



 本文介绍了HDFS的基本概念,包括Block、NameNode和DataNode,详细讲解了HDFS的体系结构、数据管理策略和文件读写操作。同时,文章探讨了MapReduce的批处理计算模型,阐述了MapReduce的运行流程及优缺点。
本文介绍了HDFS的基本概念,包括Block、NameNode和DataNode,详细讲解了HDFS的体系结构、数据管理策略和文件读写操作。同时,文章探讨了MapReduce的批处理计算模型,阐述了MapReduce的运行流程及优缺点。
HDFS是Hadoop的文件系统,MapReduce是Hadoop并行计算框架。
HDFS
基本概念
HDFS是Hadoop的分布式文件系统,全名为Hadoop Distributed File System。它有以下三个基本概念:
-
Block(块)
-
NameNode
-
DataNode
块是默认大小为64MB的逻辑单元。HDFS里面的文件被分成相同大小的数据块来进行存储和管理。当然,文件的备份和查找也是基于数据块进行处理的。
NameNode是管理节点(直译名字节点)。它存放着文件与数据块(Block)的映射表,也存放着数据块与数据节点(DataNode)的映射表。这俩被统称为文件元数据。
DataNode是工作节点(也就是数据节点),用来存放数据块。比如下图中,每个工作节点就存放了三个数据块。
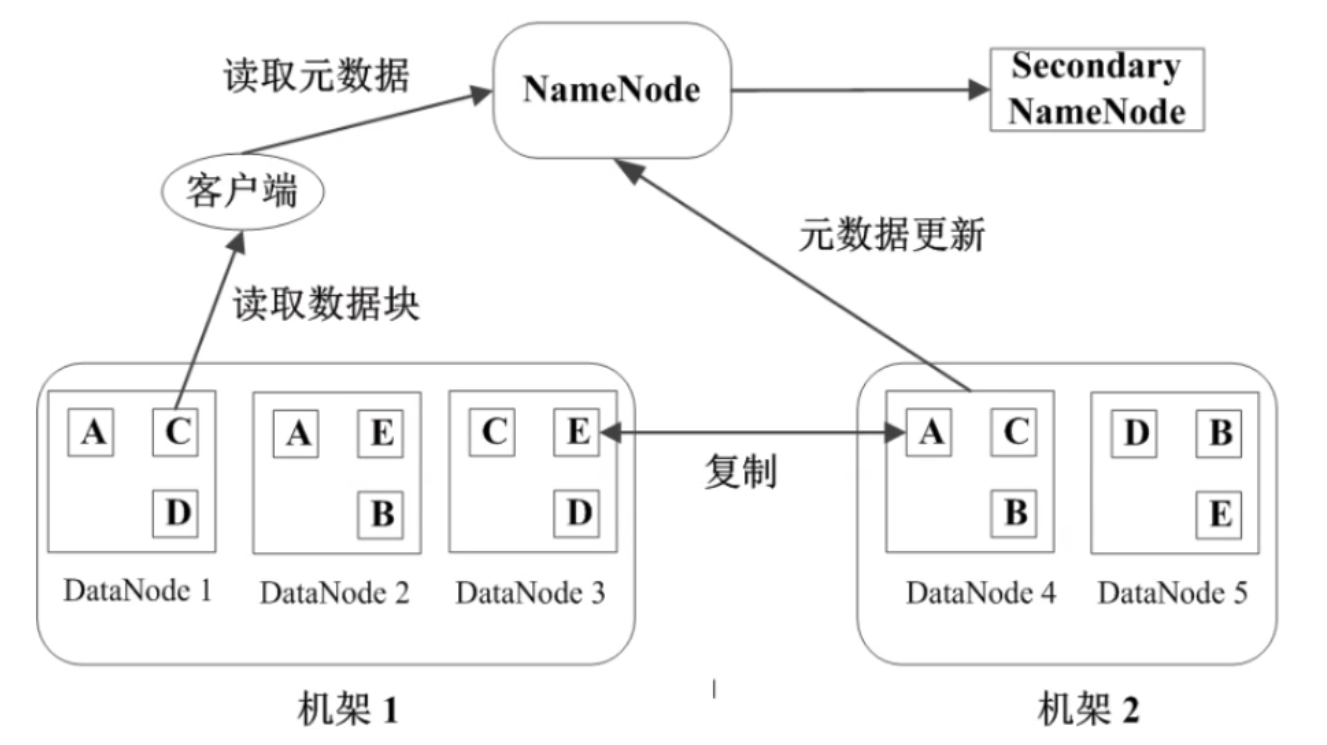
HDFS体系结构
如果要打个比喻的话,那么DataNode就像图书馆中的书架,每个书架上都存储着相应的书(数据块),NameNode就像图书管理员,知道每本书存放在什么书架上,也知道每本书里面写着什么内容(数据)。
数据管理策略
作为一个分布式的文件系统,HDFS是有它自己的数据管理策略的。比如,以上面的图为例,每个数据块都会有三个副本,分布在两个机架内的三个节点。如果我们要读取一个数据块C的话——
-
如果DataNode1发生了故障,那么客户端还可以在机架1的DataNode3中找到数据块C。
-
