







 本文分享了在使用HiBench进行大数据性能测试时的配置体会与技巧,包括关键配置文件的修改、数据大小设置、批量运行样例的方法及自定义测试数据生成流程。
本文分享了在使用HiBench进行大数据性能测试时的配置体会与技巧,包括关键配置文件的修改、数据大小设置、批量运行样例的方法及自定义测试数据生成流程。
1、下载安装
本文主要是本人在使用过程中的配置体会与技巧分享
关键配置/bin/hadoop.conf
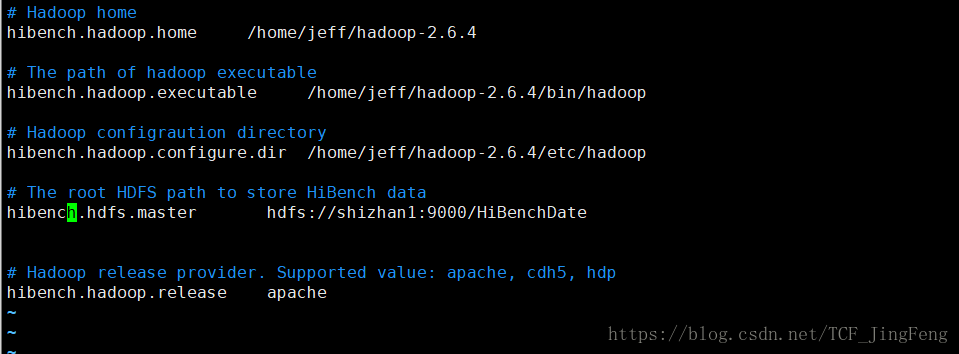
/bin/benchmark.conf
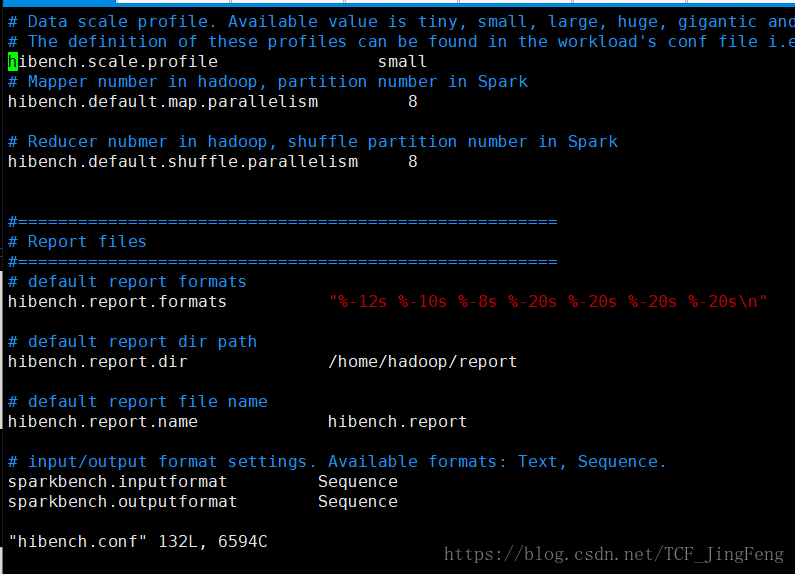
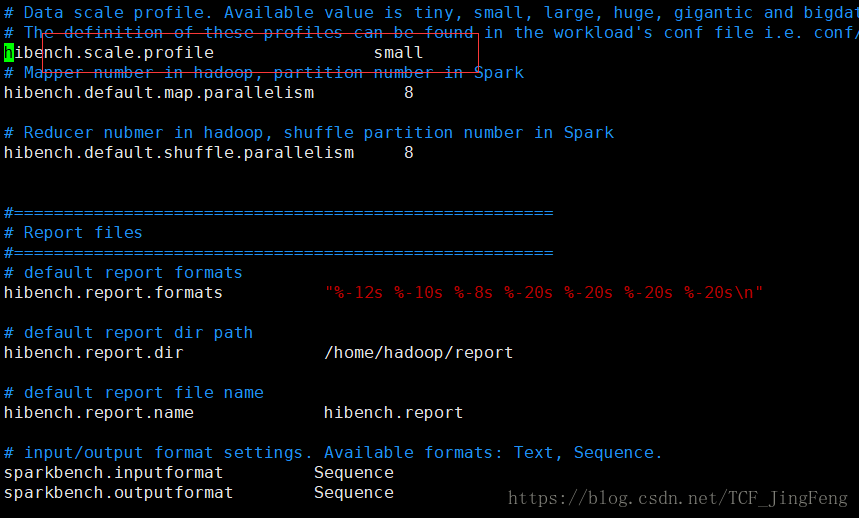
2、数据大小设置
修改/home/jeff/HiBench-master/conf/workloads/micro中的每个样例数据大小,默认有6中
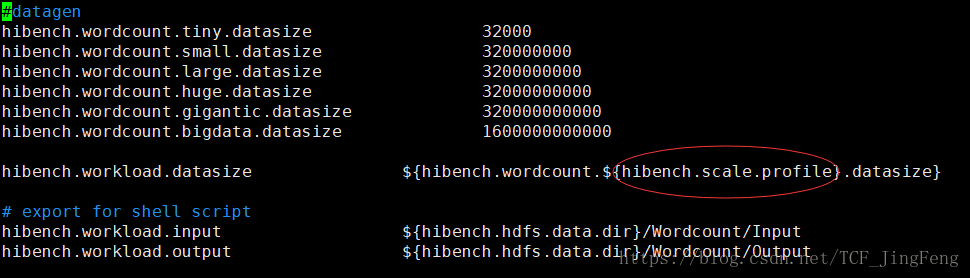
读取的是/home/jeff/HiBench-master/conf/Hibench.conf中的值
3、/bin/run_all.sh可以一次性跑所有样例
设置要跑的样例
编辑/home/jeff/HiBench-master/conf/benchmark.lst保留要想测试的样例
由于实验需求我是要四中样例如下

