




 Volley中的ByteArrayPool是一个管理字节数组回收和重用的类,通过避免频繁创建和销毁字节数组来提高网络请求性能。它维护了两个列表来协调缓冲区的分配和回收,并通过trim()方法确保不超过最大缓冲区大小。当需要缓冲区时,从池中获取或创建新的;使用完毕后,返回缓冲区以便重用。
Volley中的ByteArrayPool是一个管理字节数组回收和重用的类,通过避免频繁创建和销毁字节数组来提高网络请求性能。它维护了两个列表来协调缓冲区的分配和回收,并通过trim()方法确保不超过最大缓冲区大小。当需要缓冲区时,从池中获取或创建新的;使用完毕后,返回缓冲区以便重用。
Volley源码解析:ByteArrayPool(缓冲区池)
查看Volley的源码时,我们会发现Volley需要实现NetWork类,也就是具体实现网络请求的类。Volley中有一个默认的实现类
BasicNetwork。
BasicNet类的一些局部变量
-
- private static final int DEFAULT_POOL_SIZE = 4096;//用于指定缓冲区的最大容量
-
- @Deprecated protected final HttpStack mHttpStack;//已经被废弃,原来的协议栈
-
- private final BaseHttpStack mBaseHttpStack;//新的协议栈–基于BaseHttpStack抽象类
-
- protected final ByteArrayPool mPool;//缓冲区池
BasicNet类的构造方法
public BasicNetwork(BaseHttpStack httpStack) {
// If a pool isn't passed in, then build a small default pool that will give us a lot of
// benefit and not use too much memory.
this(httpStack, new ByteArrayPool(DEFAULT_POOL_SIZE));
}
/**
* @param httpStack HTTP stack to be used
* @param pool a buffer pool that improves GC performance in copy operations
*/
public BasicNetwork(BaseHttpStack httpStack, ByteArrayPool pool) {
mBaseHttpStack = httpStack;
// Populate mHttpStack for backwards compatibility, since it is a protected field. However,
// we won't use it directly here, so clients which don't access it directly won't need to
// depend on Apache HTTP.
mHttpStack = httpStack;
mPool = pool;
}
这里的两个构造方法均为未废弃的方法,可以看到,在默认情况下,BasicNetwork将指定ByteArrayPool作为缓冲区池,今天我们解析的就是ByteArrayPool的源码。
ByteArrayPool源码解析
什么是ByteArrayPool:
ByteArrayPool 是 Volley 库中的一个类,用于管理字节数组的回收和重用。在网络请求过程中,Volley 库通常需要读取和写入字节数组。为了避免频繁地创建和销毁字节数组,Volley 使用 ByteArrayPool 来管理字节数组的分配和回收,从而提高性能并减少内存占用。
ByteArrayPool 维护了一组不同大小的字节数组池。当需要一个字节数组时,它会从对应大小的池中获取一个可用的数组,如果没有可用的数组,则会创建一个新的数组。当不再需要使用一个字节数组时,它会将该数组还回对应大小的池中以供重用,从而避免频繁地创建和销毁字节数组。
使用 ByteArrayPool 可以有效地减少字节数组的创建和销毁,从而提高网络请求的性能和稳定性。
总结下来,就是说这个缓冲区池就是用来获取缓冲区的,特殊之处在于它可以自动管理其内部的缓冲区的分配和回收以实现较小的开销。
ByteArrayPool中的局部变量
-
- private final List<byte[]> mBuffersByLastUse = new ArrayList<>();//根据使用时间排列的可用缓冲区
-
- private final List<byte[]> mBuffersBySize = new ArrayList<>(64);//根据大小排列的可用缓冲区
-
- private int mCurrentSize = 0;//当前可用缓冲区总大小
-
- private final int mSizeLimit;//最大缓冲区大小–通过之前的BasicNetwork的构造来说,默认为4096B,也就是4K
-
