





 提出一种新的层次匹配算法,能同时建模句子内部结构和句子间交互信息,通过逐层构图和合并表达句子层次,捕捉丰富匹配模式。无需先验知识,具有通用性。基于CNN的句子建模和两种匹配结构,实验表明结构2优于结构1。
提出一种新的层次匹配算法,能同时建模句子内部结构和句子间交互信息,通过逐层构图和合并表达句子层次,捕捉丰富匹配模式。无需先验知识,具有通用性。基于CNN的句子建模和两种匹配结构,实验表明结构2优于结构1。
- 发表时间:2015年
- 论文链接:https://arxiv.org/abs/1503.03244v1
- 代码链接:http://nlp.stanford.edu/˜socherr/classifyParaphrases.zip
- 代码语言:matlab
摘要
较好的匹配算法能够同时为句子内部结构和句子间的交互信息建模。本文提出的模型通过逐层构图和合并充分表达句子的层次信息,而且能够在不同的层次捕捉到丰富的匹配模式。该算法无需先验知识,而且具有通用性。
句子建模
句子匹配任务的核心是能够充分地为句子建模(即提取sentence-level的特征),本文基于CNN为句子建模,结构如图1所示:
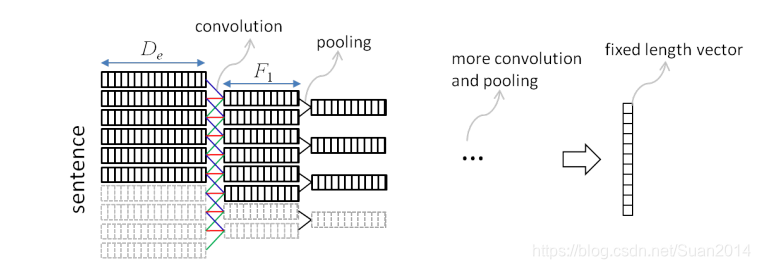
这样为什么有效呢?
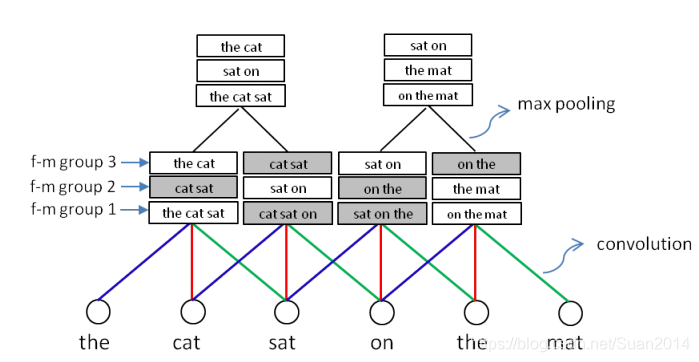
如图2所示,采用卷积能够从句子中提取出局部的语义组合,如图2中的 the cat sat和cat sat on等这样的短语组合。卷积多个filter能够提取多个feature map,这样就能够从多个角度提取语义组合,如图2中的第一个滑动窗涵盖的feature map1 是the cat sat的特征,feature map2 为cat sat的特征,feature map3为the cat的特征。 采用max pooling层会对多种语义组合进行选择,过滤掉一些置信度低的特征组合,图2中亮的表示特征值较大。
