 手机淘宝性能与稳定性治理
手机淘宝性能与稳定性治理




 手机淘宝通过建立高可用度量指标,治理性能与稳定性问题,包括主线程卡顿、内存泄露、资源泄露等,利用自动化框架和数据平台,以及热修复和开发流程管理,全面提升用户体验。
手机淘宝通过建立高可用度量指标,治理性能与稳定性问题,包括主线程卡顿、内存泄露、资源泄露等,利用自动化框架和数据平台,以及热修复和开发流程管理,全面提升用户体验。
手机淘宝高度重视手机用户的稳定性和性能,通过高可用的度量指标的建立,稳定性和性能的治理,自动化和数据平台的建设以及热修复和开发流程管理,开发了一套系统化的解决方案及平台EMAS-MOTU,全方位的提升手机淘宝稳定性和性能。
查看视频或阅读本文,内容根据淘宝技术团队非台在2018安卓绿色联盟开发者大会现场的演讲整理而成。
1 高可用的定义和度量指标
移动端高可⽤旨在通过设计关键的度量指标,以期望能够客观反映和量化用户在使⽤过程的真实感受,同时通过指标, 建⽴一系列的工具和平台,从线下到线上快速发现、分析、 定位和解决包括稳定性、性能、功能等各类问题,以进一步提升用户体验的系统化的解决方案。
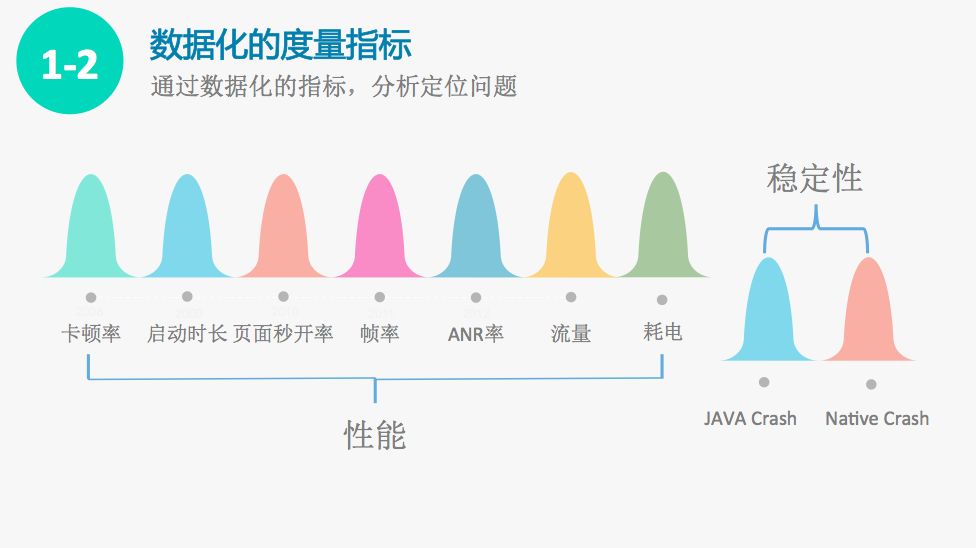
度量指标由性能度量指标和稳定性两大度量指标。性能度量指标由七个部分组成,分别是卡顿率、启动时长、页面秒开率、帧率、ANR率、流量、耗电。稳定性度量指标主要是Crash率,分为JAVA Crash率和Native Crash率。
2 性能和稳定性治理
第一,性能治理。首先介绍我们经常遇到的主线程卡顿治理。主线程卡顿是因为主线程的消息超过某个阈值,从而导致了页面的丢帧,对这个问题是怎么处理的呢?手淘把主线程消息的分发机制从底层接管过来,这样就能知道每条消息的分发耗时以及消息类型,从而快速定位触发主线程卡顿的业务开发。另外一个问题是我们在使用系统的SharedPreferences的时候,发现一些页面跳转的时候导致界面ANR。后面我们通过阅读系统原码,发现它在做Receiver 或者Service的时候会强制把所有SharedPreferences apply时的内容写入文档,导致ANR,所以针对这个问题,我们重写了SharedPreferences,提升了性能,把因SharedPreferences导致的ANR的问题降了下来。
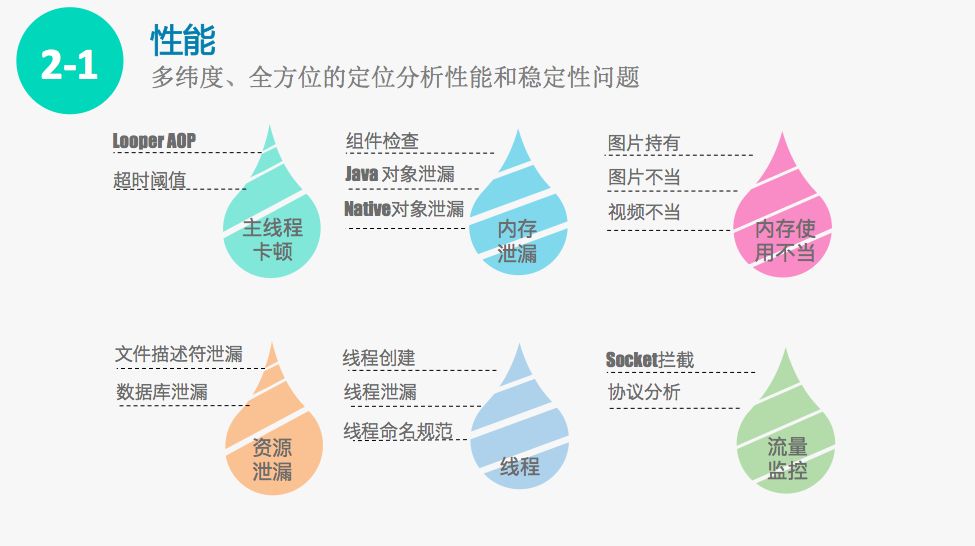
