






智能算法–遗传算法(1-1)
一、标准遗传算法基本概念
标准遗传算法(Standard Genetic Algorithm, SGA)是由美国J.H. Holland教授与他的同事和学生于1975年研究出的遗传算法理论和方法, 20世纪60年代中期, Holland提出了位串编码技术。这种编玛既适用于变异操作,又适用于交叉操作,并强调将交叉作为主要的遗传操作。随后,他将该算法应用到自然和人工系统的自适应行为的开究中. Holland早期有关遗传算法的许多概念一直沿用至今,遗传算法通用的编码技术和简单有效的遗传操作为其后来的成功应用和广泛应用奠定了基础。
遗传算法使用群体搜索技术,通过对当前群体施加选择、交叉、变异等一系列遗传操作,从而产生出新一代的群体,并逐步使群体进化到包含或接近最优解的状态.
在遗传算法中,将n维决策向量 X = [ x 1 , x 2 , … , x n ] T X=[x_1, x_2, \dots, x_n]^T X=[x1,x2,…,xn]T用n个记号 X i ( i = 1 , 2 , … , n ) X_i(i=1,2,\dots,n) Xi(i=1,2,…,n)所组成的符号串 X X X表示。
把每一个 X i X_i Xi ,看作一个遗传基因,它的所有可能取值就称为等位基因,这样, 就可看作由 n n n个遗传基因所组成的一个染色体。一般情况下,染色体的长度是固定的,但对一些问题来说它也可以是变化的。
根据不同的情况,这里的等位基因可以是一组整数,也可以是某一范围内的实数,或者是一个纯粹的记号。最简单的等位基因是由0或1的符号串组成的,相应的染色体就可以表示为一个二进制符号串。这种编码所形成的排列形式是个体的基因型,与它对应的殖是个体的表现型。染色体 X X X也称为个体 X X X,对于每一个个体 X X X,要按照一定的规则确定其适应度。个体的适应度与其对应的个体表现型 X X X目标函数值相关联, X X X越接近于目标函数的最优点,其适应度越大;反之,适应度越小。
在遗传算法中,决策向量 X X X组成了问题的解空间。对问题最优解的搜索是通过对染色体 X X X的搜索过程来完成的,因而所有的染色体就组成了问题的搜索空间。
生物的进化过程主要是通过染色体之间的交叉和染色体基因的变异来完成的。与此相对应,遗传算法中最优解的搜索过程正是模仿生物的这个进化过程,进行反复迭代,从第代群体
P
(
t
)
P(t)
P(t) ,经过一代遗传和进化后,得到第
(
t
+
1
)
(t+1)
(t+1)代群体
P
(
t
+
1
)
P (t+1)
P(t+1)。这个群体不断地经过遗传和进化操作,并且每次都按照优胜劣汰的规则将适应度较高的个体更多地遗传到下一代,这样最终在群体中将会得到一个优良的个体
X
X
X,达到或接近于问题的最优解。![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZjenztMB-1643374093120)(image-20220123090538720.png)]](https://i-blog.csdnimg.cn/blog_migrate/cdeed3a7d77d32062c90be3af2aa8a4d.png)
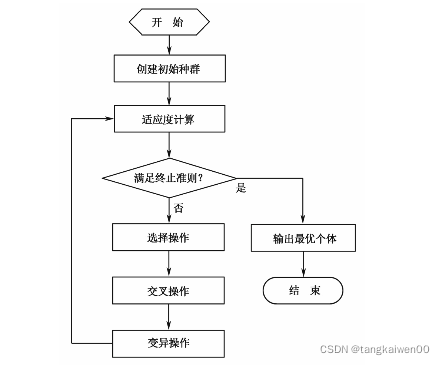
二、遗传算法的运算流程

