







 本文深入剖析了Dubbo的工作原理,包括服务的注册与发现、负载均衡策略、通信协议及其扩展机制。重点介绍了Dubbo的SPI机制,允许动态配置实现类,并详细阐述了RPC设计的关键环节,如动态代理、服务发现、负载均衡、序列化等。同时,对比了Dubbo与Spring Cloud的区别,如协议、动态代理、负载均衡和序列化等方面,以及两者所使用的注册中心如Zookeeper、Eureka的特性差异。
本文深入剖析了Dubbo的工作原理,包括服务的注册与发现、负载均衡策略、通信协议及其扩展机制。重点介绍了Dubbo的SPI机制,允许动态配置实现类,并详细阐述了RPC设计的关键环节,如动态代理、服务发现、负载均衡、序列化等。同时,对比了Dubbo与Spring Cloud的区别,如协议、动态代理、负载均衡和序列化等方面,以及两者所使用的注册中心如Zookeeper、Eureka的特性差异。
dubbo 工作原理
- 第一层:service 层,接口层,给服务提供者和消费者来实现的
- 第二层:config 层,配置层,主要是对 dubbo 进行各种配置的
- 第三层:proxy 层,服务代理层,无论是 consumer 还是 provider,dubbo 都会给你生成代理,代理之间进行网络通信
- 第四层:registry 层,服务注册层,负责服务的注册与发现
- 第五层:cluster 层,集群层,封装多个服务提供者的路由以及负载均衡,将多个实例组合成一个服务
- 第六层:monitor 层,监控层,对 rpc 接口的调用次数和调用时间进行监控
- 第七层:protocal 层,远程调用层,封装 rpc 调用
- 第八层:exchange 层,信息交换层,封装请求响应模式,同步转异步
- 第九层:transport 层,网络传输层,抽象 mina 和 netty 为统一接口
- 第十层:serialize 层,数据序列化层
工作流程
- 第一步:provider 向注册中心去注册
- 第二步:consumer 从注册中心订阅服务,注册中心会通知 consumer 注册好的服务
- 第三步:consumer 调用 provider
- 第四步:consumer 和 provider 都异步通知监控中心
dubbo 支持不同的通信协议
- dubbo 协议
dubbo:// - Protocol,filter机制,http、rmi、dubbo等协议
默认就是走 dubbo 协议,单一长连接,进行的是 NIO 异步通信,基于 hessian 作为序列化协议。使用的场景是:传输数据量小(每次请求在 100kb 以内),但是并发量很高,以及服务消费者机器数远大于服务提供者机器数的情况。
为了要支持高并发场景,一般是服务提供者就几台机器,但是服务消费者有上百台,可能每天调用量达到上亿次!此时用长连接是最合适的,就是跟每个服务消费者维持一个长连接就可以,可能总共就 100 个连接。然后后面直接基于长连接 NIO 异步通信,可以支撑高并发请求。
长连接,通俗点说,就是建立连接过后可以持续发送请求,无须再建立连接。
dubbo 负载均衡策略
默认情况下,dubbo 是 RandomLoadBalance ,即随机调用实现负载均衡,可以对 provider 不同实例设置不同的权重,会按照权重来负载均衡,权重越大分配流量越高,一般就用这个默认的就可以了。