第二,内存泄露治理。内存泄露这块手淘花了大量的时间。一方面我们把系统底层组件的生命周期接管起来,当组件的生命周期销毁的时候,这个对象不应该再被使用,那么我们把它进行一个WeakReference的引用,那么当基期事件触发的时候,我们就知道该对象已经泄漏了。通过这种方式反馈给开发同学。另一方面,我们在Native这一层做了更细致的实现。我们把操作系统底层的malloc和free的方法进行Hook,计算出每一个so在处理内存时候的情况,如果malloc的大小减去free的大小的值超过了白名单中大小,我们认为这个行为是内存泄漏行为,我们会把它交给对应的so同学去排查处理。
第三,内存使用不当治理。我解释一下内存使用不当的概念,当我们开发一个view的时候,它的大小是100×100,但是我们使用的是200*200甚至更大的bitmap。什么时候下会发生这种场景呢?比如是在系统drawable目录下放了一张高清的图片,但在高清的设备上由于系统自身的原理,它会对它进行拉伸。比如在华为P20上展示这张图片,它可能会被拉伸成400×400。这时候原本只需要单位1的内存(100*100),变成单位16的内存(400*400),内存的浪费率达到90%以上。针对这种情况,我们做了一个内存使用不当插件进行排查。视频也同样存这种问题,我们认为没有必要在低分辨率设备上播放高质量的视频。因为播放高质量的视频并不会给用户带来更好的体验,反而可能让他的设备出现卡顿等性能问题。还有就是图片持有的问题,当页面已经沉入栈底的时候,我们建议最好不要保留之前页面的图片。这样你有足够的内存给后面在前台的页面使用。否则随着页面层级的不断深入,很快就会出现OOM的情况。
第四,资源泄露治理。我们主要是接管了系统底层的open和close两个native方法函数。当它的open和close并没有成对出现,并且它的业务并不是伴随整个应用生命周期的时候(伴随整个生命周期的文件有白名单),我们认为它的操作是存在资源泄漏情况的。所以,我们会把该异常行为告诉对应的开发同学去判断否存在潜在的资源泄漏情况。同时,数据库的治理也采用了这套方案。
第五,线程问题治理。线程问题很复杂,我们在做线程创建的时候会触发一些意想不到的问题,比如Out Of Memory error。Out Of Memory error可能是由线程创建失败导致的。基于这些问题,我们对线程创建进行了接管。业务在创建时,我们会对它的方法调用栈进行聚类。这个时候就知道每个业务创建的线程数量,以及线程创建是否合理,不合理的线程创建会提示开发同学修改。这个时候建议大家,在创建线程的时候一定要有规范的线程命名,以便快速定位具体的业务方。
