。重点介绍了如何利用Spark和Kubernetes进行大规模数据生成和模拟,以及如何通过Kubemark进行性能测试以降低成本。
我们是如何测试人工智能的(三)数据构造与性能测试篇
作者:山治
前言
人工智能场景中的性能测试与我们在互联网中创建到的有很大的不同,因为它需要模拟更复杂的情况。当然它也有相似的地方,只不过今天我们主要介绍它们不同的地方。
产品分类
首先我们需要澄清一下, 从 AI 产品的类型来划分的话,我们可以分成两个大的类别:
- 人工智能的业务类产品:AI 就是为了某个特定的业务服务的。它的形态可能就是一个模型。可以是用来做广告或者内容推荐的模型,也可以是用来做人脸识别,对话问答的模型。 测试人员通常的测试对象就是这个模型,或者是搭载这个模型的上层业务,比较少会涉及到其他的东西,行业中做这种测试的人数占了大多数。
- 人工智能的平台类产品:随着 AI 能力进入到越来越多的业务中,大家发现高昂的人力和算力的成本都是非常大的负担, 所以业界期望有一种产品能够大幅度的降低 AI 的投入成本,希望能够通过一个平台产品让用户使用更简单的方法(比如 UI 上的操作)就可以进行数据的 ETL,特征的工程,模型的训练,上线,自学习等能力。 所以现在 AI 如此流行的大环境下, 越来越多这样的产品在业界中流行,几乎每个有点规模的 AI 公司都会有这样的产品。
在这个背景下,我们可以知道人工智能的平台类产品测试是更有难度的,它不是只对着一个模型,而是涉及到了 AI 的整个生命周期。 而我们第一个性能测试场景,就是针对模型训练的。
结构化数据模拟
在大数据与人工智能领域中的性能测试, 往往要涉及到数据模拟。 因为人工智能的基础是大数据, 只有海量的高质量数据才能支持人工智能。 所以我们在做性能测试的时候,也需要构造大量的数据来支撑模型的训练。 主要是为了衡量在标准数据下,算法需要多长时间才能把模型训练出来。 所以需要构建各种不同的标准数据。比如:
- 不同的数据规模(行数,列数)
- 不同的数据分布(数据倾斜)
- 不同的数据分片,文件数量(模拟数据切片规模和海量小文件场景)
- 不同的特征规模(高维特征,低维特征)
接下来要仔细的解释一下这几种数据场景:
-
不同的数据规模:这个比较好理解,就不细说了, 我们需要评估在不同数据规模下算法的性能表现。 从而推测出一个资源和时间的推导公式。
-
不同的数据分布:往往在特征工程和 ETL 中使用。这个是跟分布式计算的原理有关系的,分布式计算简而言之就是一个分而治之,比如用一个经典的计算词频的 DEMO 来解释。 当程序想要计算一个大文件中每个单词出现的次数的时候,需要把这些单词传输到独立的任务中。 比如把所有的 hello 传输到任务 A 中, 所有的 world 传输到任务 B 中。然后每个任务只统计一个单词出现的次数,最后再把结果进行汇总。 整个过程如下图,分布式计算追求的就是用多台机器的资源来加速计算过程,简而言之是任务被划分成多个子任务调度在多个机器里,而每个任务只负责其中一部分数据的计算。 在这样的原理之前我们会发现,如果 hello 这个单词出现的特别多, 占了整个数据量的 99%。 那么我们会发现就会有一个超大的子任务存在(99% 的数据传送到了一个子任务里),这样就破坏了分布式计算的初衷了。 变成了无限趋近于单机计算的形式。 所以一般要求我们的程序需要用一定的方法去处理数据倾斜的情况。
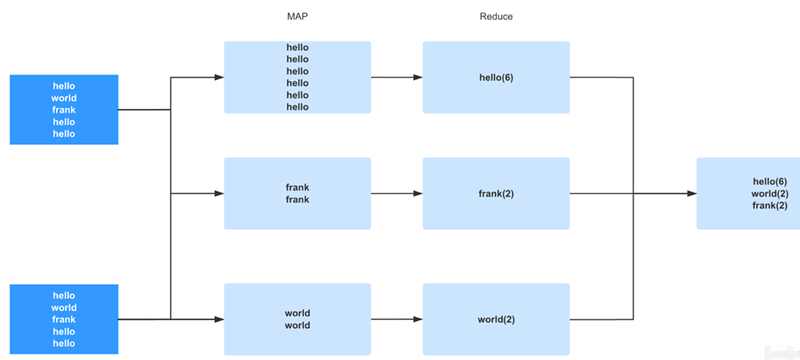
-
不同的数据分片和文件数量:了解到分布式计算的原理后,我们也需要知道分布式存储的原理, 当一份数据过大后,也需要对这份数据进行切片并保存在不同的机器中,所以一份数据其实是有很多个数据分片的。而数据分片多了以后也会出问题, 因为按照分布式计算的原理,每个数据分片也都会有一个独立的子任务去处理。一个独立的子任务就是一个线程,所以如果数据分片太多了,就会有过多的线程在系统中争抢 CPU 资源,并且每个线程其实也处理不了多少数据(因为数量分片太多,每个分片就没多少数据了)这时候大多数的资源都用来维护线程之间的开销了。 而海量的文件数量也会给存储系统带来压力。
-
不同的特征规模:通过之前的文章我们知道工程师需要先从数据中提取特征,然后把特征输入给模型进行训练的。所以除了原始数据的规模外, 重要的是经过特征工程后,有多少特征被提取了出来,特征的规模也直接影响了模型的性能和大小。 而特征也分围离散特征与连续特征。它们最大的区别在于算法在计算对应字段的时候如何处理,对于离散特征来说算法会将每一个唯一的值作为一个独立的特征,比如我们有用户表,其中职业这个字段中我们有 100 种职业,也就是说这张表不论有多少行,职业这个字段的取值就是这 100 个职业中的一个。 而对于算法来说每一个职业就是一个独立的特征。 老师是一个特征,学生是一个特征,程序员、环卫工人、产品经理、项目经理等等这些都是独立的特征。也就是说对于这张表,不论有多少行,算法针对职业这一字段提取出来的特征就是固定的这 100 个。而连续特征则完全不同,它是一个数字的数字,算法会把它当成一个独立的特征,也就是当算法把一个字段提取成为连续特征后,不管这张表有多少行,这个字段固定就只有 1 个特征被提出来。 所以我们做性能测试的时候, 场景描述通常都是:多少行,多少列,多少特征
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