算法思想很简单。假设有一组服务器 servers = [A, B, C],他们对应的权重为 weights = [5, 3, 2],权重总和为 10。现在把这些权重值平铺在一维坐标值上,[0, 5) 区间属于服务器 A,[5, 8) 区间属于服务器 B,[8, 10) 区间属于服务器 C。接下来通过随机数生成器生成一个范围在 [0, 10) 之间的随机数,然后计算这个随机数会落到哪个区间上。比如数字 3 会落到服务器 A 对应的区间上,此时返回服务器 A 即可。权重越大的机器,在坐标轴上对应的区间范围就越大,因此随机数生成器生成的数字就会有更大的概率落到此区间内。只要随机数生成器产生的随机数分布性很好,在经过多次选择后,每个服务器被选中的次数比例接近其权重比例。比如,经过一万次选择后,服务器 A 被选中的次数大约为 5000 次,服务器 B 被选中的次数约为 3000 次,服务器 C 被选中的次数约为 2000 次。
这个的话默认就是均匀地将流量打到各个机器上去,但是如果各个机器的性能不一样,容易导致性能差的机器负载过高。所以此时需要调整权重,让性能差的机器承载权重小一些,流量少一些。
举个栗子。
跟运维同学申请机器,有的时候,我们运气好,正好公司资源比较充足,刚刚有一批热气腾腾、刚刚做好的虚拟机新鲜出炉,配置都比较高:8 核 + 16G 机器,申请到 2 台。过了一段时间,我们感觉 2 台机器有点不太够,我就去找运维同学说,“哥儿们,你能不能再给我一台机器”,但是这时只剩下一台 4 核 + 8G 的机器。我要还是得要。
这个时候,可以给两台 8 核 16G 的机器设置权重 4,给剩余 1 台 4 核 8G 的机器设置权重 2。
官网对 LeastActiveLoadBalance 的解释是“最小活跃数负载均衡”,活跃调用数越小,表明该服务提供者效率越高,单位时间内可处理更多的请求,那么此时请求会优先分配给该服务提供者。
最小活跃数负载均衡算法的基本思想是这样的:
每个服务提供者会对应着一个活跃数 active。初始情况下,所有服务提供者的 active 均为 0。每当收到一个请求,对应的服务提供者的 active 会加 1,处理完请求后,active 会减 1。所以,如果服务提供者性能较好,处理请求的效率就越高,那么 active 也会下降的越快。因此可以给这样的服务提供者优先分配请求。
当然,除了最小活跃数,LeastActiveLoadBalance 在实现上还引入了权重值。所以准确的来说,LeastActiveLoadBalance 是基于加权最小活跃数算法实现的。
一致性 Hash 算法,相同参数的请求一定分发到一个 provider 上去,provider 挂掉的时候,会基于虚拟节点均匀分配剩余的流量,抖动不会太大。如果你需要的不是随机负载均衡,是要一类请求都到一个节点,那就走这个一致性 Hash 策略。
SPI机制 拓展机制
spi,简单来说,就是 service provider interface ,说白了是什么意思呢,比如你有个接口,现在这个接口有 3 个实现类,那么在系统运行的时候对这个接口到底选择哪个实现类呢?这就需要 spi 了,需要根据指定的配置或者是默认的配置,去找到对应的实现类加载进来,然后用这个实现类的实例对象。
spi 经典的思想体现,大家平时都在用,比如说 jdbc。
Java 定义了一套 jdbc 的接口,但是 Java 并没有提供 jdbc 的实现类。
但是实际上项目跑的时候,要使用 jdbc 接口的哪些实现类呢?一般来说,我们要根据自己使用的数据库,比如 mysql,你就将 mysql-jdbc-connector.jar 引入进来;oracle,你就将 oracle-jdbc-connector.jar 引入进来。
在系统跑的时候,碰到你使用 jdbc 的接口,他会在底层使用你引入的那个 jar 中提供的实现类。