匹配模型
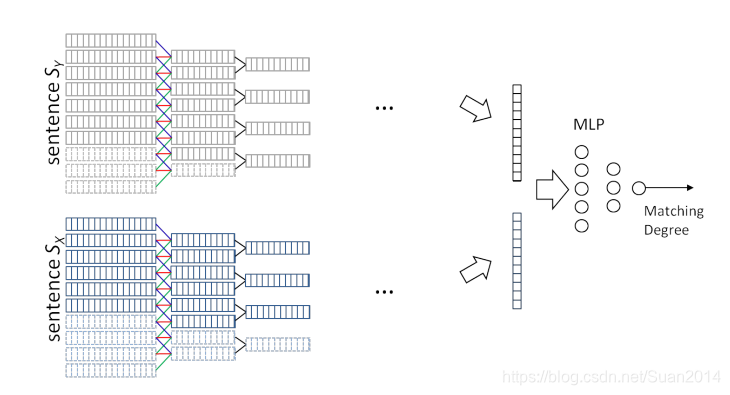
句子建模后能够提取出一个句子的特征向量,接下来需要利用特征向量对句子对进行匹配建模。
结构1
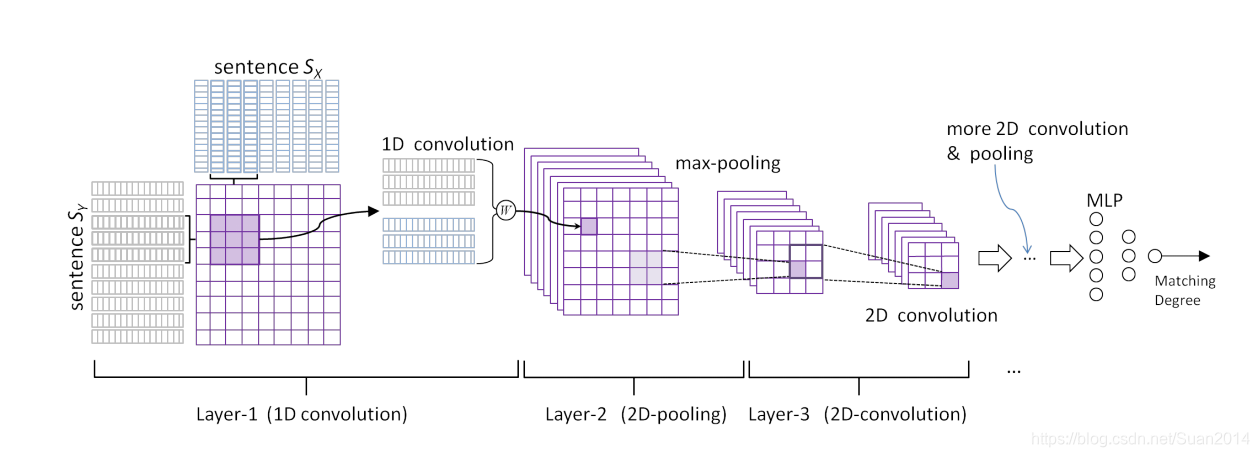
结构2
为了解决结构1的问题,提出了结构2,如图
训练
- loss函数:排序损失函数(ranking-based loss):
e(x,y+,y−)=max(0,1+s(x,y−)−s(x,y+))e(x,y^+,y^-) = max(0, 1+s(x,y^-)-s(x,y+))e(x,y+,y−)=max(0,1+s(x,y−)−s(x,y+))
所表达的意思是,句子x与与其匹配的句子间的相似度得分要高于与其不匹配的句子间相似度得分。 - batch_szie: 100~200
- word embedding维度:50,算法Word2Vec
- 数据:英文数据:Wikipedia(~1B Words) 中文:微博数据(~300M Words)
实验
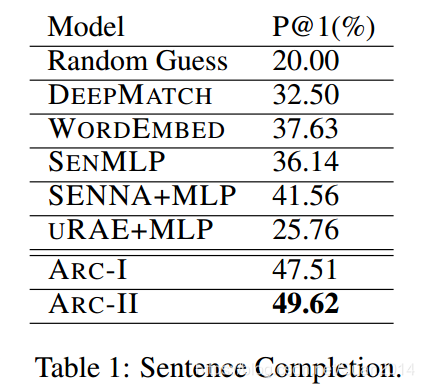
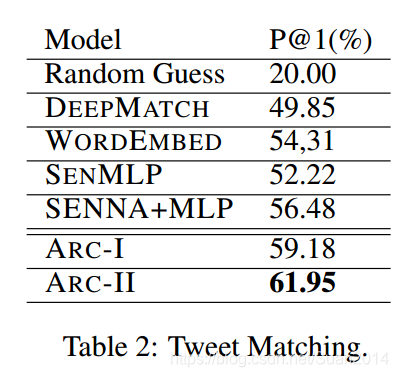
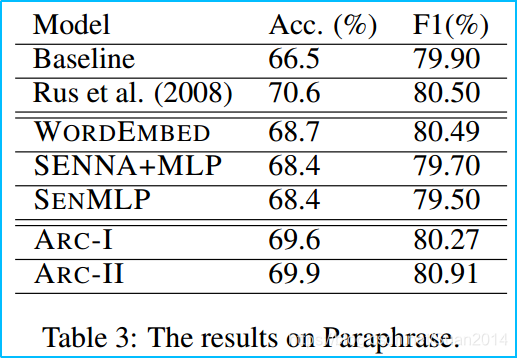
- 三个匹配任务:句子自动填充、推文匹配、同义词匹配
- 效果:结构1和结构2远好于其他算法,结构2稍好于结构1


















 977
977

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