第六,流量监控治理。我们主要是通过接管Socket协议,分析协议头部获取请求和回流数据内容的大小信息,如有异常,可以让开发同学定位解决。同时也可以监听后台流量行为,观察APP切到后台以后是否还有大量的网络请求。
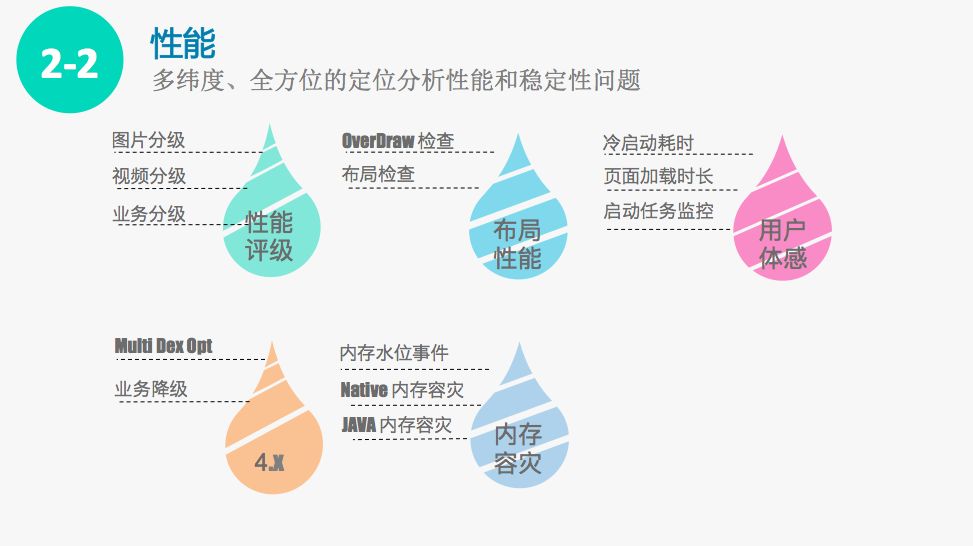
第七,设备评级。根据安卓设备百花齐放现状,我们对不同的设备采取了计分的方法进行评级,根据设备分数采用不同的策略,展示相应的图片、视频和业务,给用户带来最佳的性能体验。我们这个设备评级方案可以给开发同学提供指导建议,更好的展现业务形态。
第八,布局性能。在开发的过程中,常常要通过HierarchyViewer的方法检查布局结构是否合理。所以我们自己写了一套算法,这套算法可以检查页面结构是否合理,页面层级是否过深、页面层级是否还有继续优化的空间。同时我们还实现了一套OverDraw的算法,给开发同学提示具体哪个层级可以优化,怎么样的降层级,怎么样解决OverDraw的问题。
第九,用户体验的优化。我们很关注用户使用APP的情况,包括启动时间、每个页面的打开耗时,我们通过监控启动时各个子任务的耗时,通过这些信息快速的分析每一次发版质量变化是由哪些具体原因导致的。
第十,4.X设备的体验优化。随着产品功能越来越丰富和产品体积逐渐的壮大,4-X设备出现了multidex越来越慢的情况。基于这个现象,我们把谷歌的 support multidex包进行了重构改造。经过重构以后,对4.X设备的Dex加载随着Dex越来越多,改造后的support multidex方案, dex数量越多,它的提升性能越好。
第十一,内存容灾。内存是我们一直很关注的问题。我们希望能做到用户使用当前页面的时候,如果发生内存不够的情况,后台的页面可以快速释放内存资源,为前台页面服务。于是我们开发了内存容灾插件,这个插件会监听JVM的GC事件以及轮询物理页表计算实际使用物理内存,通过这个计算给我们的业务方发送对应的内存水位事件,如果是属于非常高危的内存事件,就可以让后台快速的释放缓存资源,从而为可视的页面提供更好的服务。