。在 java.sql 这个包里面 ,我们在连接数据库的时候,一定需要用到 java.sql.Driver 这个接口对吧。然后我好奇的去看了下 java.sql.Driver 的源码,发现 Driver 并没有实现,而是提供了一套标准的 api 接口。
拓展设计理念:
第一点,是核心的组件全部接口化,组件和组件之间的调用,必须全部是依托于接口,去动态找配置的实现类,如果没有配置就用他自己默认的
第二点,提供一种自己实现的组件的配置的方式,比如说你要是自己实现了某个组件,配置一下,人家到时候运行的时候直接找你配置的那个组件即可,作为实现类,不用自己默认的组件了
Driver 其实就类似 Dubbo 提供了接口类 和 默认配置路径,mysql-jdbc-connector.jar根据配置路径 配置实现类,实现接口
设计RPC:
注册中心,服务的注册与发现,负载均衡,通信 nio,序列号 hessian,上下线感知(本地缓存),心跳机制,请求超时,请求重试,请求切换
回答思路:
- 上来你的服务就得去注册中心注册吧,你是不是得有个注册中心,保留各个服务的信息,可以用 zookeeper 来做,对吧。
- 然后你的消费者需要去注册中心拿对应的服务信息吧,对吧,而且每个服务可能会存在于多台机器上。
- 接着你就该发起一次请求了,咋发起?当然是基于动态代理了,你面向接口获取到一个动态代理,这个动态代理就是接口在本地的一个代理,然后这个代理会找到服务对应的机器地址。
- 然后找哪个机器发送请求?那肯定得有个负载均衡算法了,比如最简单的可以随机轮询是不是。
- 接着找到一台机器,就可以跟它发送请求了,第一个问题咋发送?你可以说用 netty 了,nio 方式;第二个问题发送啥格式数据?你可以说用 hessian 序列化协议了,或者是别的,对吧。然后请求过去了。
- 服务器那边一样的,需要针对你自己的服务生成一个动态代理,监听某个网络端口了,然后代理你本地的服务代码。接收到请求的时候,就调用对应的服务代码,对吧。
系统设计的问题,就是让你站在系统设计的角度,来考虑一下,到底如果要设计一个RPC框架,你会如何来考虑
动态代理:比如消费者和提供者,其实都是需要一个实现某个接口的动态代理的,RPC框架的一切的逻辑细节,都是在这个动态代理中实现的,动态代理里面的代码逻辑就是你的RPC框架核心的逻辑
JDK提供了API,去创建针对某个接口的动态代理
调用动态代理对象的方法之后,此时就应该先干一个事情,通过Cluster层的一些组件,服务注册中心,是用什么技术来进行实现呢?往简单了说,服务注册中心也可以是你自己手撸一个,也不难
自己手撸一个,服务去注册,其他服务去拉取注册表进行发现
ZooKeeper,稍微自己上网百度搜索一下,ZooKeeper入门使用教程,基本概念和原理,还有基本的使用,了解一下
Cluster层,从本地缓存的服务注册表里获取到要调用的服务的机器列表
负载均衡,面试突击第一季里,我们分析过Dubbo的负载均衡策略,此时你就可以把那些策略说一说,我要设计多少种策略,从服务的机器列表中采用负载均衡算法从里面选择出来一台机器
选择好了机器,知道了对方的端口号,而且知道你的请求调用,调用哪个Interface的哪个方法,把这些信息交给协议层
把数据组织一下,协议,序列化机制,底层用什么网络通信框架,比如netty,mina现在用的比较少,序列化和反序列化有没有概念,Java基础概念,一个复杂的请求数据序列化成二进制的字节数组
反序列化就是从字节数组变成请求数据结构
按照那个协议的规范对请求数据进行组织,不同的协议,组织出来的数据看起来是不一样的
netty基本的原理
解析完毕了之后,就知道,应该调用自己本地哪个Interface的实现类的哪个方法
这就是一个最最基本的 rpc 框架的思路。
说说Dubbo的底层架构原理?
