



 移动APP测试面临迭代效率低、设备获取困难、用户体验难验证和问题收集定位复杂等问题。行业解决方案包括集成化的功能测试平台、云端实验室以及云测试服务,如TestBird,它们提供按需付费的真机测试、自动化测试和全面的问题呈现,帮助提高测试效率和用户体验,同时降低成本。
移动APP测试面临迭代效率低、设备获取困难、用户体验难验证和问题收集定位复杂等问题。行业解决方案包括集成化的功能测试平台、云端实验室以及云测试服务,如TestBird,它们提供按需付费的真机测试、自动化测试和全面的问题呈现,帮助提高测试效率和用户体验,同时降低成本。
移动APP质量验证面临的挑战
TOP1 迭代效率低
开发测试速度跟不上需求变化
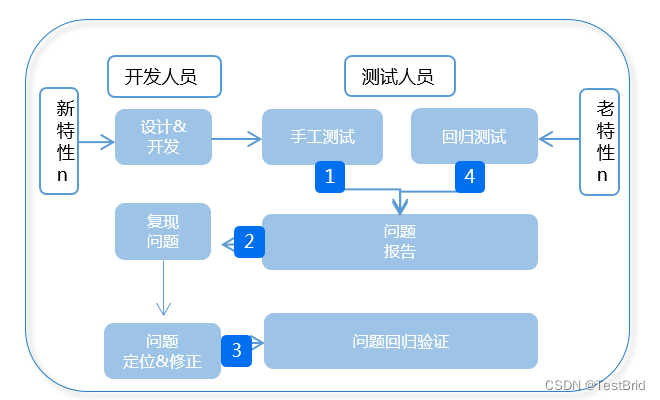
主要问题:1.手工测试信息混乱
2.老特性的回归影响新特性的验证
3.开发定位问题缺乏足够信息支撑
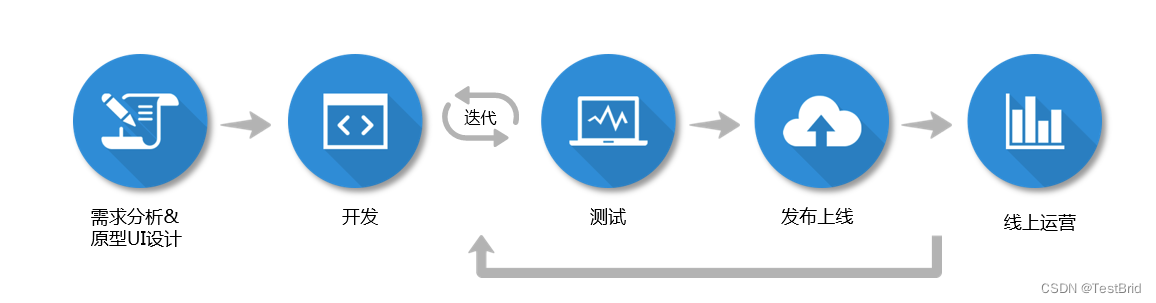
每次迭代功能特性众多,周期常为1~2周或更短;每轮迭代都由诸多微循环构成,微循环的效率决定了迭代的效率
迭代测试循环
业内解决方案
集成化的功能测试平台
快速准确记录问题现象
全面呈现问题,包括日志、截图、性能指标等
TOP2 设备获取困难
手机难以获取,费用高管理难度大
从研发流程角度,终端在APP的开发调试、功能测试、问题定位等环节都会用到
从质量效果来说,移动APP需要保证在主流终端上都能运行通过,才能保障用户的转化和留存率
存在问题
1.自购手机一次性投入成本高,且手机更新换代
2.大量的手机资源,难以管理,经常会会出现手机找不到的情况
3.就算有大量的手机,多数也无法实现批量自动化测试,手工测试工作量也难以支撑
业界解决方案:云端实验室
1.按需付费使用,而不需要付出购买一部真机的钱
2.可以随时切换手机型号,紧紧跟踪时代潮流
3.支持兼容性测试,可调度几百部手机进行自动化测试
TOP3 用户体验难验证
需提前验证测试方法,发布前难获得真实用户
用户体验受到许多综合因素影响,业界一般采用如下方法
邀请外部的普通用户,针对软件进行探索式测试,在测试过程中提出自己的感想和问题
邀请专业用户进行专项测试,如UI测试、弱网测试、APP性能测试
服务端压力测试:在高压力情况下,服务器对APP的响应能力,直接影响到用户体验
用户体验测试,需要关注和解决如下命题
软件保密性:未发布前,客户的APP需要保密
用户的可获得性,包含普通用户和专业用户
测试成本的可接受性
服务端压力测试过程需要可控,从而支持问题定位
TOP4 测试问题收集和定位困难
以上问题总的来说可以总结为一下四点
1.市场及用户需求变化快
2.终端碎片化严重,需要确保上千款各种型号手机、pad流畅运行
3.用户体验要求高
4.用户规模海量,地域分布广泛
又想省成本,覆盖度又可以达到,项目做的快。其实目前都可以使用云测试服务问题解决,目前市场上也有很多家成熟的云测试服务平台。
特点:

















 5227
5227

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