三、关键参数说明

四、标准遗传算法代码实现
GeneticAlgorithm.m
第19-22行二进制编码公式为: L = l o g 2 ( b − a e p s + 1 ) L=log_2(\frac{b-a}{eps}+1) L=log2(epsb−a+1),其中 [ a , b ] [a,b] [a,b]是自变量范围, e p s eps eps是要求的精度。有多个自变量时,编码长度为每个自变量编码长度之和。
%% GeneticAlgorithm
clear;clc
%% 可视化:画出目标函数图像
f =@(x) 11*sin(6*x) + 7*cos(5*x);
ezplot(f)
hold on
h = plot(0,0,'*');
%% 遗传算法的参数
varnum = 1; % varnum 变量个数
n = 200; % n 种群大小
lb = -pi; % lb ub 变量范围
ub = pi;
eps = 1e-2; % eps 精度
pc = 0.9; % 交叉概率 pc
pm = 0.01; % 变异概率 pm
maxgen = 200; %最大迭代次数
%% 初始化种群
for i = 1:varnum
L(i) = ceil(log2((ub(i) - lb(i)) / eps + 1)); %确定染色体长度
end
LS = sum(L);%总位长
pop = randi([0 1],n,LS); %随机生成n条长度为LS的二进制染色体
spoint = cumsum([0 L]); %spoint记录多个自变量转化为二进制染色体时候的节点
for iter = 1:maxgen %% maxgen最大迭代代数,maxgen大循环
%% 将二进制转化为十进制
for i = 1:n
for j = 1:varnum %varnum变量个数
startpoint = spoint(j) + 1;
endpoint = spoint(j+1);
% 调用decode函数
real(i,j) = decode(pop(i,startpoint:endpoint),lb(j),ub(j));
end
end
%% 计算适应度值
fitvalue = fitnessfun(real);% 调用fitnessfun函数
fval = objfun(real);
h.XData = real;
h.YData = fval;
pause(0.01)
%% 选择
[dad,mom] = selection(pop,fitvalue);
%% 交叉
newpop = crossover(dad,mom,pc);
%% 变异
newpop = mutation(newpop,pm);
pop = newpop;
end
%% 上部大循环的结果的提取
for i = 1:n
for j = 1:varnum
startpoint = spoint(j) + 1;
endpoint = spoint(j+1);
real(i,j) = decode(pop(i,startpoint:endpoint),lb(j),ub(j));
end
end
fitvalue = fitnessfun(real);
[bestfitness, bestindex] = max(fitvalue)
bestindividual = real(bestindex,:)
fval = objfun(bestindividual)
plot(bestindividual,fval,'*')
decode.m
解码函数:将二进制数据装换为十进制数据
第10行代码公式为: x = a + ( b − a ) × X ( 2 L − 1 ) x=a+(b-a) \times \frac{X}{(2^L-1)} x=a+(b−a)×(2L−1)X,解释为把 ( b − a ) (b-a) (b−a)按照 X ( 2 L − 1 ) \frac{X}{(2^L-1)} (2L−1)X比例映射到原来的变量范围 [ a , b ] [a,b] [a,b]上。
其中第6-9行代码,是把 0101 … 01 0101\dots01 0101…01 二进制装换为十进制 [ X ] [X] [X]。
function real = decode(pop,lb,ub)
%% pop 种群
%% varnum 变量个数
[~,col] = size(pop);
for j = col:-1:1
temp(j) = 2^(j-1)*pop(j);
end
temp = sum(temp);
real = lb + temp * (ub - lb)/(2^col-1);
end
fitnessfun.m
适应度函数尺度变换:因为使用轮盘赌选择方法,要求概率至少要大于等于0,所以要把原来目标函数值 f ( x ) f(x) f(x)尺度变换到 F ( x ) F(x) F(x)。
求最大值问题,线性适应度函数:$ \begin{aligned} F(x) = \begin{cases} f(x)+C_{min},& f(x)+C_{min}>0\\ 0, & f(x)+C_{min} \leq0 \end{cases} \end{aligned} $
求最小值问题,线性适应度函数:$ \begin{aligned} F(x) = \begin{cases} C_{max}-f(x),& C_{max}-f(x)>0\\ 0, & C_{max}-f(x) \leq0 \end{cases} \end{aligned} $
function fitvalue = fitnessfun(x)
Cmin = 0.01;
[row,~] = size(x);
for i = 1:row
fval = objfun(x(i,:));
if fval + Cmin > 0
fitvalue(i) = fval + Cmin;
else
fitvalue(i) = 0;
end
end
selection.m
选择操作:使用轮盘赌的方式选择出n(种群个数)个父代,随机选取母代。
function [dad,mom] = selection(pop,fitvalue)
%% 计算累加概率
PP = cumsum( fitvalue ./ sum(fitvalue) );
[row, ~] = size(pop);
%% 选择出row个个体
for i = 1:row
for j = 1:row
r = rand;
if r <= PP(j)
dad(i,:) = pop(j,:);
break;
end
end
mom(i,:) = pop(randi([1 row]),:);
end
crossover.m
交叉操作:产生一个随机数,如果这个随机数小于 P c P_c Pc(交叉概率),就进行父代和母代的交叉操作,否则没有交叉,下一代直接是父代基因型。
父代与母代交叉的步骤:随机选择一个交叉点,交叉点之前的是父代基因型,交叉点之后是母代基因型。
function newpop = crossover(dad,mom,pc)
[row,col] = size(dad);
for i = 1:row
if rand < pc
cpoint = randi([1 col-1]);
newpop(i,:) = [dad(i,1:cpoint) mom(i,cpoint+1:end)];
else
newpop(i,:) = dad(i,:);
end
end
mutation.m
变异操作:产生一个随机数,如果这个随机数小于 P m P_m Pm(变异概率),就把上一步骤中交叉操作产生的基因型中某一个基因取反(基因型用二进制编码的好处)。
function newpop = mutation(pop,pm)
[row,col] = size(pop);
newpop = zeros(row,col);
for i = 1:row
mpoint = randi([1 col]);
if rand < pm
newpop(i,:) = ~pop(i,mpoint);
else
newpop(i,:) = pop(i,:);
end
end
objfun.m
目标函数: f ( x ) = 11 s i n ( x ) + 7 c o s ( 5 x ) f(x)=11sin(x)+7cos(5x) f(x)=11sin(x)+7cos(5x)
function fval = objfun(x)
fval = 11*sin(6*x) + 7*cos(5*x);
```



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