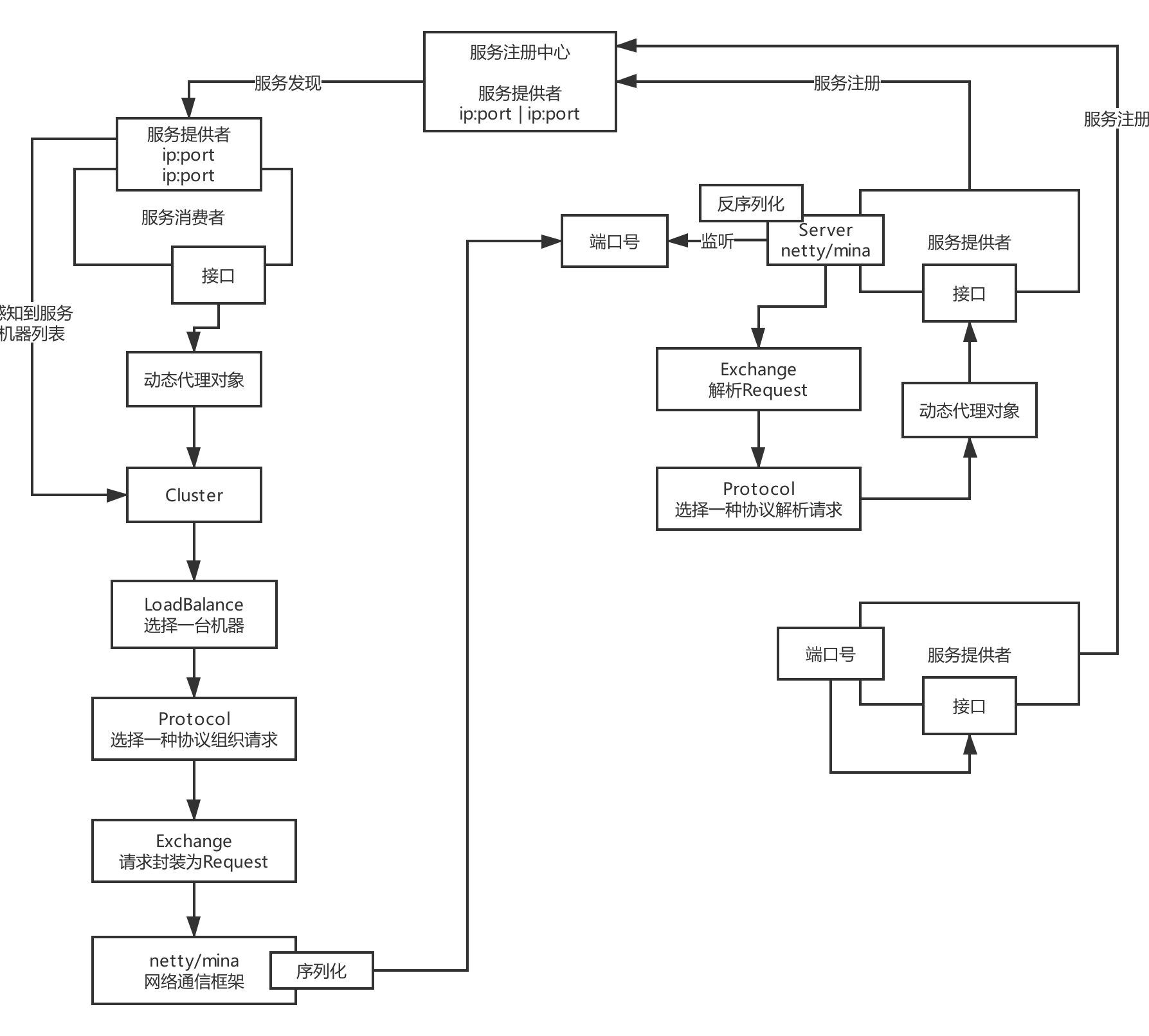
提供接口
服务注册中心:
###消费者
动态代理:Proxy
负载均衡:Cluster,负载均衡,故障转移
注册中心:Registry
通信协议:Protocol,filter机制,http、rmi、dubbo等协议
http、rmi、dubbo
比如说,我现在其实想要调用的是,DemoService里的sayHello接口
你的请求用什么样的方式来组织发送过去呢?以一个什么样的格式来发送你的请求?
