




我们是如何测试人工智能的(二)数据挖掘篇
作者:山治
前言
数据决定模型的上限,而算法调参只是尽量的帮你逼近那个上限,建模工程师 80% 的时间都是在跟数据打交道,国内在 AI 上的发展与国外最大的差距不是在算力上,而是高质量的数据。 相信大家在网络上都见过类似的说法,事实上这些说法都是正确的。并且对于测试人员来说也是一样的。 通过上一篇介绍效果测试的文章大家可以知道,目前已经有现成库帮我们去计算模型的评估指标,老实讲去计算这些指标没有一点难度,甚至可以说没什么技术含量,懂 python 的人都可以做。但是真正难的,是如何收集到符合场景要求的数据以及如何保证这些数据的质量,就连用 AI 测试 AI 这个方法,也需要先收集到符合要求的数据才能训练出可以用来测试的模型。 所以虽然我们是在测试 AI,但实际上我们掌握的最多的技能却是数据处理相关的,比如 spark, flink,opencv,ffmpeg 等等。 所以这一篇,我来科普一下在项目中,我们是如何处理数据的。
PS: 这一篇仍然是科普, 不会每一个点都扩展很详细的知识点。 还是以介绍工作内容为主
我们需要数据处理工具做什么
- 数据采集/挖掘:上篇文章中介绍了很多效果测试的方法, 但也说过符合测试场景要求的数据不会自动的飞到我们面前, 所以我们需要在茫茫多的数据中根据业务规则选取到我们需要的数据。
- 数据质量测试/监控:数据直接影响到模型效果, 所以我们需要针对数据进行测试和监控。 尤其在自学习场景中,如果数据出现问题需要及时的告警。
- 数据构造:往往应用于性能测试场景中,现在是卷大模型的时代,是比谁的训练样本更庞大的时代。 所以在性能测试中,往往需要构造非常大规模的数据进行心更难测试(数千万甚至数亿)。
- ETL/特征工程的测试:在整个建模过程中主要可以分为特征工程和模型训练:在结构化数据中特征工程会涉及到大量的拼表,时序特征计算等等操作。 在图像数据中会涉及到各种图像增强算法(二值化,灰度化,角点提取,滤波去噪等等),在 NLP 领域里会涉及到文本切片,切词,词向量,语料库构建等等。如果你面对的是一个人工智能平台,那么这些也就变成了测试对象。
- 数据标注:我们面对的大部分都是监督学习,所谓监督学习,就是算法在学习这份数据的时候, 我们需要告诉算法这条数据的答案。比如推荐系统里,你的数据里需要告诉算法当前用户是不是喜欢这个内容。反欺诈系统里,需要告诉算法这条数据是不是欺诈行为。 计算机视觉的目标检测场景中, 不仅要标注这张图片中是否有目标物体,还需要标注出物体的具体坐标(x,y,w,h: 中心点坐标和长度宽度,或者 4 个点的 x,y 坐标)。 不过好在结构化数据的标注非常简单, 就在表的对应列里写一个值就行了, 而计图片数据也有相关的数据标注工具可以使用。
那么接下来我们依次介绍一下这些工作的内容。
数据标注
先讲比较简单点的吧,从数据标注开始,当然大多数时候数据标注的工作是不需要测试人员来做的,一般都会有专门标注组来做这些基础的事情。但如果我们后续要训练自己的模型来辅助测试,一般就得自己来做数据标注的工作了(当然如果能为测试自己的需求申请到标注组的人力也是可以的, 但很多时候其实没这个必要,因为迁移学习的存在,我们不需要对大量的数据进行标注,所以有时候走流程去申请标注人员,还要去跟标注人员解释场景要求,所以很多时候倒不如自己上手比较快)。结构化数据是比较简单的,大多数时候就是一张表么,有一列叫做 label,你只要写上去就可以了。 如下图:

针对图片数据,一般需要对应的工具来标记分类的位置信息。 业界有很多的开源工具可以做到这一点, 各个厂商也会有自研的数据标注平台。 这里我以 labelme 为例。
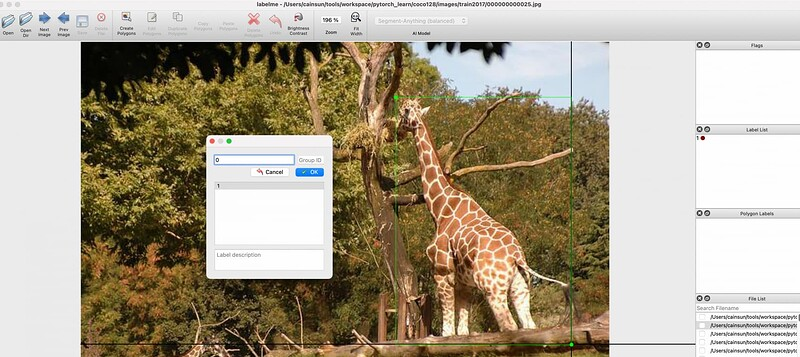
labelme 的安装是比较简单的, pip install labelme 就可以了。 用户可以选择一个目录,labelme 会按顺序显示这些图片,然后用户需要画出目标物体的位置并且告诉这个目标数据哪个分类。 然后它会把标注信息生成一个 json 文件:
{
"version": "5.3.1",
"flags": {
},
"shapes": [
{
"label": "0",
"points": [
[
12.597402597402663,
14.02597402597404
],
[
908.9397314013636,
1079.0
]
],
"group_id": null,
"description": "",
"shape_type": "rectangle",
"flags": {
}
}
],
"imagePath": "001.jpg",
"imageData": null,
"imageHeight": 1080,
"imageWidth": 1920
}
PS:由于选择使用了长方形的标注形式, 所以 json 文件中只记录了左上角和右下角的坐标信息。 如果有需要后面可以通过工具转成其他形式的坐标信息。
由于标注工作大部分时候跟测试人员关系不大, 所以这里先不过多讲解。
数据采集/挖掘
结构化数据
让我们先从结构化数据开始(因为最简单),上一篇文章中我们介绍效果测试时曾经说过要根据业务做分组的指标统计, 要根据用户画像,业务场景划分数据类型, 每种数据类型都要采集到足够的数据,这样才能更全面的评估模型针对不同场景,不同用户的效果如何。所以我们需要在茫茫多的数据中按照规则把这些数据筛选出来。 如果对自己的数据不熟悉,还需要使用一些数据统计的方法来统计一些数据信息, 比如计算一共有多少种用户职业,每种用户职业占比多少等等。玩 python 的同学通常都对 pandas 库比较熟悉,用 pandas 来计算处理这些数据还是比较方便的。 但很可惜的是大多数时候我们都无法使用这种方式来完成这部分工作。 因为人工智能是在大数据的基础之上的, 我们可能要面对数以百万,千万甚至亿的数据量。所以 pandas 往往无法满足我们的要求, 我们需要掌握至少一门分布式计算框架,我比较推荐 Spark,主要有三点:
- Spark 在结构化数据中算是万金油的,能适应绝大多数的数据存储系统。 并且它也有 dataframe 和 sql 两种高级 API 供用户选择, 喜欢 sql 的同学可以用 sql,喜欢 pandas 风格的同学可以使用 dataframe(我理解就是仿照 pandas 的接口开发出来的)
- Spark 本身也是一个机器学习包, 它专门有一个 machine learning 库,可以完成结构化数据领域中的大多数算法(并且支持分布式的运行)。 很多团队在做机器学习的时候都会选择使用 spark 来完成工作。 测试人员有些时候不是要在 UI 上或者通过接口对模型进行测试, 而是直接在底层直接对模型文件进行测试。 这时候如果算法团队是使用 spark ml 来实现的算法,那么也就需要测试人员调用 spark 的 API 来完成模型的加载,数据的处理,特征工程等操作。
下面演示一下做这种模型测试的 spark 代码。 我自己用 spark 训练出了一个模型, 然后用 spark 加载这个模型做模型的评估:
from pyspark.ml.tuning import TrainValidationSplitModel
from pyspark import SparkContext, SparkConf, SQLContext
from pyspark.sql import functions as F
from pyspark.sql.window import Window
conf = SparkConf().setMaster("local").setAppName("My App")
sc = SparkContext(conf=conf)
sqlContext = SQLContext(sc)
dicts = [
['frank', '男', 16, '程序员', 3600, 1.0],
['alex', '女', 26, '项目经理', 3000, 1.0],
['frank', '男', 16, '程序员', 2600, 0.0],
['asdf', '男', 16, '程序员', 2600, 0.0],
['fragfsnk', '男', 16, '程序员', 2600, 0.0],
['frasdfgnk', '男', 16, '程序员', 2600, 0.0],
['frsdfgank', '男', 16, '程序员', 2600, 0.0],
['frsdfgdfank', '男', 16, '程序员', 2600, 0.0],
['frsdfgdfankdsaf', '男', 16, '程序员', 2600, 0.0],
['frsdfgdfank342', '男', 16, '程序员', 2600, 0.0],
['frsdfgdfank445', '男', 16, '程序员', 2600, 0.0],
['frsdfgdfank756', '男', 16, '程序员', 3600, 1.0],
['hdfg', '男', 16, '程序员', 2600, 0.0],
['frsdfncvgdfank', '男', 16, '程序员', 2600, 0.0],
['wert', '男', 16, '程序员', 2600, 0.0],
['sdfg', '男', 16, '程序员', 2600, 0.0],
['frssdffgdfank', '男', 16, '程序员', 2600, 0.0],
['asdf', '男', 16, '程序员', 2600, 0.0],
['zxcv', '男', 16, '程序员', 2600, 0.0],
['frsdfgdfank', '男', 16, '程序员', 2600, 0.0],
['vzxcv', '男', 16, '程序员', 2600, 0.0],
['zxcv', '男', 16, '程序员', 3600, 1.0],
['frsdfgdcvfank', '男', 16, '程序员', 3600, 1.0],
['frsdfgdcvfankasdf', '男', 16, '程序员', 3600, 1.0],
['asfghffgh', '男', 16, '程序员', 3600, 1.0],
['dfgh', '男', 16, '程序员', 3600, 1.0],
['frsdfgdcvbnmvbvfank', '男', 16, '程序员', 3600, 1.0],
['v', '男', 16, '程序员', 3600, 1.0],
['dasdfsadf', '男', 16, '程序员', 3600, 1.0],
['gghg', '男', 16, '程序员', 3600, 1.0],
]
rdd = sc.parallelize(dicts, 3)
dataf = sqlContext.createDataFrame(rdd, ['name', 'gender', 'age', 'title', 'price', 'label'])
# 计算时序特征,计算每种性别中历史最大的price值(模拟计算用户最大消费额的特征计算)
windowSpec = Window.partitionBy(dataf.gender)