如果整个机架1都发生了故障,那么客户端还可以在机架2的DataNode4中找到数据块C。
除了三份副本以外,HDFS还可以检测自己是否已经发生了故障。
-
DataNode会定期向NameNode发送心跳消息,以检测节点是否发生关机、宕机、网络故障等等,这样管理节点就会知道哪些节点挂了,哪些节点还可用。
-
Secondary NameNode(二级NameNode)会定期同步元数据映像文件和修改日志。当NameNode里面存储的元数据发生故障的时候,备胎转正,二级NameNode成为NameNode。
文件读写操作
文件读取就很简单了。首先客户端从NameNode发出文件读取请求,然后NameNode将返回一个元数据。接着,客户端就像一个顾客一样(虽然本质上是Java程序或者命令行)按照手上的「图书清单」到工作节点上去寻找相应的数据块,最后把数据块们下载下来并进行组装。
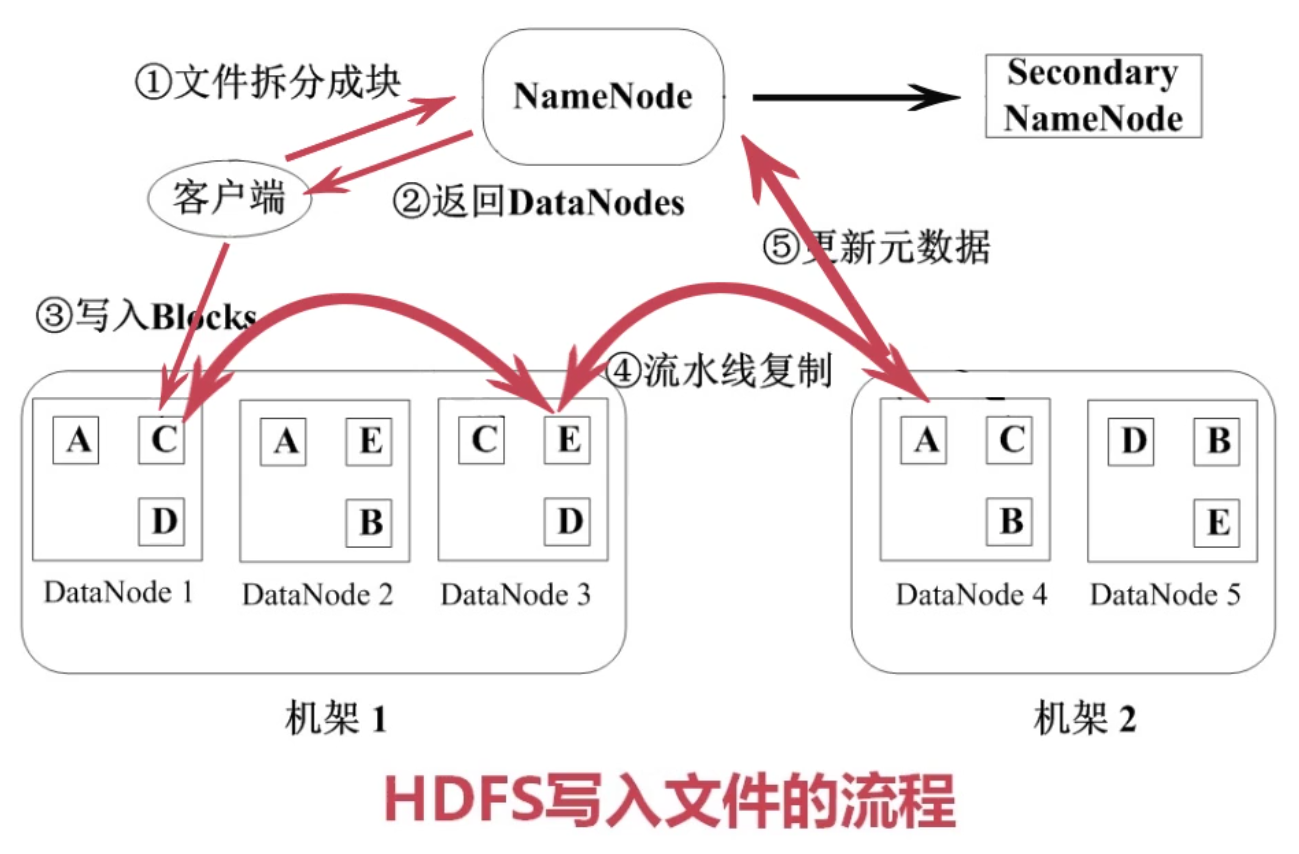