稳定性的治理主要是两部分,Java的Crash和Native的Crash。Java Crash治理,我们是通过接管 UncaughtExceptionHandler,拿到具体的Java Crash的信息及它的堆栈。在JAVA Crash这块还有一个经常遇到的OOM的情况,OOM问题的发生一方面是由于我们虚拟机的内存真的不够,另一方面还可能是线程创建失败,这个可以基于我上面讲到的线程创建插件来解决的。Native Crash治理,我们是通过捕获信号量的方式,当Native发生异常的时候,我们会创建一个子进程,通过ptrace的方式去dump Native Crash上下文的线程信息。 基于上面讲到的性能治理方式,我们也可以知道OOM的Native Crash问题可以通过malloc和free的接管,定位具体是哪个SO导致这个问题的根因。
3 自动化框架和数据平台
以下是手机淘宝自动化测试演示视频。
上边是用户手势操作的过程-录制脚本
下边是脚本回放的过程-回放脚本
这套自动化测试框架的优点在于可以通过手势实时的生成可执行的自动化脚本。我们将这套技术应用在暴力测试,通过不断重复的回放同一个脚本去发现潜在的性能稳定性问题,包括内存泄漏、线程泄漏、资源泄漏等等。同时,我们把常规的测试用例通过这套脚本去执行,它能很好的解决P0P1的常规业务的回归。
我们的性能稳定性数据平台,由四个模块组成,用来展示各个维度的数据监控。
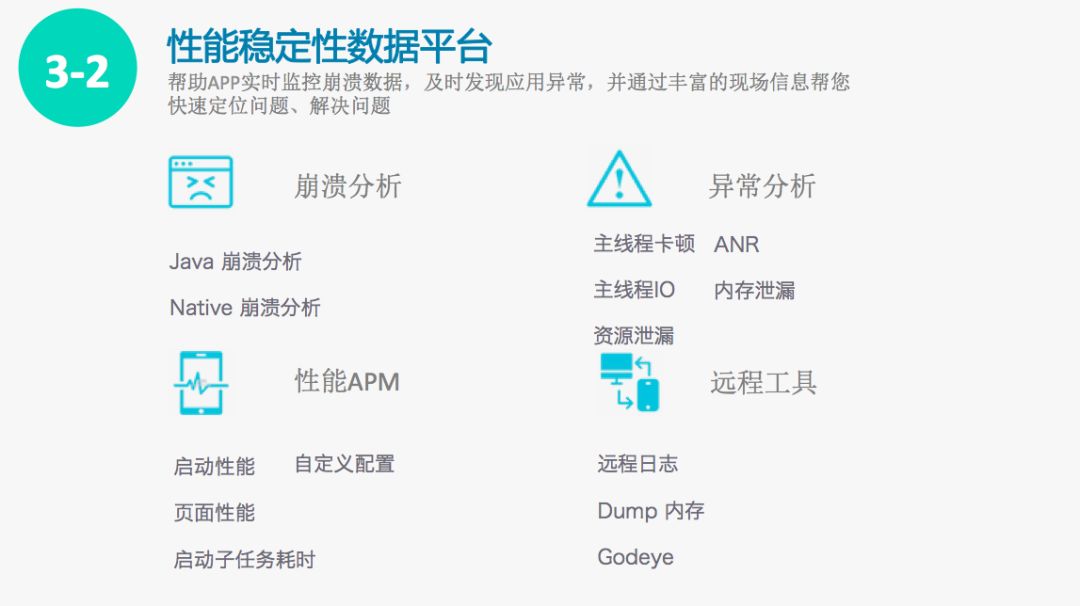
第一个模块是崩溃分析,主要是JavaCrash和NativeCrash分析,JAVA Crash包含了Crash当时的调用栈,当前的页面、用户历史访问页面、当前的内存水位以及logcat信息,帮助开发同学快速分析Java崩溃的原因,从而快速解决问题。Native崩溃主要包含了崩溃的信号量、崩溃使用的调用栈、其他线程的调度栈,logcat信息。以及已加载的SO信息,通过这些信息,可以让开发同学快速的发现Native崩溃原因。
第二个模块是异常分析,各个性能维度的指标会在这里展示,主线程卡顿主要是哪条消息超过了阈值,它的调用栈是什么样子的。ANR展示的主要是/data/anr下的文件信息,发生ANR的现场是什么样子的。主线程IO这块展示的是主线程操作IO的一些调用栈以及它的耗时。内存泄露这块分两部分,JAVA泄露组件的名称,Native这块主要是泄露的so的名称。通过这两部分可以快速的定位内存泄露的原因。资源泄露这块开发同学调用资源open时候的调用栈。