http,/demoService/sayHello?name=leo rmi,另外一种样子 dubbo,另外一种样子,interface=demoService|method=sayHello|params=name:leo
信息交换:Exchange,Request和Response
对于你的协议的格式组织好的请求数据,需要进行一个封装,Request
网络通信:Transport,netty、mina
序列化:封装好的请求如何序列化成二进制数组,通过netty/mina发送出去
提供者
网络通信:Transport,基于netty/mina实现的Server
信息交换:Exchange,Response
通信协议:Protocol,filter机制
动态代理:Proxy
总结:
1.提供者和消费者的注册和发现 service 层 config 层
2.提供者和消费者生成代理对象 proxy层
3.通过负载均衡算法 获取 server cluster层
4.根据指定通信协议 封装请求格式 协议 dubbo(默认),rmi,http protocol层
5.通过网络通信框架(netty,mina) 和 序列化协议(hessian(默认),java二进制,) 序列化数据 并发送出去 transport 层
6.生产者 监听 端口 获取到 请求 :1.通过对应协议解析请求,2.数据反序列化 3.通过动态代理在获取对应实现类
说说Dubbo底层的网络通信机制原理!
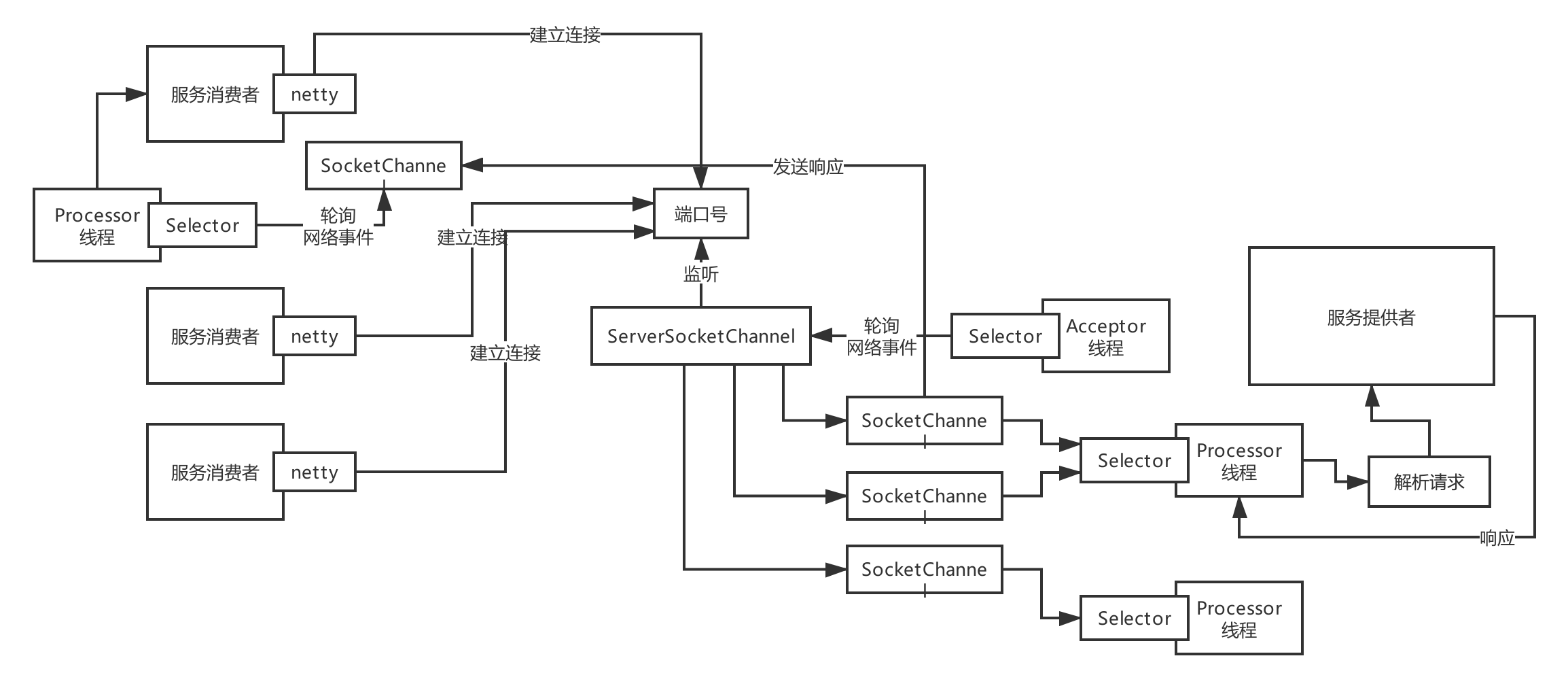
总结:
1.消费者 基于netty和 生产者创建socket连接
2.生产者ServerSocketChannel 监听 连接请求
3.Acceptor线程 会Selector 轮询 ServerSocketChannel 建立Socket连接的请求
4.创建SocketChannel 连接通道, 交给 处理线程 Processor线程(Selector 轮询 是否有请求) 去处理请求
5.生产者 SocketChannel 返回响应 给 消费者的SocketChannel
6.消费者 的处理线程 Processor线程 也在Selector 轮询 SocketChannel 中是否有返回消息
注意:生产者端的一个处理线程Processor 是可以 Selector 轮询 多个SocketChannel 请求通道 实现 多线程 nio 处理 请求
Dubbo 和 Spring Cloud 的不同!!
如果你基于Spring Cloud对外发布一个接口,实际上就是支持http协议的,对外发布的就是一个最最普通的Spring MVC的http接口