文件写入稍稍麻烦一点。首先客户端(此时客户端变成了图书经理)会把需要写入的文件拆分成块,然后通知NameNode,让其报告一下哪些DataNodes可以写入文件。(如果要写入多个块,则从这里开始循环)接着客户端把一个块写入DataNodes内,并通过一个复制管道进行流水线复制,以保证存在多个副本。最后报告给NameNode并更新元数据,保证里面的映射是最新的状态。
这样我们就能看出HDFS的特点了——
-
数据非常冗杂,每个数据块都要有三份备份,但同时也保证了较高的硬件容错性。
-
流式的数据访问,来一点数据就处理一点数据,不会占用很大的内存。
-
一次写入多次读取,写进去的数据块无法被修改,只能先删除块之后再次写入。
-
适用于存储大文件。大量的小文件会加重NameNode的压力。
HDFS适合数据批量读写,吞吐量高,也适合一次写入多次读取,按顺序读写;但不适合交互式应用,很难满足低延迟的要求,也不支持用户并发地写相同的文件。
HDFS使用
现在我们来用Hadoop实现一下HDFS系统。HDFS中有shell接口,因此我们在linux系统里可以像linux的命令行一样使用HDFS的命令。
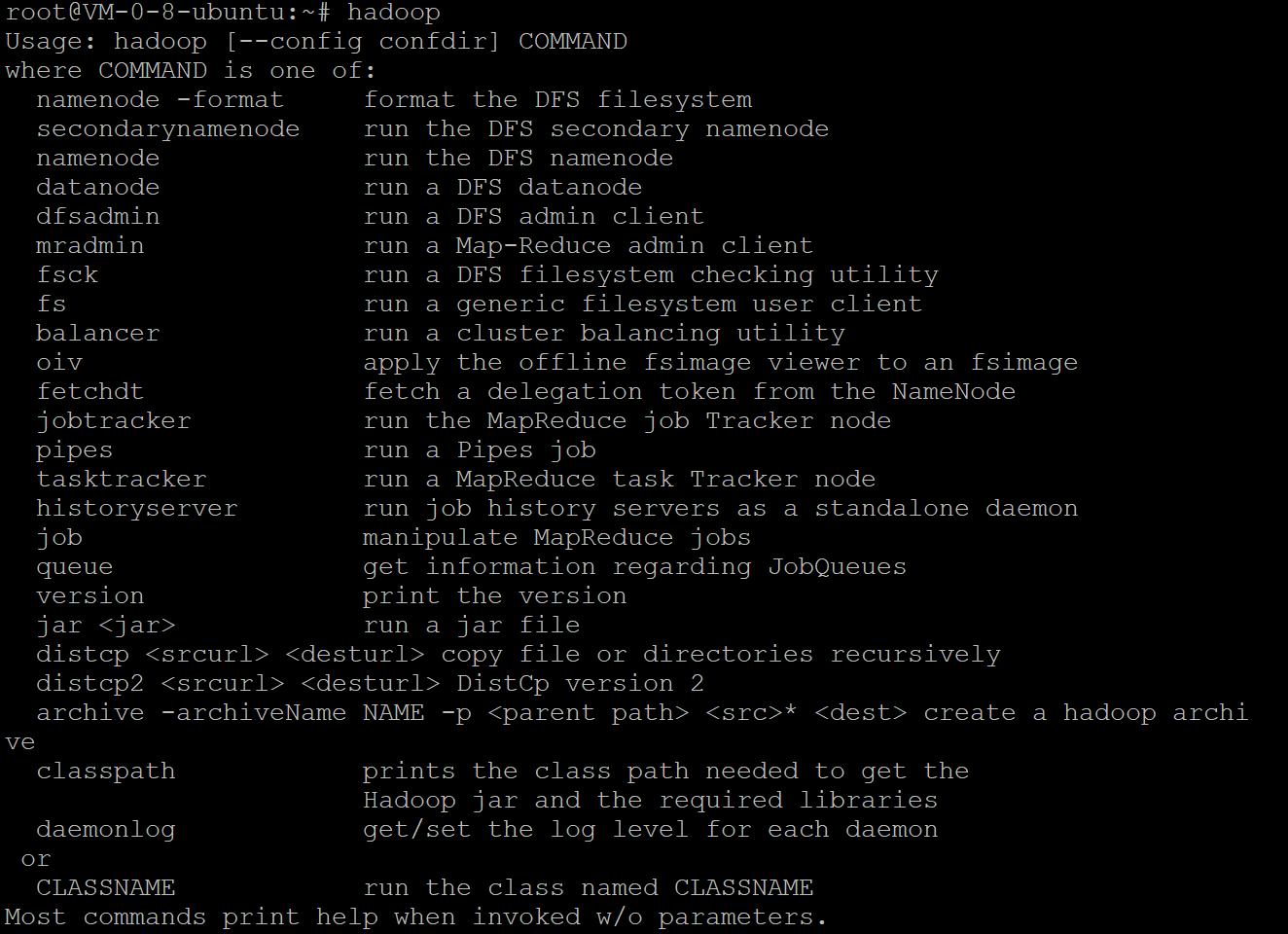
Hadoop拥有的命令
其中常用的命令如下:
hadoop fs -ls / #打印 / 目录文件列表
hadoop fs -mkdir input #创建目录
hadoop fs -put hadoop-env.sh input/ #上传文件 hadoop-env.sh 到 input 目录下
hadoop fs -get input/abc.sh hadoop-envcomp.sh #从 input 目录中下载文件
hadoop fs -rmr #hadoop删除文件命令
hadoop namenode -formet #hadoop格式化操作
hadoop dfsadmin -report #hadoop查看存储信息
现在看看我们是怎么具体实现HDFS的读写操作的。
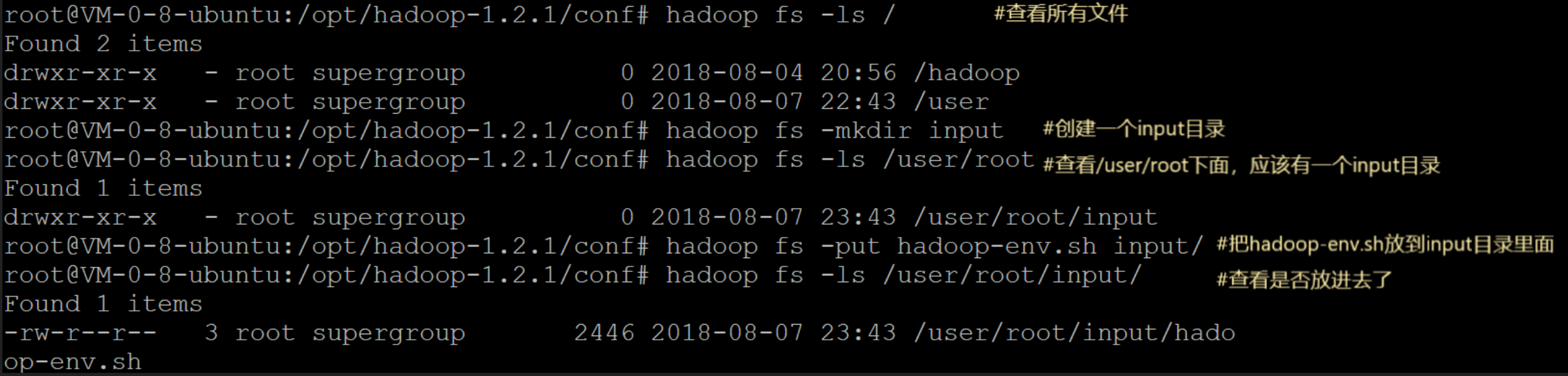
把hadoop-env.sh文件写入input目录中