windowSpec = windowSpec.orderBy(dataf.age)
windowSpec = windowSpec.rowsBetween(Window.unboundedPreceding, Window.currentRow)
dataf.withColumn('max_price', F.max(dataf.price).over(windowSpec)).show()
from pyspark.ml.feature import StringIndexer, OneHotEncoder, VectorAssembler
# 将非数值类型的字段转换为数值类型
stringIndexer = StringIndexer(inputCol="title", outputCol="title_num")
data_indexed = stringIndexer.fit(dataf).transform(dataf)
# 将类别特征进行独热编码
encoder = OneHotEncoder(inputCol="title_num", outputCol="title_onehot")
data_encoded = encoder.fit(data_indexed).transform(data_indexed)
# 将所有特征组合成一个特征向量
vectorAssembler = VectorAssembler(inputCols=["age", "title_onehot", "price"], outputCol="feature")
data_vector = vectorAssembler.transform(data_encoded)
# 从模型文件中加载模型,
model = TrainValidationSplitModel.load('../model')
predictions = model.transform(data_vector)
predictions.show()
result = predictions \
.withColumn('result', F.when((F.col('prediction') == 1.0) & (F.col('label') == 1.0), 'TP')
.when((F.col('prediction') == 1.0) & (F.col('label') == 0.0), 'FP')
.when((F.col('prediction') == 0.0) & (F.col('label') == 0.0), 'TN')
.when((F.col('prediction') == 0.0) & (F.col('label') == 1.0), 'FN')
.otherwise('')) \
.select('label', 'prediction', 'result') \
# .show()
result.show()
# 计算混淆矩阵与准招率。
TP = 0
FN = 0
FP = 0
TN = 0
rows = result.collect()
for row in rows:
if row['result'] == 'TP':
TP = TP + 1
if row['result'] == 'FP':
FP = FP + 1
if row['result'] == 'TN':
TN = TN + 1
if row['result'] == 'FN':
FN = FN + 1
recall = TP / (TP + FN)
precision = TP / (TP + FP)
print("recall: " + str(recall))
print("precision: " + str(precision))
上面的代码我们使用 spark 加载了模型, 并且进行了特征工程(选取特征列, 计算时序特征,将离散特征做独热编码,特征转换成特征向量), 特征工程结束后输入到模型中去预测结果, 最后计算模型的召回率和精准率。 这里需要注意的是:
- 我们测试模型的时候依然要做特征工程的, 要产出一个模型主要有两个重要的部分:特征工程和模型训练, 模型只接受经过特征工程后的数据。 所以不论是模型训练, 还是我们去测试, 都要先针对数据进行特征工程才能测试。 这也是为什么我说学习 spark 是个比较万金油的选择。 既能做数据处理, 也能用来完成模型的测试。
还有一个需要注意的是下面这段代码:
result = predictions \
.withColumn('result', F.when((F.col('prediction') == 1.0) & (F.col('label') == 1.0), 'TP')
.when((F.col('prediction') == 1.0) & (F.col('label') == 0.0), 'FP')
.when((F.col('prediction') == 0.0) & (F.col('label') == 0.0), 'TN')
.when((F.col('prediction') == 0.0) & (F.col('label') == 1.0), 'FN')
.otherwise 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 871
871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









