







1、前后端过程
前端知识:HTML、CSS、JS、Jquery等
后端知识:多任务、网络编程及python高级语法
1,用户通过浏览器先访问前端页面(web服务器静态资源)–获得排版信息
2,想看到商品详细信息,需要访问另一台服务器(web服务器动态资源),看到的信息来自数据库
两个服务器的请求才能让我们看到完整的信息页面
ETL数据仓库:用来记录用户的行为(点击行为,访问行为等)存储页面上的id编号–用来分析用户感兴趣的方面
数据分析 – 从数仓中取数据,做用户画像
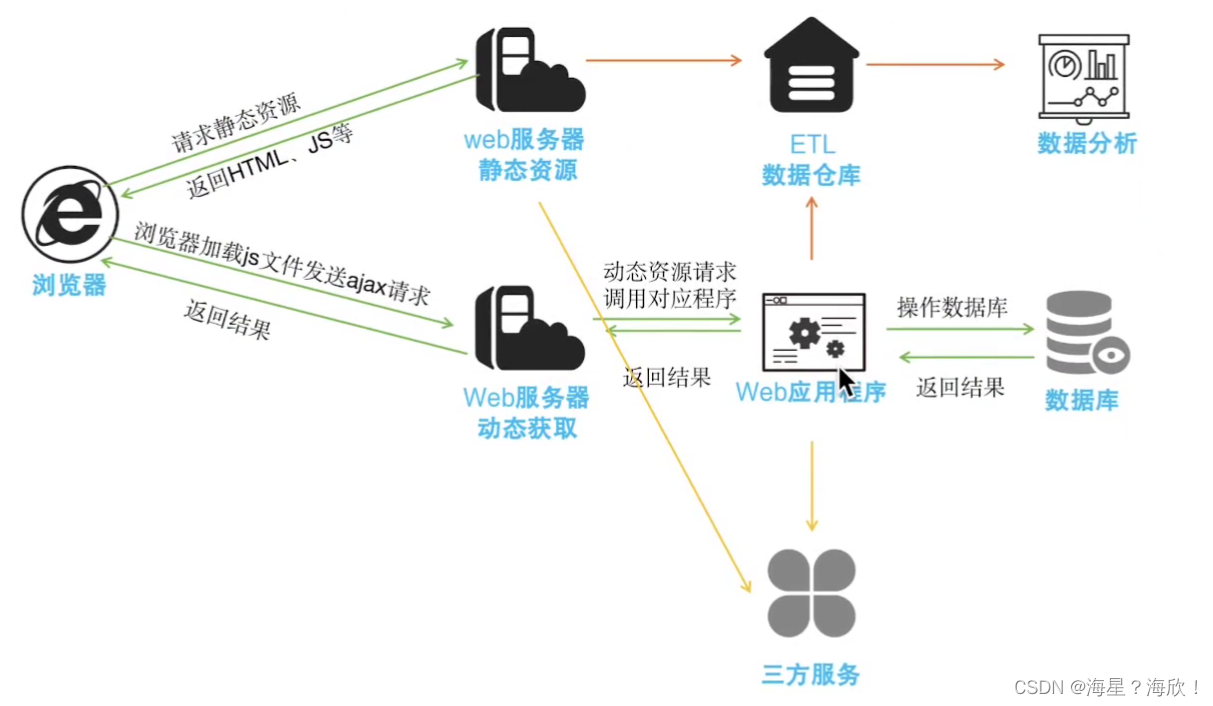
python是后端开发语言。例如我们登录账号----就是发送的后端请求,python定义一个函数来判断
2、多任务介绍
登录场景中,100个,登录函数只有一个,如何同时处理100个??
—多任务编程
多个线程或多个进程来解决
多任务指同一时间执行多个任务,例如同时运行多个软件(QQ,微信等同时运行)
多任务最大好处:充分利用CPU资源,提高程序的执行效率
3、多任务形式
两种:并行or并发
所有程序运行都需要CPU进行处理
单核CPU需要同时运行下面四个程序:
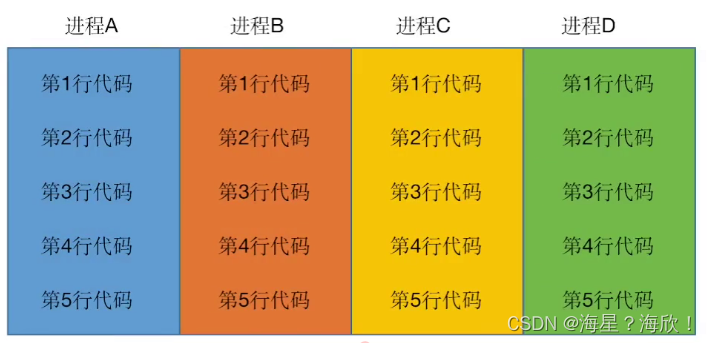
并发:交替运行,因为交替的时间很短,感知不到切换(针对单核CPU)
运行进程A的前两行代码 – 进程C的前两行代码 – 进程B前两行 – 进程C的后两行代码 -。。。直到运行完
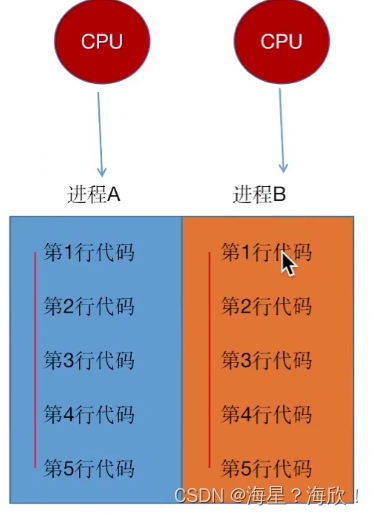
并行:针对多核CPU,给每个CPU安排一个执行的软件,多个内核并行才是真正的一起执行软件
但当程序超过CPU数量,还是会转化为并发
4、进程
进程是实现多任务的一种方式
