



 本文详细介绍如何在Linux环境下使用虚拟机安装配置Hadoop伪分布式环境,包括虚拟机及Linux系统安装、Java环境搭建、Hadoop安装配置、环境变量设置、配置文件修改、SSH免密码登录、系统格式化及启动等步骤。
本文详细介绍如何在Linux环境下使用虚拟机安装配置Hadoop伪分布式环境,包括虚拟机及Linux系统安装、Java环境搭建、Hadoop安装配置、环境变量设置、配置文件修改、SSH免密码登录、系统格式化及启动等步骤。
一、 准备工作
1、安装虚拟机
(1)打开安装向导;

(2)、接受许可协议,点击下一步;

(3)选择典型安装;

(4)更改安装路径;

(5)等待安装完成。

2、 安装Linux操作系统
(1)打开新建虚拟机向导,选择典型,点击下一步;

(2)更改安装路径;

(3)填写安装信息;

(4)将网络适配器更改为桥接模式;

3、 登录Linux操作系统进行相关配置
(1)查看文件夹结构

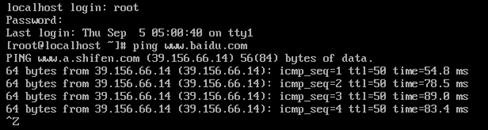
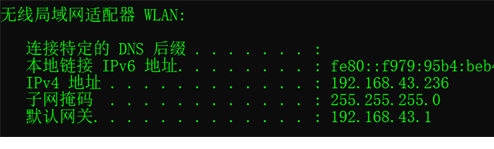
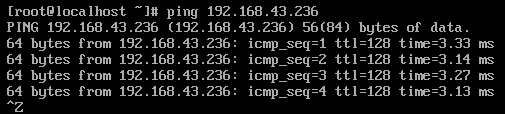
(2)、测试网络环境
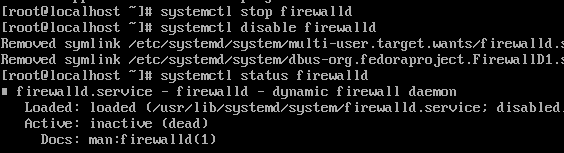
(3)关闭防火墙
a、关闭并查看firewalld防火墙
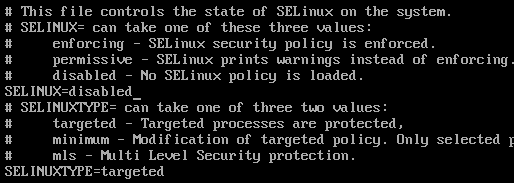
b、关闭selinux防火墙

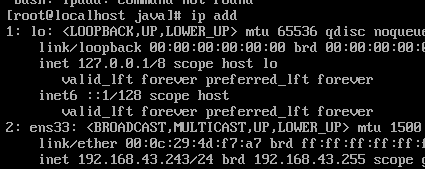
(4)查询固定CentOS虚拟机ip(192.168.43.243)


(5)修改主机名

(6)配置主机名和ip地址映射关系


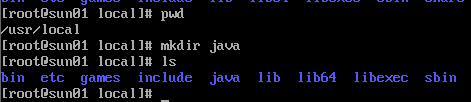
(7)在/usr/local目录下新建java文件夹
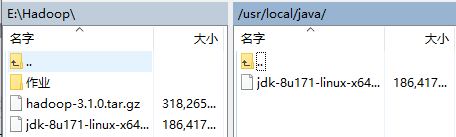
(8)下载linux版本jdk并上传至服务器
(9)解压jdk


(10)配置java环境变量

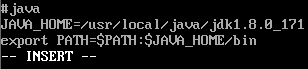
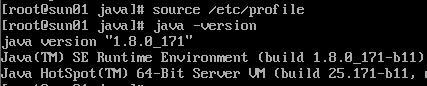
(11)使设置的环境变量生效
二、 Hadoop伪分布式环境的搭建
1、 安装Hadoop
(1) 新建sun文件夹
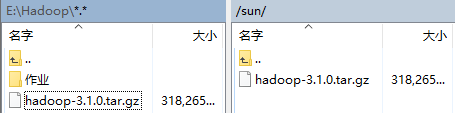
(2) 下载Hadoop压缩包并上传至服务器
(3) 解压安装Haddoop
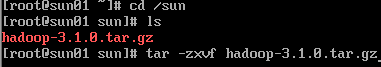

2、 环境变量
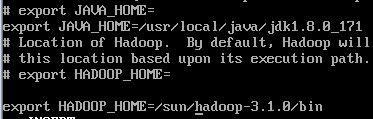
(1)配置Hadoop环境变量


(2)应用环境变量配置文件更新

3、修改配置文件
进入$HADOOP_HOME/etc/hadoop/目录

(1)hadoop.env.sh运行环境配置文件

(2)core-site.xml核心配置文件


(3)hdfs–site.xml核心配置文件


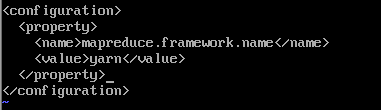
(4)mapred-site.xml配置

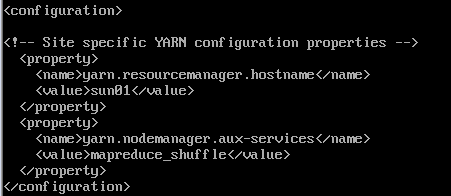
(5) yarn-site.xml配置

4、格式化系统


5、启动start-dfs.sh、start-yarn.sh时报错,


6、在sbin目录下vi start-dfs.sh、vi stop-dfs.sh、vi start-yarn.sh、vi stop-yarn.sh加入
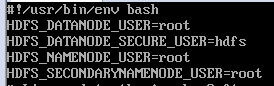
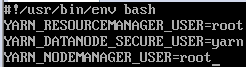
7、配置SSH免密码登录
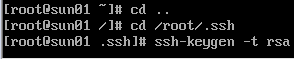


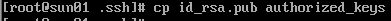
8、启动Hadoop
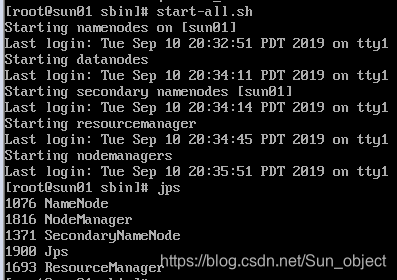
三、 Hadoop测试
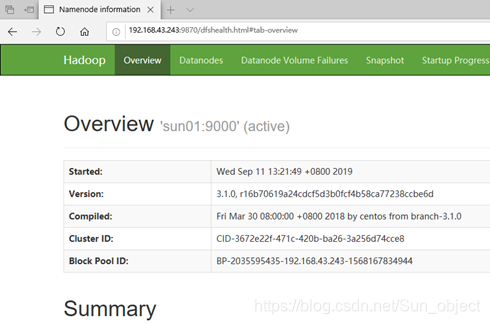
(1)通过http://192.168.43.243:9870访问Hadoop管理界面
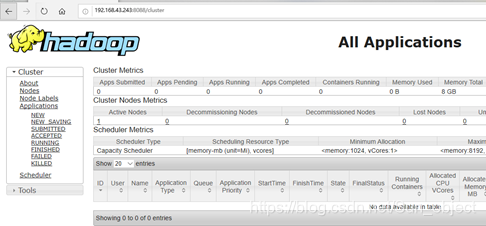
(2)通过http://192.168.43.243:8088访问MapReduce管理界面

















 1566
1566

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









