




 本文深入探讨了倒排索引的概念及其在ElasticSearch中的应用,解释了倒排索引如何解决传统数据库在海量数据搜索上的局限性。通过详细分析倒排列表的存储结构、创建及更新策略,读者可以全面理解倒排索引的工作原理。
本文深入探讨了倒排索引的概念及其在ElasticSearch中的应用,解释了倒排索引如何解决传统数据库在海量数据搜索上的局限性。通过详细分析倒排列表的存储结构、创建及更新策略,读者可以全面理解倒排索引的工作原理。
ElasticSearch与关系型数据库:
1、字段关系对应:
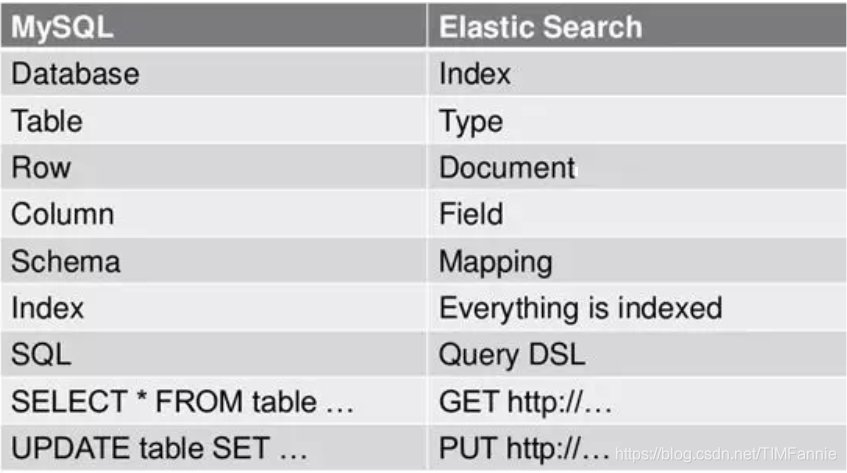
ElasticSearch:
1、倒排索引:
目前市面上的现代搜索引擎索引都是基于倒排索引。
倒排索引概念:
也称作反向索引,用来存储某个单词在一个文档或一组文档中的映射关系。
倒排索引解决的问题:
根据属性值来获取包含该属性值的记录地址。能处理关系型数据库不能处理的高效海量数据搜索,数据操作简单。
倒排列表及其存储结构:
单词及其对应的倒排列表构成字典项,ES根据单词的字典序排列各个字典项。倒排列表包含单词对应的倒排索引,索引包含文档编号DocID、文档单词出现次数TF、单词出现的位置信息。一般倒排索引按照文档编号由小到大排列,故为压缩数据存储量,除第一个索引文档编号外,其余文档编号都可简化为当前文档编号与前一索引文档编号差(正数)。
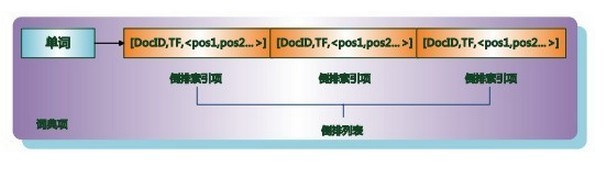
倒排索引创建:
倒排索引通常需要在使用前提前创建好,资源消耗大,但能保证使用时的高效。
有两种构建方法:简单法与合并法 ,合并法对海量数据优势明显,保证的内存空间,故优于简单法。
倒排索引更新:
-
完全重建策略:当新增文档到达一定数量,将新增文档和原先的老文档整合,然后利用静态索引创建方法对所有文档重建索引,新索引建立完成后老索引会被遗弃。此法代价高,但是主流商业搜索引擎一般是采用此方式来维护索引的更新(这句话是书中原话)
-
再合并策略:当新增文档进入系统,解析文档,之后更新内存中维护的临时索引,文档中出现的每个单词,在其倒排表列表末尾追加倒排表列表项;一旦临时索引将指定内存消耗光,即进行一次索引合并,这里需要倒排文件里的倒排列表存放顺序已经按照索引单词字典顺序由低到高排序,这样直接顺序扫描合并即可。其缺点是:因为要生成新的倒排索引文件,所以对老索引中的很多单词,尽管其在倒排列表并未发生任何变化,也需要将其从老索引中取出来并写入新索引中,这样对磁盘消耗是没必要的。
-
原地更新策略:试图改进再合并策略,在原地合并倒排表,这需要提前分配一定的空间给未来插入,如果提前分配的空间不够了需要迁移。实际显示,其索引更新的效率比再合并策略要低。
-
混合策略:出发点是能够结合不同索引更新策略的长处,将不同索引更新策略混合,以形成更高效的方法。
参考文献:百度百科--倒排索引


















 846
846

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