多同一份代码,创建多个进程,就可以实现执行多次代码
一个正在运行的程序或者软件就是一个进程,它是操作系统进行资源分配的基础单位。没启动一个进程,操作系统会分配一定的运行资源保证进程的运行
栗子:公司可以理解为一个进程,公司提高办公资源,干活的员工可以理解为线程
一个程序运行后至少有一个进程,一个进程默认有一个线程,也可以创建多个线程,线程依附于进程里面,没有进程就没有线程
将进程复制三份,则,下面四个进程都是运行一样的代码。即这样就把同一份代码运行了4次,即解决了四个人同时登录的问题。100个人同时登录就复制100份
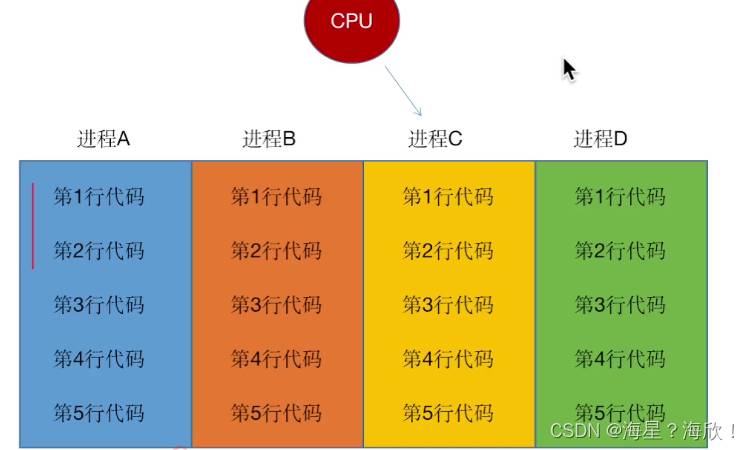
创建程序,就会分配空间,复制的时候也会重新分配空间
进程是python程序实现多任务的一种方式。方式:想要代码多次执行 – 将代码多次复制
5、多进程的使用
5.1 案例
def login():
print('登录')
if __name__ =='__main__':
login()
login()
login()
#这是多次函数的调用,一次进程里面多次调用方法
#导入多进程模块
import multiprocessing
def login():
print('登录')
if __name__ =='__main__':
login()
login()
#P大写
p1 = multiprocessing.Process(target = login) #创建一个进程
#括号里面一些参数group = None指定分组,target =None指定调用函数名
#运行进程指定对应函数业务逻辑
p1.start()
#p2 = multiprocessing.Process(target = login)
#p2.start() 多次