feign,他是对一个接口打了一个注解,他一定会针对这个注解标注的接口生成动态代理,然后你针对feign的动态代理去调用他的方法的时候,此时会在底层生成http协议格式的请求,/order/create?productId=1
底层的话,使用HTTP通信的框架组件,HttpClient,先得使用Ribbon去从本地的Eureka注册表的缓存里获取出来对方机器的列表,然后进行负载均衡,选择一台机器出来,接着针对那台机器发送Http请求过去即可
配置一下不同的请求路径和服务的对应关系,你的请求到了网关,他直接查找到匹配的服务,然后就直接把请求转发给那个服务的某台机器,Ribbon从Eureka本地的缓存列表里获取一台机器,负载均衡,把请求直接用HTTP通信框架发送到指定机器上去
Dubbo 是基于自己的配置 生成代理对象,请求协议默认是 dubbo协议,然后通过自己的 负载均衡组件 负载均衡。
底层不同点:
dubbo 比较重 包含了 重试 超时 负载均衡啊 而 feign只是一个远程调用 需要结合其他netflix组件一起使用
1.spring cloud 基于http ,Dubbo 基于 dubbo协议
2.feign是基于springMVC 注解然后扫描这些注解的方式生成动态代理,dubbo是基于自己的配置 生成动态代理
3.负载均衡 是基于ribbon dubbo自己组件封装的
4.dubbo 序列化 使用的是hessain二进制协议: 序列化速度快,数据更小,spring cloud 是HTTP协议 序列化:HttpMessageConverters协议
5.dubbo 并发性能好 nio 异步通信 ,建立socket tcp 长链接 (基于 netty 框架)
RPC框架的选型 影响至 注册中心的选型 以及对比!!!!
1.Dubbo 注册中心 zokeeper nacos, spring cloud 一般是eureka nacos
2.zookeeper 是 只有leader 才能写,eureka是都可以
3.zookeeper cp一致性, eureka 是ap
4.zk,时效性更好,注册或者是挂了,一般秒级就能感知到 eureka 可能要几分钟
5.注册容量:
1.eureka 每个server 都要接收心跳(服务实例多 心跳就多),然后服务上下线 eureka直接也需要互相同步
2.zookeeper 也不适合,因为服务下线 会瞬间通知所有实例,规模大 网络宽带被大量占用


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









