









Hadoop实战 一 WordCount
准备工作
这里我们使用 IDEA + Maven 作为演示,做一个简单的单词计数统计
启动虚拟机Hadoop
如何启动以及配置问题见 – Hadoop入门
Windows Hadoop 环境配置
下载 winutils
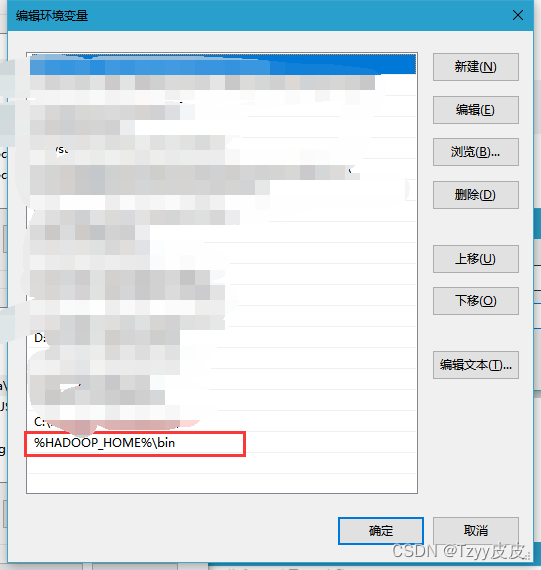
配置环境变量
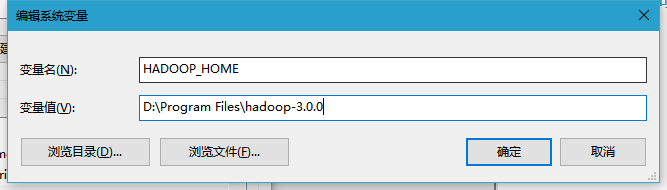
在path里 添加 HADOOP_HOME
准备数据文本
一个非常简单的 txt 文本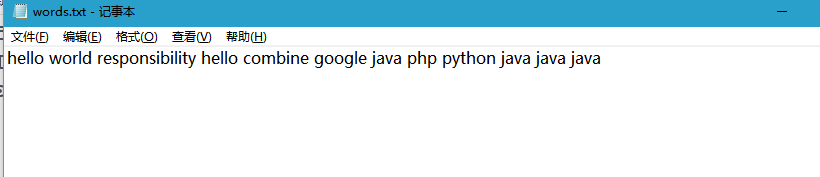
修改Maven pom文件
这里我们添加两个依赖 hadoop-common 以及 hadoop-core
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-core -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.3.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs –>-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.3.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>3.3.1</version>
<scope>provided</scope>
</dependency>
Hadoop配置文件
将 Hadoop 配置文件 拷贝到Java 工程 resources文件夹下
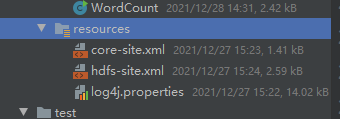
编码环节
Mapper文件
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* Map阶段 通过继承Mapper类 重写map方法实现
* Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> 四个参数解释
* KEYIN:K1 一般为 LongWritable,读取文件时为一次读取一行数据,K1为此行开头与文本开头的偏移量 不重要
* VALUEIN:V1 行数据
* KEYOUT:K2 可自定义 Map处理完成后数据的键的类型
* VALUEOUT:V2 可自定义 Map处理完成后数据的value的类型
* */
public class WcMapper extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 结合文本内容 value 应该为: hello world responsibility hello combine google java php python java java java
String[] words = value.toString().split(" ");
for (String word : words) {
// 将单词作为key 每个单词出现一次 1 作为value
context.write(new Text(word), new Text("1"));
}
}
}
Reduce 文件
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* Reduce阶段 通过继承Reducer类 重写reduce方法实现
* Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT> 四个参数解释
* KEYIN:K2 Map阶段的KEYOUT
* VALUEIN:V2 Map阶段的VALUEOUT
* KEYOUT:K3 可自定义 Reducer处理完成后数据的键的类型
* VALUEOUT:V3 可自定义 Reducer处理完成后数据的value的类型
* */
public class WcReducer extends Reducer<Text, Text, Text, Integer> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
// 此时 Hadoop已经将Key相同的数据进行了合并 例: hello <1,1,1> word <1>
int count = 0; //总数
for (Text value : values) {
count+=Integer.parseInt(value.toString());
}
context.write(key, count);
}
}
Mian方法
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class WordCount {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf,"wordcount");
// 读取方式 一般为 TextInputFormat
job.setInputFormatClass(TextInputFormat.class);
//设置读取文件路径
TextInputFormat.addInputPath(job,new Path("file:///C:\\Users\\Administrator\\Desktop\\Hadoop学习\\words.txt"));
//设置Map文件 以及 K2,V2 类型 对应Map文件里的K2,V2
job.setMapperClass(WcMapper.class);
job.setMapOutputKeyClass(Text.class); // K2
job.setMapOutputValueClass(Text.class); // V2
//设置Reducer文件 以及 K3,V3 类型 对应Reducer文件里的K3,V3
job.setReducerClass(WcReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Integer.class);
// 设置输出方式 一般为TextOutputFormat
job.setOutputFormatClass(TextOutputFormat.class);
//设置输出路径
TextOutputFormat.setOutputPath(job,new Path("file:///C:\\Users\\Administrator\\Desktop\\Hadoop学习\\wordCount"));
//等待任务结束
boolean flag = job.waitForCompletion(true);
System.exit(flag?0:1);
}
}
结果
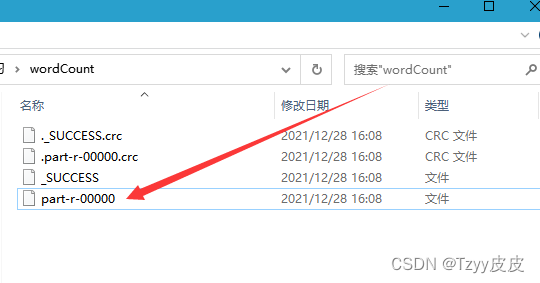
part-r-00000 为最后输出的数据
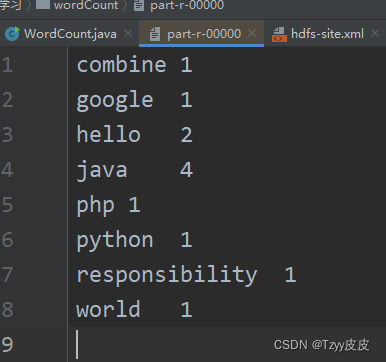
得到预期结果


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