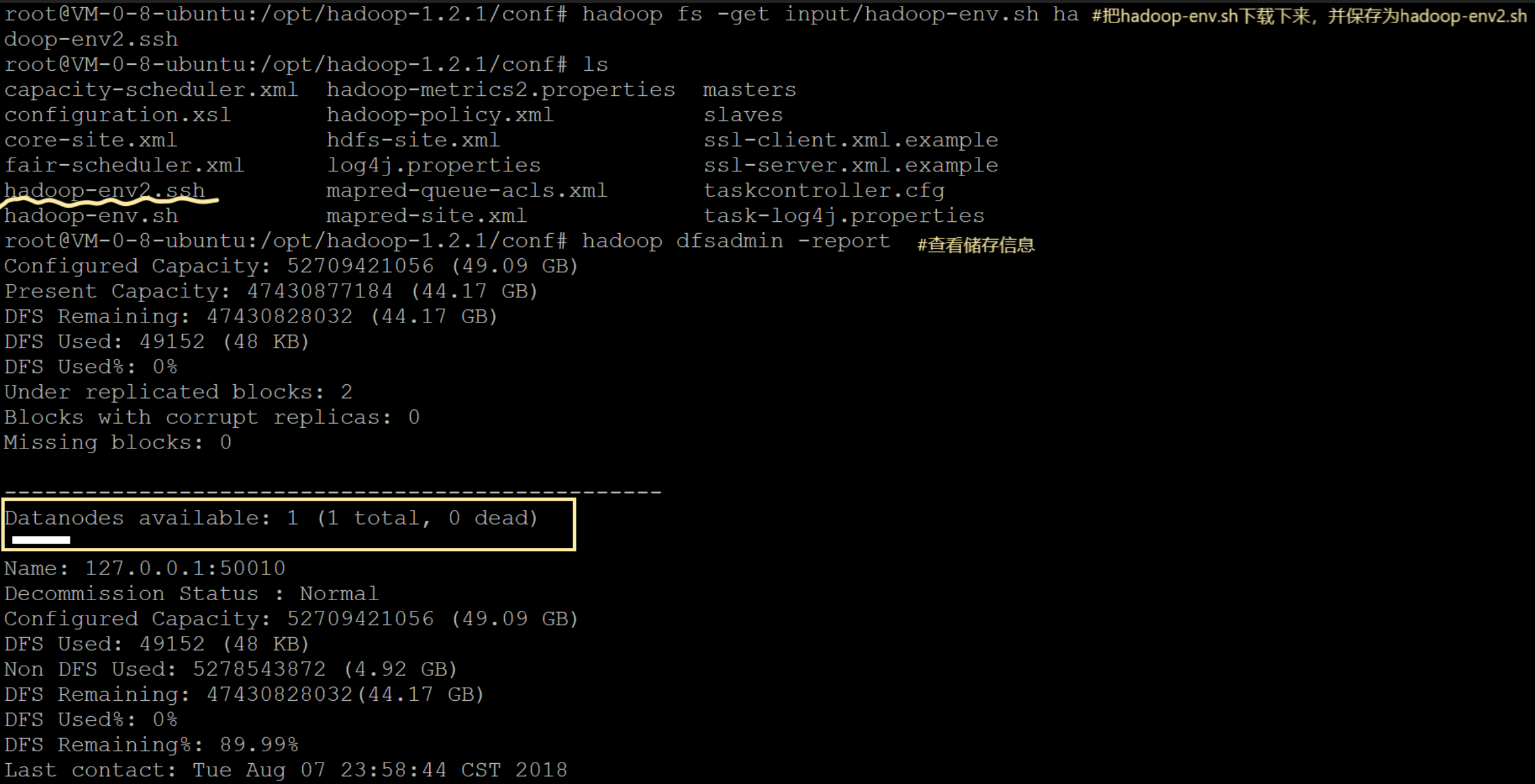
读取文件,并下载到本地
上述就是从客户端(也就是命令行)上传文件(发出写入请求)与下载文件(发出读取请求)的过程。
MapReduce
原理
MapReduce的本质是Map-Reduce的批处理计算模型。Map指的是把一个大任务分割成多个小的子任务,Reduce指的是把子任务执行完后的结果合并的规约过程。可以看出,MapReduce也存在着分治法的思想。
比如,我们要从大容量的网络访问日志文件中,找出访问次数最多的IP地址。MapReduce先把日志切分成几个子任务,并统计IP出现的次数。接着任务间互相交换结果,把各个IP地址的访问结果统计出来,最后中间结果合并,排序,就知道了哪个IP地址访问次数最多了。
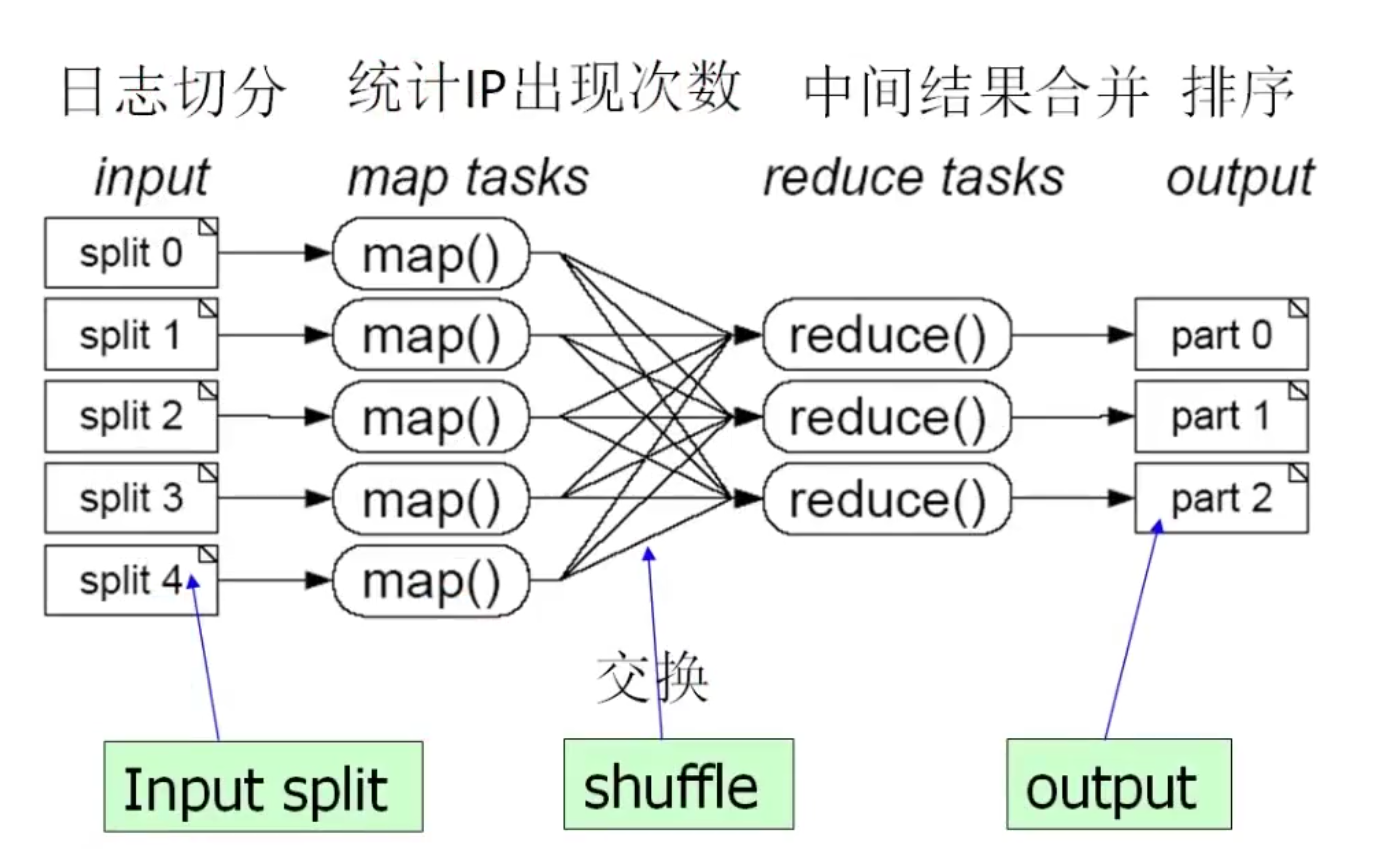
MapReduce的优缺点很多,分布式可以让超级服务器才能处理的数据让多台小机器也能实现,但是性能比较糟糕。显然,MapReduce适用于大规模数据集的并行运算。
