






布隆过滤器
实际上是一个很长的二进制数组 + 一系列随机 hash 算法映射函数,主要用于判断一个元素是否在集合中。
但是随着集合中数据的增加,存储空间也会线性增长,最终到达瓶颈,且检索速度也越来越慢,布隆过滤器应运而生
特点:
- 插入和查询高效,占用空间少,返回结果不确定
- 一个元素如果判断为存在时元素不一定存在,如果判断为不存在则一定不存在
- 布隆过滤器可以添加元素,但是不能删除元素。因为删除元素会导致误判率增加
- 误判只会发生在过滤器没有添加过的元素,对于添加过的元素不会发生误判
使用场景
解决缓存穿透问题
一般情况下,先查询缓存redis是否有该条数据,缓存中没有时,再查询数据库。
当数据库也不存在该条数据时,每次查询都要访问数据库,这就是缓存穿透。
缓存穿透带来的问题是,当有大量请求查询数据库不存在的数据时,就会给数据库带来压力,甚至会拖垮数据库。
使用布隆过滤器解决缓存穿透的问题
把已存在数据的 key 存在布隆过滤器中,当有新的请求时,先到布隆过滤器中查询是否存在;
如果不存在则直接返回;如果存在才去 redis 中查询缓存,如果 redis 也没有则穿透到 MySQL数据库
黑名单校验
布隆过滤器原理
布隆过滤器是一种专门用来解决去重问题的高级数据结构
实质是一个大型位数组和几个不同的无偏 hash 函数 (无偏表示分布均匀)。 由一个初值都为 0 的 bit 数组和多个哈希函数构成,用来快速判断某个数据是否存在。但是跟 HyperLogLog,它也有一点不精确,也存在一定的误判概率
- 添加 key 时
使用多个 hash 函数对 key 进行 hash 运算得到一个整数索引值,对位数组长度进行取模运算得到一个位置,每个 hash 函数都会得到一个不同的位置,将这个位置都置 1 就完成了 add 操作
- 查询 key 时
只要有其中一位是 0 就表示这个 key 不存在,但如果都是 1,则不一定存在对应的 key
过程
当有变量被加入到集合时,通过 n个映射函数将这个变量映射成位图中的 n 个点,把他们置 1
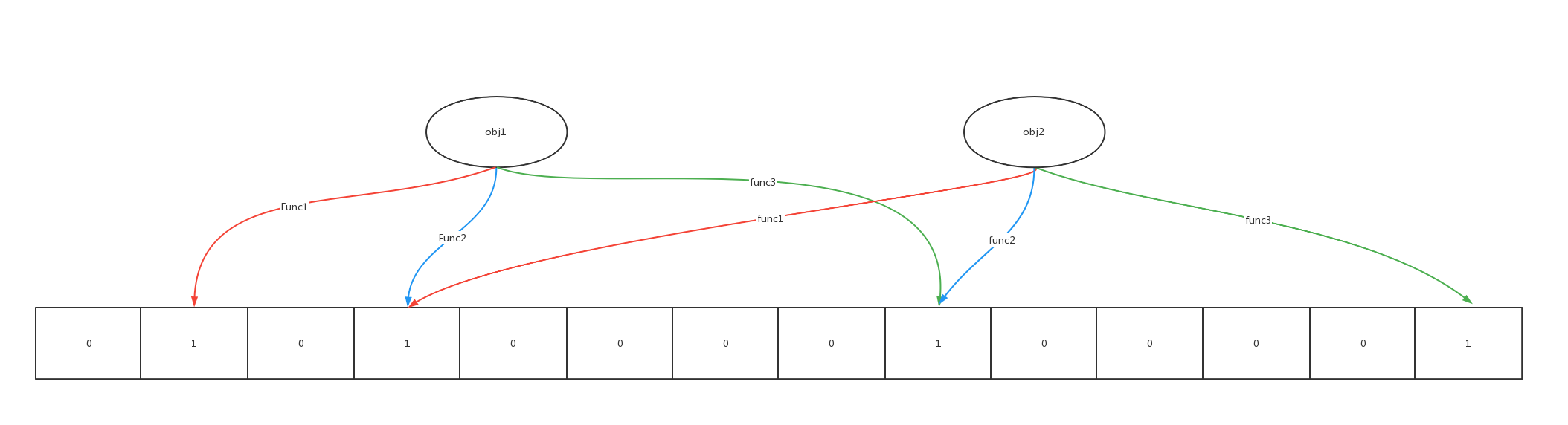
查询某个变量时,我们只需要看看这些点是不是都是1,就可以知道集合中有没有它
如果这些点中有一个为 0 则被查询变量一定不存在
如果都是1,则有可能存在
因为映射函数是散列函数,散列函数是会发生碰撞的
正是基于布隆过滤器的快速检测特性,我们可以在把数据写入数据库时,使用布隆过滤器做个标记。当缓存缺失后,应用查询数据库时,可以通过查询布隆过滤器快速判断数据是否存在。如果不存在,就不用再去数据库中查询了。这样一来,即使发生缓存穿透了,大量请求只会查询Redis和布隆过滤器,而不会积压到数据库,也就不会影响数据库的正常运行。布隆过滤器可以使用Redis实现,本身就能承担较大的并发访问压力。

















 651
651

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