输出三个;两个login()+多任务p1.start()
多次调用的时间效率要比多进程低
两个login():

在一个进程里面,在多并发时是会跳转,所以损坏时间更多
p1.start()+p2.start():
两个程序代码,效率更高
多进程使用时注意:
- multiprocessing.Process中P大写
- multiprocessing.Process要写在if name ==‘main’:下
5.2 加参数
传参的两种方式:args 与kwargs
import multiprocessing
def login(name,password):
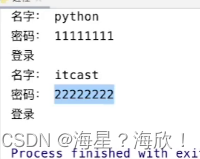
print('名字:',name)
print('密码:',password)
print('登录')
if __name__ =='__main__':
login()
login()
#P大写
p1 = multiprocessing.Process(target = login,args=('python','1111111')) #创建一个进程
#括号里面一些参数group = None指定分组,target =None指定调用函数名
#args=(),kwargs={}给函数传递参数
p1.start()
p2 = multiprocessing.Process(target = login,kwargs={'name':'itcast','passsword':'22222222'})
p2.start()
5.3 指定进程名称
import multiprocessing
def login(name,password):
print('名字:',name)
print('密码:',password)
print('登录')
#获取进程名称
print('进程名称:',multiprocessing.current_process().name)
if __name__ =='__main__':
login()
login()
#P大写
p1 = multiprocessing.Process(target = login,args=('python','1111111')name='p1') #创建一个进程
#括号里面一些参数group = None指定分组,target =None指定调用函数名
#args=(),kwargs={}给函数传递参数
p1.start()
p2 = multiprocessing.Process(target = login,kwargs={'name':'itcast','passsword':'22222222'},name='p2')
p2.start()

下一次可能先p2再p1,是cpu根据算法随机的,非固定
如果想要安装顺序运行?
需要用到进程等待,一个用完后再另一个
这样就不是并行并发了,通常我们都想要效率高–会用到并行并发
import multiprocessing
def login(name,password):
print('名字:',name)
print('密码:',password)
print('登录')
#获取进程名称
print('进程名称:',multiprocessing.current_process().name)
if __name__ =='__main__':
login()
login()
#P大写
p1 = multiprocessing.Process(target = login,args=('python','1111111')name='p1') #创建一个进程
#括号里面一些参数group = None指定分组,target =None指定调用函数名
#args=(),kwargs={}给函数传递参数
p2 = multiprocessing.Process(target = login,kwargs={'name':'itcast','passsword':'22222222'},name='p2')
p1.start()
p1.join()
p2.start()
p2.join()
#p1执行完后再p2
5.4 获取进程编号
当前文件–主进程,文件运行过程中产生的进程–子进程
os.getpid() --进程编号
os.getppid()–进程的父进程编号
import multiprocessing
import os
def login(name,password):
print('名字:',name)
print('密码:',password)
print('登录')
#获取进程名称
print('进程名称:',multiprocessing.current_process().name)
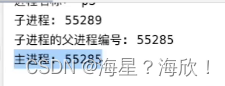
print('子进程:',os.getpid())
print('子进程的父进程:',os.getppid())
if __name__ =='__main__':
login()
login()
#P大写
p1 = multiprocessing.Process(target = login,args=('python','1111111')name='p1') #创建一个进程
#括号里面一些参数group = None指定分组,target =None指定调用函数名
#args=(),kwargs={}给函数传递参数
p2 = multiprocessing.Process(target = login,kwargs={'name':'itcast','passsword':'22222222'},name='p2')
p1.start()
p1.join()
p2.start()
p2.join()
#p1执行完后再p2
#获取当前进程
print('主进程:',os.getpid())

不同子进程对应不同编号
5.5 注意点
- 主进程需要在所有子进程全部执行完后才开始执行
- 进程之间不共享全局变量


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