运行流程
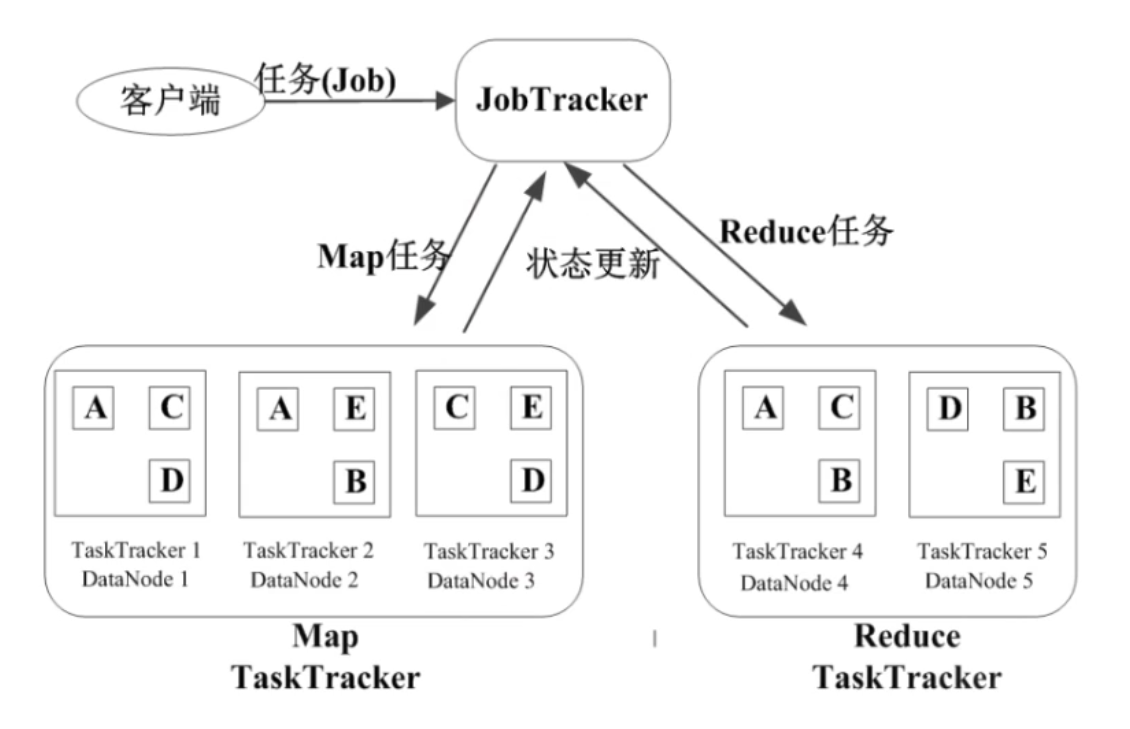
可以类比在HDFS中的结构设计,JobTracker近似于NameNode,而TaskTracker近似于DataNode。实际上它们确实是一类节点,这样也能保证数据传输的稳定性。JobTracker有如下职责:
-
作业调度(FIFO之类的)
-
分配任务、监控任务的执行进度
-
监控TaskTracker的状态
而TaskTracker反而比较简单:
-
执行Map和Reduce的任务
-
汇报任务状态
MapReduce的容错机制主要是重复执行(先不管对不对,重复执行四遍再说)和推测执行(对于执行慢的任务,新建一个TaskTracker执行相同任务,选两者中最先完成的结果,并终止还没完成的任务)。

















 1809
1809

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