第三模块是性能APM,启动性能我们监控了用户点击图标到真正进入页面可视可交互的时间。页面性能是从点击页面图表到下一个页面真正可视可交付的时间。我们监控启动所有阶段的子任务的耗时,通过数据变化决策版本的发布是否符合质量标准。如果符合质量标准,可以发布。如果不符合质量标准,我们再进一步分析子任务耗时,具体是哪些任务导致不能正常发布。快速的定位分析,最终解决问题。我们同样把数据能力开放给各个业务,业务可以通过他们个性化的自定义的需求配置他们自己想要的性能报表。
第四模块是远程工具,远程工具主要是针对特殊用户的特殊案例,当线上用户向舆情平台反馈设备存在某一个性能问题的时候,通过这个工具,快速的从用户那里获取日志信息、dump内存信息和每个方法的耗时信息,帮助快速分析原因,从而给出解决方案。
4 热修复和开发流程
热修复有三个场景,第一个场景是代码不够健壮,导致APP崩溃。针对这个问题,我们开发了Dexpatch框架,可以实时的快速的对线上问题进行修复。第二个问题类型是功能不符合项目预期。比如,我们要搞一个活动,但这部分活动的功能没有正式上线,这个时候我们开发了Atlas动态容器框架,可以支持业务同学快速上线新功能。第三部分是启动时未正常使用网络的崩溃问题。网络未初始化会导致Dexpatch和Atlas动态容器容器无法发挥作用,于是我们开发了一个安全模式,为启动时异常做及时修复。
接下来讲开发流程,主要是四个部分。一个是开发测试阶段,这个时候会有代码静态扫描,以及测试用例的覆盖。紧接着是集成阶段,集成的时候,我们会对历史问题进行回归。通过历史问题的跟踪,看这次集成过程中是否已经把历史的问题给修复了。如果没有的话,我们会对此次的集成设置卡口,直到它把历史问题给解决掉,从而做到持续集成的目的。第三部分是智能灰度,我们这边自己开发了智能灰度机器人,它的灰度策略由上一次灰度的体量及稳定性能数据来决策。如果稳定性和性能数据报表符合预期,智能灰度机器人会逐渐放大灰度的用户量,直到正式发布为止。整个过程中某个模块有异常行为的时候,智能机器人就会报警给某个模块的开发同学,以便快速定位稳定性性能不能达标的具体原因。如果发版正常情况,则可以通过这种方式直接发版。最后,线上问题的跟踪。版本正式上线后数据平台会实时的展示线上数据。拿到这些数据,可以进一步的做后续操作。如果出现了异常情况,我们的数据平台也会对开发同学进行告警,让他快速的跟进这个问题,决策是否要对它进行及时的热修复。
推荐阅读:


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