我只要跑hadoop样例不用spark样例,所以还要删除frameworks.lst中的spark删掉

配置要一次性跑的程序之后
到/home/jeff/HiBench-master/bin中运行./run_all.sh
然后查看report,我的report目录是/home/hadoop/report

4、Hibench说明
其实是用的hadoop自带的测试包来生成各种测试数据。
可以通过运行hadoop jar hadoop-mapreduce-examples-2.6.4.jar teragen 10000 /home/terasotdata,自己测试生成数据
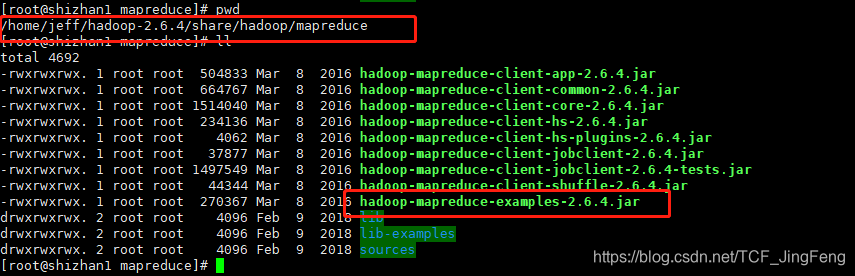
如果要跑单个案例,可以进入

案例目录,先运行./prepare.sh
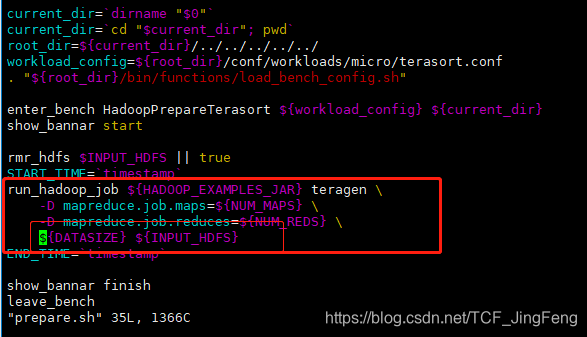
也就是调用上面讲的那个hadoop自带的包生成数据,
再运行./run.sh
也可以在benckmark.lst中注释掉不需要的,然后运行/run_all.sh

















 925
925

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









