







1、背景介绍
目标:将根据用户产生的数据对课程潜在的会员用户(可能产生购买会员的行为)进行预测。
平台的一位注册用户是否购买会员的行为应该是建立在一定背景条件下。相信很少有用户刚刚完成注册不久,就直接购买会员。
一般来讲,促使付费行为发生的原因,往往都建立在用户的活跃度之上。
数据
!wget -nc “http://labfile.oss.aliyuncs.com/courses/764/data_10.zip”
!unzip -o “data_10.zip”
训练数据集包含有 8 个特征项,以及用户是否为会员的标签,数据共计 40000 条。
最后一项会员标签,通过布尔值进行标识。True 当前用户是会员身份,False 代表当前用户不是会员身份。
import pandas as pd
pd.read_excel("user_fit.xlsx").head()
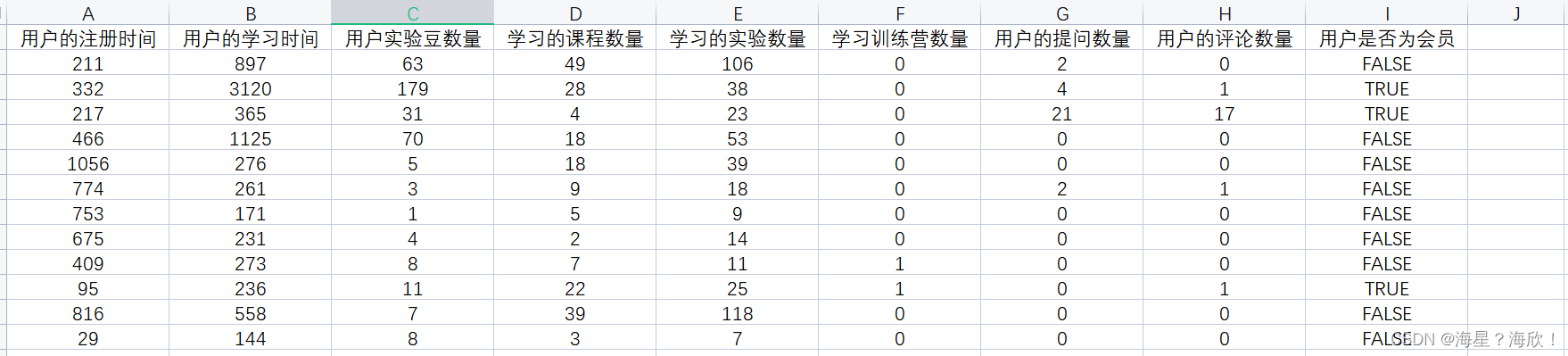
测试数据集包含 10000 条数据,且数据特征项与训练数据集完全一致。唯一不同的地方在于,训练数据集中既有会员数据也有非会员数据,而测试数据集中全部都为非会员用户。
pd.read_excel("user_prediction.xlsx").head()
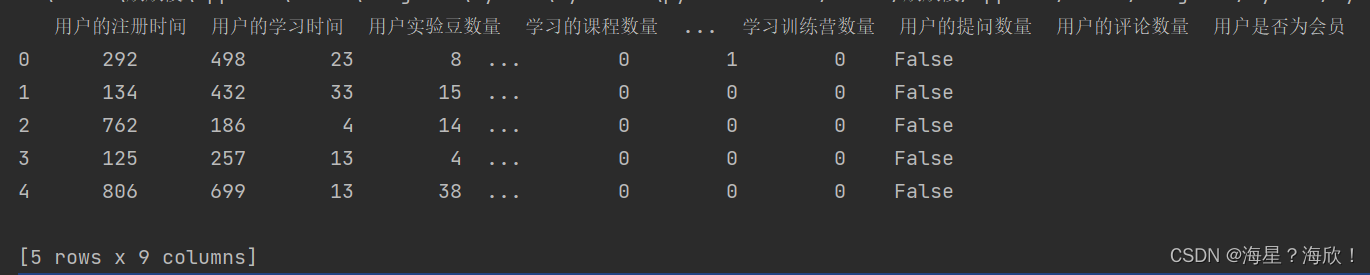
**目标:**预测测试集中这些用户哪些是潜在用户,很可能购买会员的
这些数据已经是处理好的,没有缺失值的数据
2、朴素贝叶斯
2.1 模型介绍
朴素贝叶斯是一种可用于构建分类模型的方法,他是假设特征相互独立的情况下,运用贝叶斯定理进行后验概率计算的简单分类器。
贝叶斯公式:

数据集拥有 8 个特征值,分别为:用户的注册时间、用户的学习时间 用户实验豆数量、学习的课程数量、学习的实验数量、学习训练营数量 用户的提问数量、用户的评论数量。这些特征之间是相互独立的。
而这些特征可能会对最后的目标参数,也就是该用户是否为会员造成影响。也就是说,如果我们现在有一个会员的数据,我们知道他的 8 个特征取值,最后想了解他成为会员的概率有多大?
根据贝叶斯定理,且特征之间相互独立,得到:

像 P(用户的注册时间)P(用户的注册时间) 这样的概率怎样求解呢?由于我们这里是连续变量,一般会针对其进行离散化处理,也就是通过假定一个区间,计算变量落在该区间内的概率。
最后,我们就可以计算出该用户是会员和不是会员的概率,通过比较得出分类属性。
2.2 模型实现
直接使用 scikit-learn 提供的贝叶斯算法来构建模型
scikit-learn 针对朴素贝叶斯提供了三种分类器,分别是:
- 高斯分布朴素贝叶斯分类器 naive_bayes.GaussianNB
- 多项式分布朴素贝叶斯分类器 naive_bayes.MultinomialNB
- 伯努利分布朴素贝叶斯分类器 naive_bayes.BernoulliNB
其中,高斯分布模型常用于特征值为连续型变量的数据集中,例如本实验中的数据集。高斯模型的特点在于它通常假设是这些连续数值为高斯分布,相比于直接把连续变量离散化的方法更优。
伯努利模型常用处理特征变量为布尔值类型的数据集,
多项式模型常用于文本分类。
尝试使用高斯分布朴素贝叶斯针对 user_fit.xlsx 数据集构建一个分类模型:
from sklearn.model_selection impor 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