5.比较器–根据缓冲区大小来比
protected static final Comparator<byte[]> BUF_COMPARATOR = new Comparator<byte[]>() { @Override public int compare(byte[] lhs, byte[] rhs) { return lhs.length - rhs.length; } };
以上就是五个ByteArrayPool中的常量,对了既然是ByteArrayPool,那么其缓冲区的具体实现肯定是Byte类型。你可能会疑惑为什么有两个List<Byte> ,实际上前两个List是用来协调以维护同一个可用缓冲区的。
什么是ByteArrayPool中的可用缓冲区
ByteArrayPool不仅可以分配缓冲区给调用方,同时也会将调用方的缓冲区回收,当回收的缓冲区大小并没有超过最大缓冲区的大小的时候,ByteArrayPool就会将其存入内部以方便下一个调用方获取,这样可以省去重新分配byte数组的开销。
ByteArrayPool中的方法
由于整个类的内容不是很多,接下来就先分析其中的方法,最后再画流程图。
1.构造方法 public ByteArrayPool(int sizeLimit)
public ByteArrayPool(int sizeLimit) {
mSizeLimit = sizeLimit;
}
构造方法只做了一件事:确定最大缓冲区的大小。
2.给调用方返回缓冲区public synchronized byte[] getBuf(int len)
public synchronized byte[] getBuf(int len) {
for (int i = 0; i < mBuffersBySize.size(); i++) {
byte[] buf = mBuffersBySize.get(i);
if (buf.length >= len) {
mCurrentSize -= buf.length;
mBuffersBySize.remove(i);
mBuffersByLastUse.remove(buf);
return buf;
}
}
return new byte[len];
}
该方法是用来给调用方返回缓冲区的,该方法接收需要的缓冲区大小。如果内部有可用的缓冲区可以满足需求,那么就将该缓冲区从可用缓冲区池中移除,在内部维护缓冲区池的两个List中将其移除,更新可用缓冲区的大小,并且将其返回给调用方。如果内部没有满足要求的可用缓冲区,就直接返回一个指定大小的byte数组。
3.从调用方回收缓冲区public synchronized void returnBuf(byte[] buf)
public synchronized void returnBuf(byte[] buf) {
if (buf == null || buf.length > mSizeLimit) {
return;
}
mBuffersByLastUse.add(buf);
int pos = Collections.binarySearch(mBuffersBySize, buf, BUF_COMPARATOR);
if (pos < 0) {
pos = -pos - 1;
}
mBuffersBySize.add(pos, buf);
mCurrentSize += buf.length;
trim();//trim方法可以先看后面--检查当前可用缓冲区大小
}
该方法首先会检查回收的缓冲区大小是不是符合要求,即不为空且小于等于最大缓冲区大小。若不符合要求则不作处理。若符合要求就会操作那两个维护缓冲区池的List:在mBuffersBySize(按缓冲区大小排列)中找到合适的位置并且插入,在mBuffersByLastUse(按最近使用时间排列)加到尾部(越靠近尾部说明越最近用过)。然后更新可用缓冲区的大小,最后调用trim方法检查当前可用缓冲区大小并采取操作。
4.检查可用缓冲区大小 private synchronized void trim()
private synchronized void trim() {
while (mCurrentSize > mSizeLimit) {
byte[] buf = mBuffersByLastUse.remove(0);
mBuffersBySize.remove(buf);
mCurrentSize -= buf.length;
}
}
该方法是用来检查当前可用缓冲区的大小的,如果当前总可用缓冲区大小超过了最大缓冲区大小,那么将最久未使用的缓冲区移除,并且更新当前可用缓冲区大小。
ByteArrayPool维护流程
可能上面几个方法看下来还是不太清楚,下面是具体的维护流程图:
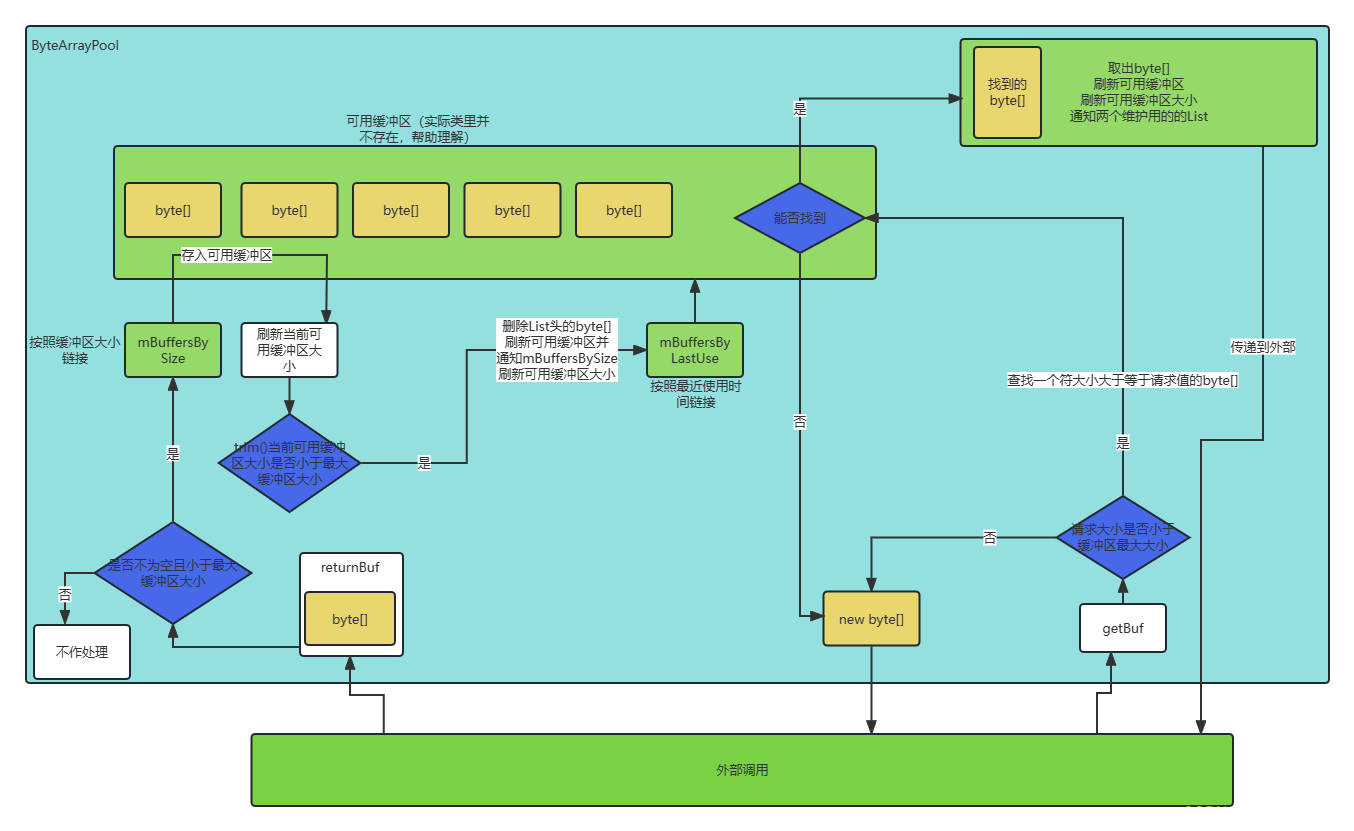
这个流程不是真正的流程,但是可以帮助理解整个维护的原理,图中的可用缓冲区实际上是由两个维护队列共同实现的

















 581
581

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









